AI Workflow
DALL·E 3 Prompt: Create a rectangular illustration of a stylized flowchart representing the AI workflow/pipeline. From left to right, depict the stages as follows: ‘Data Collection’ with a database icon, ‘Data Preprocessing’ with a filter icon, ‘Model Design’ with a brain icon, ‘Training’ with a weight icon, ‘Evaluation’ with a checkmark, and ‘Deployment’ with a rocket. Connect each stage with arrows to guide the viewer horizontally through the AI processes, emphasizing these steps’ sequential and interconnected nature.

Purpose
What are the diverse elements of AI systems and how do we combine to create effective machine learning system solutions?
The creation of practical AI solutions requires the orchestration of multiple components into coherent workflows. Workflow design highlights the connections and interactions that animate these components. This systematic perspective reveals how data flow, model training, and deployment considerations are intertwined to form robust AI systems. Analyzing these interconnections offers important insights into system-level design choices, establishing a framework for understanding how theoretical concepts can be translated into deployable solutions that meet real-world needs.
Understand the ML lifecycle and gain insights into the structured approach and stages of developing, deploying, and maintaining machine learning models.
Identify the unique challenges and distinctions between lifecycles for traditional machine learning and specialized applications.
Explore the various people and roles involved in ML projects.
Examine the importance of system-level considerations, including resource constraints, infrastructure, and deployment environments.
Appreciate the iterative nature of ML lifecycles and how feedback loops drive continuous improvement in real-world applications.
Overview
The machine learning lifecycle is a systematic, interconnected process that guides the transformation of raw data into actionable models deployed in real-world applications. Each stage builds upon the outcomes of the previous one, creating an iterative cycle of refinement and improvement that supports robust, scalable, and reliable systems.
Figure 1 illustrates the lifecycle as a series of stages connected through continuous feedback loops. The process begins with data collection, which ensures a steady input of raw data from various sources. The collected data progresses to data ingestion, where it is prepared for downstream machine learning applications. Subsequently, data analysis and curation involve inspecting and selecting the most appropriate data for the task at hand. Following this, data labeling and data validation, which nowadays involves both humans and AI itself, ensure that the data is properly annotated and verified for usability before advancing further.

The data then enters the preparation stage, where it is transformed into machine learning-ready datasets through processes such as splitting and versioning. These datasets are used in the model training stage, where machine learning algorithms are applied to create predictive models. The resulting models are rigorously tested in the model evaluation stage, where performance metrics, such as key performance indicators (KPIs), are computed to assess reliability and effectiveness. The validated models move to the ML system validation phase, where they are verified for deployment readiness. Once validated, these models are integrated into production systems during the ML system deployment stage, ensuring alignment with operational requirements. The final stage tracks the performance of deployed systems in real time, enabling continuous adaptation to new data and evolving conditions.
This general lifecycle forms the backbone of machine learning systems, with each stage contributing to the creation, validation, and maintenance of scalable and efficient solutions. While the lifecycle provides a detailed view of the interconnected processes in machine learning systems, it can be distilled into a simplified framework for practical implementation.
Each stage aligns with one of the following overarching categories:
Data Collection and Preparation ensures the availability of high-quality, representative datasets.
Model Development and Training focuses on creating accurate and efficient models tailored to the problem at hand.
Evaluation and Validation rigorously tests models to ensure reliability and robustness in real-world conditions.
Deployment and Integration translates models into production-ready systems that align with operational realities.
Monitoring and Maintenance ensures ongoing system performance and adaptability in dynamic environments.
A defining feature of this framework is its iterative and dynamic nature. Feedback loops, such as those derived from monitoring that guide data collection improvements or deployment adjustments, ensure that machine learning systems maintain effectiveness and relevance over time. This adaptability is critical for addressing challenges such as shifting data distributions, operational constraints, and evolving user requirements.
By studying this framework, we establish a solid foundation for exploring specialized topics such as data engineering, model optimization, and deployment strategies in subsequent chapters. Viewing the ML lifecycle as an integrated and iterative process promotes a deeper understanding of how systems are designed, implemented, and maintained over time. To that end, this chapter focuses on the machine learning lifecycle as a systems-level framework, providing a high-level overview that bridges theoretical concepts with practical implementation. Through an examination of the lifecycle in its entirety, we gain insight into the interdependencies among its stages and the iterative processes that ensure long-term system scalability and relevance.
Definition
The machine learning (ML) lifecycle is a structured, iterative process that guides the development, evaluation, and continual improvement of machine learning systems. Integrating ML into broader software engineering practices introduces unique challenges that necessitate systematic approaches to experimentation, evaluation, and adaptation over time (Amershi et al. 2019).
The Machine Learning (ML) Lifecycle is a structured, iterative process that defines the key stages involved in the development, deployment, and refinement of ML systems. It encompasses interconnected steps such as problem formulation, data collection, model training, evaluation, deployment, and monitoring. The lifecycle emphasizes feedback loops and continuous improvement, ensuring that systems remain robust, scalable, and responsive to changing requirements and real-world conditions.
Rather than prescribing a fixed methodology, the ML lifecycle focuses on achieving specific objectives at each stage. This flexibility allows practitioners to adapt the process to the unique constraints and goals of individual projects. Typical stages include problem formulation, data acquisition and preprocessing, model development and training, evaluation, deployment, and ongoing optimization.
Although these stages may appear sequential, they are frequently revisited, creating a dynamic and interconnected process. The iterative nature of the lifecycle encourages feedback loops, whereby insights from later stages, including deployment, can inform earlier phases, including data preparation or model architecture design. This adaptability is essential for managing the uncertainties and complexities inherent in real-world ML applications.
From an instructional standpoint, the ML lifecycle provides a clear framework for organizing the study of machine learning systems. By decomposing the field into well-defined stages, students can engage more systematically with its core components. This structure mirrors industrial practice while supporting deeper conceptual understanding.
It is important to distinguish between the ML lifecycle and machine learning operations (MLOps), as the two are often conflated. The ML lifecycle, as presented in this chapter, emphasizes the stages and evolution of ML systems—the “what” and “why” of system development. In contrast, MLOps, which will be discussed in the MLOps Chapter, addresses the “how,” focusing on tools, processes, and automation that support efficient implementation and maintenance. Introducing the lifecycle first provides a conceptual foundation for understanding the operational aspects that follow.
Traditional vs. AI Lifecycles
Software development lifecycles have evolved through decades of engineering practice, establishing well-defined patterns for system development. Traditional lifecycles consist of sequential phases: requirements gathering, system design, implementation, testing, and deployment. Each phase produces specific artifacts that serve as inputs to subsequent phases. In financial software development, for instance, the requirements phase produces detailed specifications for transaction processing, security protocols, and regulatory compliance—specifications that directly translate into system behavior through explicit programming.
Machine learning systems require a fundamentally different approach to this traditional lifecycle model. The deterministic nature of conventional software, where behavior is explicitly programmed, contrasts sharply with the probabilistic nature of ML systems. Consider financial transaction processing: traditional systems follow predetermined rules (if account balance > transaction amount, then allow transaction), while ML-based fraud detection systems learn to recognize suspicious patterns from historical transaction data. This shift from explicit programming to learned behavior fundamentally reshapes the development lifecycle.
The unique characteristics of machine learning systems, characterized by data dependency, probabilistic outputs, and evolving performance, introduce new dynamics that alter how lifecycle stages interact. These systems require ongoing refinement, with insights from later stages frequently feeding back into earlier ones. Unlike traditional systems, where lifecycle stages aim to produce stable outputs, machine learning systems are inherently dynamic and must adapt to changing data distributions and objectives.
The key distinctions are summarized in Table 1 below:
| Aspect | Traditional Software Lifecycles | Machine Learning Lifecycles |
|---|---|---|
| Problem Definition | Precise functional specifications are defined upfront. | Performance-driven objectives evolve as the problem space is explored. |
| Development Process | Linear progression of feature implementation. | Iterative experimentation with data, features and models. |
| Testing and Validation | Deterministic, binary pass/fail testing criteria. | Statistical validation and metrics that involve uncertainty. |
| Deployment | Behavior remains static until explicitly updated. | Performance may change over time due to shifts in data distributions. |
| Maintenance | Maintenance involves modifying code to address bugs or add features. | Continuous monitoring, updating data pipelines, retraining models, and adapting to new data distributions. |
| Feedback Loops | Minimal; later stages rarely impact earlier phases. | Frequent; insights from deployment and monitoring often refine earlier stages like data preparation and model design. |
These differences underline the need for a robust ML lifecycle framework that can accommodate iterative development, dynamic behavior, and data-driven decision-making. This lifecycle ensures that machine learning systems remain effective not only at launch but throughout their operational lifespan, even as environments evolve.
Lifecycle Stages
The AI lifecycle consists of several interconnected stages, each essential to the development and maintenance of effective machine learning systems. While the specific implementation details may vary across projects and organizations, Figure 2 provides a high-level illustration of the ML system development lifecycle. This chapter focuses on the overview, with subsequent chapters diving into the implementation aspects of each stage.

Problem Definition and Requirements: The first stage involves clearly defining the problem to be solved, establishing measurable performance objectives, and identifying key constraints. Precise problem definition ensures alignment between the system’s goals and the desired outcomes.
Data Collection and Preparation: This stage includes gathering relevant data, cleaning it, and preparing it for model training. This process often involves curating diverse datasets, ensuring high-quality labeling, and developing preprocessing pipelines to address variations in the data.
Model Development and Training: In this stage, researchers select appropriate algorithms, design model architectures, and train models using the prepared data. Success depends on choosing techniques suited to the problem and iterating on the model design for optimal performance.
Evaluation and Validation: Evaluation involves rigorously testing the model’s performance against predefined metrics and validating its behavior in different scenarios. This stage ensures the model is not only accurate but also reliable and robust in real-world conditions.
Deployment and Integration: Once validated, the trained model is integrated into production systems and workflows. This stage requires addressing practical challenges such as system compatibility, scalability, and operational constraints.
Monitoring and Maintenance: The final stage focuses on continuously monitoring the system’s performance in real-world environments and maintaining or updating it as necessary. Effective monitoring ensures the system remains relevant and accurate over time, adapting to changes in data, requirements, or external conditions.
A Case Study in Medical AI: To further ground our discussion on these stages, we will explore Google’s Diabetic Retinopathy (DR) screening project as a case study. This project exemplifies the transformative potential of machine learning in medical imaging analysis, an area where the synergy between algorithmic innovation and robust systems engineering plays a pivotal role. Building upon the foundational work by Gulshan et al. (2016), which demonstrated the effectiveness of deep learning algorithms in detecting diabetic retinopathy from retinal fundus photographs, the project progressed from research to real-world deployment, revealing the complex challenges that characterize modern ML systems.
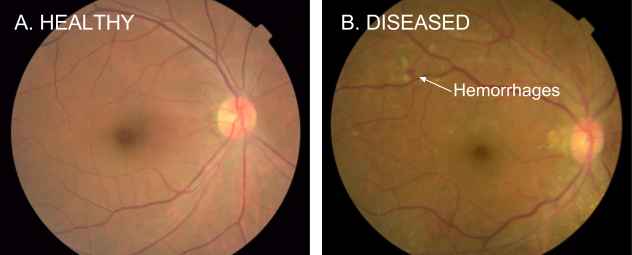
Diabetic retinopathy, a leading cause of preventable blindness worldwide, can be detected through regular screening of retinal photographs. Figure 3 illustrates examples of such images: (A) a healthy retina and (B) a retina with diabetic retinopathy, marked by hemorrhages (red spots). The goal is to train a model to detect the hemorrhages.
On the surface, the goal appears straightforward: develop an AI system that could analyze retinal images and identify signs of DR with accuracy comparable to expert ophthalmologists. However, as the project progressed from research to real-world deployment, it revealed the complex challenges that characterize modern ML systems.
The initial results in controlled settings were promising. The system achieved performance comparable to expert ophthalmologists in detecting DR from high-quality retinal photographs. Yet, when the team attempted to deploy the system in rural clinics across Thailand and India, they encountered a series of challenges that spanned the entire ML lifecycle, from data collection through deployment and maintenance.
This case study will serve as a recurring thread throughout this chapter to illustrate how success in machine learning systems depends on more than just model accuracy. It requires careful orchestration of data pipelines, training infrastructure, deployment systems, and monitoring frameworks. Furthermore, the project highlights the iterative nature of ML system development, where real-world deployment often necessitates revisiting and refining earlier stages.
While this narrative is inspired by Google’s documented experiences in Thailand and India, certain aspects have been embellished to emphasize specific challenges frequently encountered in real-world healthcare ML deployments. These enhancements are to provide a richer understanding of the complexities involved while maintaining credibility and relevance to practical applications.
Problem Definition
The development of machine learning systems begins with a critical challenge that fundamentally differs from traditional software development: defining not just what the system should do, but how it should learn to do it. Unlike conventional software, where requirements directly translate into implementation rules, ML systems require teams to consider how the system will learn from data while operating within real-world constraints. This stage lays the foundation for all subsequent phases in the ML lifecycle.
In our case study, diabetic retinopathy is a problem that blends technical complexity with global healthcare implications. With 415 million diabetic patients at risk of blindness worldwide and limited access to specialists in underserved regions, defining the problem required balancing technical goals, such as expert-level diagnostic accuracy, with practical constraints. The system needed to prioritize cases for early intervention while operating effectively in resource-limited settings. These constraints showcased how problem definition must integrate learning capabilities with operational needs to deliver actionable and sustainable solutions.
Requirements and System Impact
Defining an ML problem involves more than specifying desired performance metrics. It requires a deep understanding of the broader context in which the system will operate. For instance, developing a system to detect DR with expert-level accuracy might initially appear to be a straightforward classification task. After all, one might assume that training a model on a sufficiently large dataset of labeled retinal images and evaluating its performance against standard metrics would suffice.
However, real-world challenges complicate this picture. ML systems must function effectively in diverse environments, where factors like computational constraints, data variability, and integration requirements play significant roles. For example, the DR system needed to detect subtle features like microaneurysms1, hemorrhages2, and hard exudates3 across retinal images of varying quality while operating within the limitations of hardware in rural clinics. A model that performs well in isolation may falter if it cannot handle operational realities, such as inconsistent imaging conditions or time-sensitive clinical workflows. Addressing these factors requires aligning learning objectives with system constraints, ensuring the system’s long-term viability in its intended context.
1 Microaneurysms: Small bulges in blood vessels of the retina commonly seen in diabetic retinopathy.
2 Hemorrhages: Blood that has leaked from the blood vessels into the surrounding tissues.
3 Hard Exudates: Deposits of lipids or fats indicative of leakage from impaired retinal blood vessels.
Definition Workflow
Establishing clear and actionable problem definitions involves a multi-step workflow that bridges technical, operational, and user considerations. The process begins with identifying the core objective of the system—what tasks it must perform and what constraints it must satisfy. Teams collaborate with stakeholders to gather domain knowledge, outline requirements, and anticipate challenges that may arise in real-world deployment.
In the DR project, this phase involved close collaboration with clinicians to determine the diagnostic needs of rural clinics. Key decisions, such as balancing model complexity with hardware limitations and ensuring interpretability for healthcare providers, were made during this phase. The team’s iterative approach also accounted for regulatory considerations, such as patient privacy and compliance with healthcare standards. This collaborative process ensured that the problem definition aligned with both technical feasibility and clinical relevance.
Scale and Distribution
As ML systems scale, their problem definitions must adapt to new operational challenges. For example, the DR project initially focused on a limited number of clinics with consistent imaging setups. However, as the system expanded to include clinics with varying equipment, staff expertise, and patient demographics, the original problem definition required adjustments to accommodate these variations.
Scaling also introduces data challenges. Larger datasets may include more diverse edge cases, which can expose weaknesses in the initial model design. In the DR project, for instance, expanding the deployment to new regions introduced variations in imaging equipment and patient populations that required further tuning of the system. Defining a problem that accommodates such diversity from the outset ensures the system can handle future expansion without requiring a complete redesign.
Systems Thinking
Problem definition, viewed through a systems lens, connects deeply with every stage of the ML lifecycle. Choices made during this phase shape how data is collected, how models are developed, and how systems are deployed and maintained. A poorly defined problem can lead to inefficiencies or failures in later stages, emphasizing the need for a holistic perspective.
Feedback loops are central to effective problem definition. As the system evolves, real-world feedback from deployment and monitoring often reveals new constraints or requirements that necessitate revisiting the problem definition. For example, feedback from clinicians about system usability or patient outcomes may guide refinements in the original goals. In the DR project, the need for interpretable outputs that clinicians could trust and act upon influenced both model development and deployment strategies.
Emergent behaviors4 also play a role. A system that was initially designed to detect retinopathy might reveal additional use cases, such as identifying other conditions like diabetic macular edema, which can reshape the problem’s scope and requirements. In the DR project, insights from deployment highlighted potential extensions to other imaging modalities, such as 3D Optical Coherence Tomography (OCT)5.
4 Emergent Behavior: Unexpected phenomena or behaviors not foreseen by designers, arising from the interaction of system components.
5 3D Optical Coherence Tomography (OCT): A non-invasive imaging technique used to obtain high resolution cross-sectional images of the retina.
Resource dependencies further highlight the interconnectedness of problem definition. Decisions about model complexity, for instance, directly affect infrastructure needs, data collection strategies, and deployment feasibility. Balancing these dependencies requires careful planning during the problem definition phase, ensuring that early decisions do not create bottlenecks in later stages.
Lifecycle Implications
The problem definition phase is foundational, influencing every subsequent stage of the lifecycle. A well-defined problem ensures that data collection focuses on the most relevant features, that models are developed with the right constraints in mind, and that deployment strategies align with operational realities.
In the DR project, defining the problem with scalability and adaptability in mind enabled the team to anticipate future challenges, such as accommodating new imaging devices or expanding to additional clinics. For instance, early considerations of diverse imaging conditions and patient demographics reduced the need for costly redesigns later in the lifecycle. This forward-thinking approach ensured the system’s long-term success and adaptability in dynamic healthcare environments.
By embedding lifecycle thinking into problem definition, teams can create systems that not only meet initial requirements but also adapt and evolve in response to changing conditions. This ensures that ML systems remain effective, scalable, and impactful over time.
Data Collection
Data is the foundation of machine learning systems, yet collecting and preparing data for ML applications introduces challenges that extend far beyond gathering enough training examples. Modern ML systems often need to handle terabytes of data, which range from raw, unstructured inputs to carefully annotated datasets, while maintaining quality, diversity, and relevance for model training. For medical systems like DR screening, data preparation must meet the highest standards to ensure diagnostic accuracy.
In the DR project, data collection involved a development dataset of 128,000 retinal fundus photographs evaluated by a panel of 54 ophthalmologists, with each image reviewed by 3-7 experts. This collaborative effort ensured high-quality labels that captured clinically relevant features like microaneurysms, hemorrhages, and hard exudates. Additionally, clinical validation datasets comprising 12,000 images provided an independent benchmark to test the model’s robustness against real-world variability, illustrating the importance of rigorous and representative data collection. The scale and complexity of this effort highlight how domain expertise and interdisciplinary collaboration are critical to building datasets for high-stakes ML systems.
Data Requirements and Impact
The requirements for data collection and preparation emerge from the dual perspectives of machine learning and operational constraints. In the DR project, high-quality retinal images annotated by experts were a foundational need to train accurate models. However, real-world conditions quickly revealed additional complexities. Images were collected from rural clinics using different camera equipment, operated by staff with varying levels of expertise, and often under conditions of limited network connectivity.
These operational realities shaped the system architecture in significant ways. The volume and size of high-resolution images necessitated local storage and preprocessing capabilities at clinics, as centralizing all data collection was impractical due to unreliable internet access. Furthermore, patient privacy regulations required secure data handling at every stage, from image capture to model training. Coordinating expert annotations also introduced logistical challenges, necessitating systems that could bridge the physical distance between clinics and ophthalmologists while maintaining workflow efficiency.
These considerations demonstrate how data collection requirements influence the entire ML lifecycle. Infrastructure design, annotation pipelines, and privacy protocols all play critical roles in ensuring that collected data aligns with both technical and operational goals.
Data Infrastructure
The flow of data through the system highlights critical infrastructure requirements at every stage. In the DR project, the journey of a single retinal image offers a glimpse into these complexities. From its capture on a retinal camera, where image quality is paramount, the data moves through local clinic systems for initial storage and preprocessing. Eventually, it must reach central systems where it is aggregated with data from other clinics for model training and validation.
At each step, the system must balance local needs with centralized aggregation requirements. Clinics with reliable high-speed internet could transmit data in real-time, but many rural locations relied on store-and-forward systems, where data was queued locally and transmitted in bulk when connectivity permitted. These differences necessitated flexible infrastructure that could adapt to varying conditions while maintaining data consistency and integrity across the lifecycle. This adaptability ensured that the system could function reliably despite the diverse operational environments of the clinics.
Scale and Distribution
As ML systems scale, the challenges of data collection grow exponentially. In the DR project, scaling from an initial few clinics to a broader network introduced significant variability in equipment, workflows, and operating conditions. Each clinic effectively became an independent data node, yet the system needed to ensure consistent performance and reliability across all locations.
This scaling effort also brought increasing data volumes, as higher-resolution imaging devices became standard, generating larger and more detailed images. These advances amplified the demands on storage and processing infrastructure, requiring optimizations to maintain efficiency without compromising quality. Differences in patient demographics, clinic workflows, and connectivity patterns further underscored the need for robust design to handle these variations gracefully.
Scaling challenges highlight how decisions made during the data collection phase ripple through the lifecycle, impacting subsequent stages like model development, deployment, and monitoring. For instance, accommodating higher-resolution data during collection directly influences computational requirements for training and inference, emphasizing the need for lifecycle thinking6 even at this early stage.
6 Lifecycle Thinking: Considering all phases of a system’s life from design to decommissioning to optimize overall performance.
Data Validation
Quality assurance is an integral part of the data collection process, ensuring that data meets the requirements for downstream stages. In the DR project, automated checks at the point of collection flagged issues like poor focus or incorrect framing, allowing clinic staff to address problems immediately. These proactive measures ensured that low-quality data was not propagated through the pipeline.
Validation systems extended these efforts by verifying not just image quality but also proper labeling, patient association, and compliance with privacy regulations. Operating at both local and centralized levels, these systems ensured data reliability and robustness, safeguarding the integrity of the entire ML pipeline.
Systems Thinking
Viewing data collection and preparation through a lifecycle lens reveals the interconnected nature of these processes. Each decision made during this phase influences subsequent stages of the ML system. For instance, choices about camera equipment and image preprocessing affect not only the quality of the training dataset but also the computational requirements for model development and the accuracy of predictions during deployment.

Figure 4 illustrates the key feedback loops that characterize the ML lifecycle, with particular relevance to data collection and preparation. Looking at the left side of the diagram, we see how monitoring and maintenance activities feed back to both data collection and preparation stages. For example, when monitoring reveals data quality issues in production (shown by the “Data Quality Issues” feedback arrow), this triggers refinements in our data preparation pipelines. Similarly, performance insights from deployment might highlight gaps in our training data distribution (indicated by the “Performance Insights” loop back to data collection), prompting the collection of additional data to cover underrepresented cases. In the DR project, this manifested when monitoring revealed that certain demographic groups were underrepresented in the training data, leading to targeted data collection efforts to improve model fairness and accuracy across all populations.
Feedback loops are another critical aspect of this lifecycle perspective. Insights from model performance often lead to adjustments in data collection strategies, creating an iterative improvement process. For example, in the DR project, patterns observed during model evaluation influenced updates to preprocessing pipelines, ensuring that new data aligned with the system’s evolving requirements.
The scaling of data collection introduces emergent behaviors that must be managed holistically. While individual clinics may function well in isolation, the simultaneous operation of multiple clinics can lead to system-wide patterns like network congestion or storage bottlenecks. These behaviors reinforce the importance of considering data collection as a system-level challenge rather than a discrete, isolated task.
In the following chapters, we will step through each of the major stages of the lifecycle shown in Figure 4. We will consider several key questions like what influences data source selection, how feedback loops can be systematically incorporated, and how emergent behaviors can be anticipated and managed holistically.
In addition, by adopting a systems thinking approach, we emphasize the iterative and interconnected nature of the ML lifecycle. How do choices in data collection and preparation ripple through the entire pipeline? What mechanisms ensure that monitoring insights and performance evaluations effectively inform improvements at earlier stages? And how can governance frameworks and infrastructure design evolve to meet the challenges of scaling while maintaining fairness and efficiency? These questions will guide our exploration of the lifecycle, offering a foundation for designing robust and adaptive ML systems.
Lifecycle Implications
The success of ML systems depends on how effectively data collection integrates with the entire lifecycle. Decisions made in this stage affect not only the quality of the initial model but also the system’s ability to evolve and adapt. For instance, data distribution shifts or changes in imaging equipment over time require the system to handle new inputs without compromising performance.
In the DR project, embedding lifecycle thinking into data management strategies ensured the system remained robust and scalable as it expanded to new clinics and regions. By proactively addressing variability and quality during data collection, the team minimized the need for costly downstream adjustments, aligning the system with long-term goals and operational realities.
Model Development
Model development and training form the core of machine learning systems, yet this stage presents unique challenges that extend far beyond selecting algorithms and tuning hyperparameters. It involves designing architectures suited to the problem, optimizing for computational efficiency, and iterating on models to balance performance with deployability. In high-stakes domains like healthcare, the stakes are particularly high, as every design decision impacts clinical outcomes.
For DR detection, the model needed to achieve expert-level accuracy while handling the high resolution and variability of retinal images. Using a deep neural network trained on their meticulously labeled dataset, the team achieved an F-score of 0.95, slightly exceeding the median score of the consulted ophthalmologists (0.91). This outcome highlights the effectiveness of state-of-the-art methods, such as transfer learning7, and the importance of interdisciplinary collaboration between data scientists and medical experts to refine features and interpret model outputs.
7 Transfer Learning: A method where a model developed for a task is reused as the starting point for a model on a second task.
Model Requirements and Impact
The requirements for model development emerge not only from the specific learning task but also from broader system constraints. In the DR project, the model needed high sensitivity and specificity to detect different stages of retinopathy. However, achieving this purely from an ML perspective was not sufficient. The system had to meet operational constraints, including running on limited hardware in rural clinics, producing results quickly enough to fit into clinical workflows, and being interpretable enough for healthcare providers to trust its outputs.
These requirements shaped decisions during model development. While state-of-the-art accuracy might favor the largest and most complex models, such approaches were infeasible given hardware and workflow constraints. The team focused on designing architectures that balanced accuracy with efficiency, exploring lightweight models that could perform well on constrained devices. For example, techniques like pruning and quantization were employed to optimize the models for resource-limited environments, ensuring compatibility with rural clinic infrastructure.
This balancing act influenced every part of the system lifecycle. Decisions about model architecture affected data preprocessing, shaped the training infrastructure, and determined deployment strategies. For example, choosing to use an ensemble of smaller models instead of a single large model altered data batching during training, required changes to inference pipelines, and introduced complexities in how model updates were managed in production.
Development Workflow
The model development workflow reflects the complex interplay between data, compute resources, and human expertise. In the DR project, this process began with data exploration and feature engineering, where data scientists collaborated with ophthalmologists to identify image characteristics indicative of retinopathy.
This initial stage required tools capable of handling large medical images and facilitating experimentation with preprocessing techniques. The team needed an environment that supported collaboration, visualization, and rapid iteration while managing the sheer scale of high-resolution data.
As the project advanced to model design and training, computational demands escalated. Training deep learning models on high-resolution images required extensive GPU resources and sophisticated infrastructure. The team implemented distributed training systems that could scale across multiple machines while managing large datasets, tracking experiments, and ensuring reproducibility. These systems also supported experiment comparison, enabling rapid evaluation of different architectures, hyperparameters, and preprocessing pipelines.
Model development was inherently iterative, with each cycle, involving adjustments to DNN architectures, refinements of hyperparameters, or incorporations of new data, producing extensive metadata, including checkpoints, validation results, and performance metrics. Managing this information across the team required robust tools for experiment tracking and version control to ensure that progress remained organized and reproducible.
Scale and Distribution
As ML systems scale in both data volume and model complexity, the challenges of model development grow exponentially. The DR project’s evolution from prototype models to production-ready systems highlights these hurdles. Expanding datasets, more sophisticated models, and concurrent experiments demanded increasingly powerful computational resources and meticulous organization.
Distributed training became essential to meet these demands. While it significantly reduced training time, it introduced complexities in data synchronization, gradient aggregation, and fault tolerance. The team relied on advanced frameworks to optimize GPU clusters, manage network latency, and address hardware failures, ensuring training processes remained efficient and reliable. These frameworks included automated failure recovery mechanisms, which helped maintain progress even in the event of hardware interruptions.
The need for continuous experimentation and improvement compounded these challenges. Over time, the team managed an expanding repository of model versions, training datasets, and experimental results. This growth required scalable systems for tracking experiments, versioning models, and analyzing results to maintain consistency and focus across the project.
Systems Thinking
Approaching model development through a systems perspective reveals its connections to every other stage of the ML lifecycle. Decisions about model architecture ripple through the system, influencing preprocessing requirements, deployment strategies, and clinical workflows. For instance, adopting a complex model might improve accuracy but increase memory usage, complicating deployment in resource-constrained environments.
Feedback loops are inherent to this stage. Insights from deployment inform adjustments to models, while performance on test sets guides future data collection and annotation. Understanding these cycles is critical for iterative improvement and long-term success.
Scaling model development introduces emergent behaviors, such as bottlenecks in shared resources or unexpected interactions between multiple training experiments. Addressing these behaviors requires robust planning and the ability to anticipate system-wide patterns that might arise from local changes.
The boundaries between model development and other lifecycle stages often blur. Feature engineering overlaps with data preparation, while optimization for inference spans both development and deployment. Navigating these overlaps effectively requires careful coordination and clear interface definitions.
Lifecycle Implications
Model development is not an isolated task; it exists within the broader ML lifecycle. Decisions made here influence data preparation strategies, training infrastructure, and deployment feasibility. The iterative nature of this stage ensures that insights gained feed back into data collection and system optimization, reinforcing the interconnectedness of the lifecycle.
In subsequent chapters, we will explore key questions that arise during model development:
How can scalable training infrastructures be designed for large-scale ML models?
What frameworks and tools help manage the complexity of distributed training?
How can model reproducibility and version control be ensured in evolving projects?
What trade-offs must be made to balance accuracy with operational constraints?
How can continual learning and updates be handled in production systems?
These questions highlight how model development sits at the core of ML systems, with decisions in this stage resonating throughout the entire lifecycle.
Deployment
Once validated, the trained model is integrated into production systems and workflows. Deployment requires addressing practical challenges such as system compatibility, scalability, and operational constraints. Successful integration hinges on ensuring that the model’s predictions are not only accurate but also actionable in real-world settings, where resource limitations and workflow disruptions can pose significant barriers.
In the DR project, deployment strategies were shaped by the diverse environments in which the system would operate. Edge deployment enabled local processing of retinal images in rural clinics with intermittent connectivity, while automated quality checks flagged poor-quality images for recapture, ensuring reliable predictions. These measures demonstrate how deployment must bridge technological sophistication with usability and scalability across varied clinical settings.
Deployment Requirements and Impact
The requirements for deployment stem from both the technical specifications of the model and the operational constraints of its intended environment. In the DR project, the model needed to operate in rural clinics with limited computational resources and intermittent internet connectivity. Additionally, it had to fit seamlessly into the existing clinical workflow, which required rapid, interpretable results that could assist healthcare providers without causing disruption.
These requirements influenced deployment strategies significantly. A cloud-based deployment, while technically simpler, was not feasible due to unreliable connectivity in many clinics. Instead, the team opted for edge deployment, where models ran locally on clinic hardware. This approach required optimizing the model for smaller, less powerful devices while maintaining high accuracy. Optimization techniques such as model quantization and pruning were employed to reduce resource demands without sacrificing performance.
Integration with existing systems posed additional challenges. The ML system had to interface with hospital information systems (HIS) for accessing patient records and storing results. Privacy regulations mandated secure data handling at every step, further shaping deployment decisions. These considerations ensured that the system adhered to clinical and legal standards while remaining practical for daily use.
Deployment Workflow
The deployment and integration workflow in the DR project highlighted the interplay between model functionality, infrastructure, and user experience. The process began with thorough testing in simulated environments that replicated the technical constraints and workflows of the target clinics. These simulations helped identify potential bottlenecks and incompatibilities early, allowing the team to refine the deployment strategy before full-scale rollout.
Once the deployment strategy was finalized, the team implemented a phased rollout. Initial deployments were limited to a few pilot sites, allowing for controlled testing in real-world conditions. This approach provided valuable feedback from clinicians and technical staff, helping to identify issues that hadn’t surfaced during simulations.
Integration efforts focused on ensuring seamless interaction between the ML system and existing tools. For example, the DR system had to pull patient information from the HIS, process retinal images from connected cameras, and return results in a format that clinicians could easily interpret. These tasks required the development of robust APIs, real-time data processing pipelines, and user-friendly interfaces tailored to the needs of healthcare providers.
Scale and Distribution
Scaling deployment across multiple locations introduced new complexities. Each clinic had unique infrastructure, ranging from differences in imaging equipment to variations in network reliability. These differences necessitated flexible deployment strategies that could adapt to diverse environments while ensuring consistent performance.
Despite achieving high performance metrics during development, the DR system faced unexpected challenges in real-world deployment. For example, in rural clinics, variations in imaging equipment and operator expertise led to inconsistencies in image quality that the model struggled to handle. These issues underscored the gap between laboratory success and operational reliability, prompting iterative refinements in both the model and the deployment strategy. Feedback from clinicians further revealed that initial system interfaces were not intuitive enough for widespread adoption, leading to additional redesigns.
Distribution challenges extended beyond infrastructure variability. The team needed to maintain synchronized updates across all deployment sites to ensure that improvements in model performance or system features were universally applied. This required implementing centralized version control systems and automated update pipelines that minimized disruption to clinical operations.
Despite achieving high performance metrics during development, the DR system faced unexpected challenges in real-world deployment. As illustrated in Figure 4, these challenges create multiple feedback paths—“Deployment Constraints” flowing back to model training to trigger optimizations, while “Performance Insights” from monitoring could necessitate new data collection. For example, when the system struggled with images from older camera models, this triggered both model optimizations and targeted data collection to improve performance under these conditions.
Another critical scaling challenge was training and supporting end-users. Clinicians and staff needed to understand how to operate the system, interpret its outputs, and provide feedback. The team developed comprehensive training programs and support channels to facilitate this transition, recognizing that user trust and proficiency were essential for system adoption.
Robustness and Reliability
In a clinical context, reliability is paramount. The DR system needed to function seamlessly under a wide range of conditions, from high patient volumes to suboptimal imaging setups. To ensure robustness, the team implemented fail-safes that could detect and handle common issues, such as incomplete or poor-quality data. These mechanisms included automated image quality checks and fallback workflows for cases where the system encountered errors.
Testing played a central role in ensuring reliability. The team conducted extensive stress testing to simulate peak usage scenarios, validating that the system could handle high throughput without degradation in performance. Redundancy was built into critical components to minimize the risk of downtime, and all interactions with external systems, such as the HIS, were rigorously tested for compatibility and security.
Systems Thinking
Deployment and integration, viewed through a systems lens, reveal deep connections to every other stage of the ML lifecycle. Decisions made during model development influence deployment architecture, while choices about data handling affect integration strategies. Monitoring requirements often dictate how deployment pipelines are structured, ensuring compatibility with real-time feedback loops.
Feedback loops are integral to deployment and integration. Real-world usage generates valuable insights that inform future iterations of model development and evaluation. For example, clinician feedback on system usability during the DR project highlighted the need for clearer interfaces and more interpretable outputs, prompting targeted refinements in design and functionality.
Emergent behaviors frequently arise during deployment. In the DR project, early adoption revealed unexpected patterns, such as clinicians using the system for edge cases or non-critical diagnostics. These behaviors, which were not predicted during development, necessitated adjustments to both the system’s operational focus and its training programs.
Deployment introduces significant resource dependencies. Running ML models on edge devices required balancing computational efficiency with accuracy, while ensuring other clinic operations were not disrupted. These trade-offs extended to the broader system, influencing everything from hardware requirements to scheduling updates without affecting clinical workflows.
The boundaries between deployment and other lifecycle stages are fluid. Optimization efforts for edge devices often overlapped with model development, while training programs for clinicians fed directly into monitoring and maintenance. Navigating these overlaps required clear communication and collaboration between teams, ensuring seamless integration and ongoing system adaptability.
By applying a systems perspective to deployment and integration, we can better anticipate challenges, design robust solutions, and maintain the flexibility needed to adapt to evolving operational and technical demands. This approach ensures that ML systems not only achieve initial success but remain effective and reliable in real-world applications.
Lifecycle Implications
Deployment and integration are not terminal stages; they are the point at which an ML system becomes operationally active and starts generating real-world feedback. This feedback loops back into earlier stages, informing data collection strategies, model improvements, and evaluation protocols. By embedding lifecycle thinking into deployment, teams can design systems that are not only operationally effective but also adaptable and resilient to evolving needs.
In subsequent chapters, we will explore key questions related to deployment and integration:
How can deployment strategies balance computational constraints with performance needs?
What frameworks support scalable, synchronized deployments across diverse environments?
How can systems be designed for seamless integration with existing workflows and tools?
What are best practices for ensuring user trust and proficiency in operating ML systems?
How do deployment insights feed back into the ML lifecycle to drive continuous improvement?
These questions emphasize the interconnected nature of deployment and integration within the lifecycle, highlighting the importance of aligning technical and operational priorities to create systems that deliver meaningful, lasting impact.
Maintenance
Monitoring and maintenance represent the ongoing, critical processes that ensure the continued effectiveness and reliability of deployed machine learning systems. Unlike traditional software, ML systems must account for shifts in data distributions, changing usage patterns, and evolving operational requirements. Monitoring provides the feedback necessary to adapt to these challenges, while maintenance ensures the system evolves to meet new needs.
As shown in Figure 4, monitoring serves as a central hub for system improvement, generating three critical feedback loops: “Performance Insights” flowing back to data collection to address gaps, “Data Quality Issues” triggering refinements in data preparation, and “Model Updates” initiating retraining when performance drifts. In the DR project, these feedback loops enabled continuous system improvement, from identifying underrepresented patient demographics (triggering new data collection) to detecting image quality issues (improving preprocessing) and addressing model drift (initiating retraining).
For DR screening, continuous monitoring tracked system performance across diverse clinics, detecting issues such as changing patient demographics or new imaging technologies that could impact accuracy. Proactive maintenance included plans to incorporate 3D imaging modalities like OCT, expanding the system’s capabilities to diagnose a wider range of conditions. This highlights the importance of designing systems that can adapt to future challenges while maintaining compliance with rigorous healthcare regulations.
Monitoring Requirements and Impact
The requirements for monitoring and maintenance emerged from both technical needs and operational realities. In the DR project, the technical perspective required continuous tracking of model performance, data quality, and system resource usage. However, operational constraints added layers of complexity: monitoring systems had to align with clinical workflows, detect shifts in patient demographics, and provide actionable insights to both technical teams and healthcare providers.
Initial deployment highlighted several areas where the system failed to meet real-world needs, such as decreased accuracy in clinics with outdated equipment or lower-quality images. Monitoring systems detected performance drops in specific subgroups, such as patients with less common retinal conditions, demonstrating that even a well-trained model could face blind spots in practice. These insights informed maintenance strategies, including targeted updates to address specific challenges and expanded training datasets to cover edge cases.
These requirements influenced system design significantly. The critical nature of the DR system’s function demanded real-time monitoring capabilities rather than periodic offline evaluations. To support this, the team implemented advanced logging and analytics pipelines to process large amounts of operational data from clinics without disrupting diagnostic workflows. Secure and efficient data handling was essential to transmit data across multiple clinics while preserving patient confidentiality.
Monitoring requirements also affected model design, as the team incorporated mechanisms for granular performance tracking and anomaly detection. Even the system’s user interface was influenced, needing to present monitoring data in a clear, actionable manner for clinical and technical staff alike.
Maintenance Workflow
The monitoring and maintenance workflow in the DR project revealed the intricate interplay between automated systems, human expertise, and evolving healthcare practices. The process began with defining a comprehensive monitoring framework, establishing key performance indicators (KPIs), and implementing dashboards and alert systems. This framework had to balance depth of monitoring with system performance and privacy considerations, collecting sufficient data to detect issues without overburdening the system or violating patient confidentiality.
As the system matured, maintenance became an increasingly dynamic process. Model updates driven by new medical knowledge or performance improvements required careful validation and controlled rollouts. The team employed A/B testing frameworks8 to evaluate updates in real-world conditions and implemented rollback mechanisms to address issues quickly when they arose.
8 A/B Testing: A method in statistics to compare two versions of a variable to determine which performs better in a controlled environment.
Monitoring and maintenance formed an iterative cycle rather than discrete phases. Insights from monitoring informed maintenance activities, while maintenance efforts often necessitated updates to monitoring strategies. The team developed workflows to transition seamlessly from issue detection to resolution, involving collaboration across technical and clinical domains.
Scale and Distribution
As the DR project scaled from pilot sites to widespread deployment, monitoring and maintenance complexities grew exponentially. Each additional clinic added to the volume of operational data and introduced new environmental variables, such as differing hardware configurations or demographic patterns.
The need to monitor both global performance metrics and site-specific behaviors required sophisticated infrastructure. While global metrics provided an overview of system health, localized issues, including a hardware malfunction at a specific clinic or unexpected patterns in patient data, needed targeted monitoring. Advanced analytics systems processed data from all clinics to identify these localized anomalies while maintaining a system-wide perspective.
Continuous adaptation added further complexity. Real-world usage exposed the system to an ever-expanding range of scenarios. Capturing insights from these scenarios and using them to drive system updates required efficient mechanisms for integrating new data into training pipelines and deploying improved models without disrupting clinical workflows.
Proactive Maintenance
Reactive maintenance alone was insufficient for the DR project’s dynamic operating environment. Proactive strategies became essential to anticipate and prevent issues before they affected clinical operations.
The team implemented predictive maintenance models to identify potential problems based on patterns in operational data. Continuous learning pipelines allowed the system to retrain and adapt based on new data, ensuring its relevance as clinical practices or patient demographics evolved. These capabilities required careful balancing to ensure safety and reliability while maintaining system performance.
Metrics assessing adaptability and resilience became as important as accuracy, reflecting the system’s ability to evolve alongside its operating environment. Proactive maintenance ensured the system could handle future challenges without sacrificing reliability.
Systems Thinking
Monitoring and maintenance, viewed through a systems lens, reveal their deep integration with every other stage of the ML lifecycle. Changes in data collection affect model behavior, which influences monitoring thresholds. Maintenance actions can alter system availability or performance, impacting users and clinical workflows.
Feedback loops are central to these processes. Monitoring insights drive updates to models and workflows, while user feedback informs maintenance priorities. These loops ensure the system remains responsive to both technical and clinical needs.
Emergent behaviors often arise in distributed deployments. The DR team identified subtle system-wide shifts in diagnostic patterns that were invisible in individual clinics but evident in aggregated data. Managing these behaviors required sophisticated analytics and a holistic view of the system.
Resource dependencies also presented challenges. Real-time monitoring competed with diagnostic functions for computational resources, while maintenance activities required skilled personnel and occasional downtime. Effective resource planning was critical to balancing these demands.
Lifecycle Implications
Monitoring and maintenance are not isolated stages but integral parts of the ML lifecycle. Insights gained from these activities feed back into data collection, model development, and evaluation, ensuring the system evolves in response to real-world challenges. This lifecycle perspective emphasizes the need for strategies that not only address immediate concerns but also support long-term adaptability and improvement.
In subsequent chapters, we will explore critical questions related to monitoring and maintenance:
How can monitoring systems detect subtle degradations in ML performance across diverse environments?
What strategies support efficient maintenance of ML systems deployed at scale?
How can continuous learning pipelines ensure relevance without compromising safety?
What tools facilitate proactive maintenance and minimize disruption in production systems?
How do monitoring and maintenance processes influence the design of future ML models?
These questions highlight the interconnected nature of monitoring and maintenance, where success depends on creating a framework that ensures both immediate reliability and long-term viability in complex, dynamic environments.
AI Lifecycle Roles
Building effective and resilient machine learning systems is far more than a solo pursuit; it’s a collaborative endeavor that thrives on the diverse expertise of a multidisciplinary team. Each role in this intricate dance brings unique skills and insights, supporting different phases of the AI development process. Understanding who these players are, what they contribute, and how they interconnect is crucial to navigating the complexities of modern AI systems.
Collaboration in AI
At the heart of any AI project is a team of data scientists. These innovative thinkers focus on model creation, experiment with architectures, and refine the algorithms that will become the neural networks driving insights from data. In our DR project, data scientists were instrumental in architecting neural networks capable of identifying retinal anomalies, advancing through iterations to fine-tune a balance between accuracy and computational efficiency.
Behind the scenes, data engineers work tirelessly to design robust data pipelines, ensuring that vast amounts of data are ingested, transformed, and stored effectively. They play a crucial role in the DR project, handling data from various clinics and automating quality checks to guarantee that the training inputs were standardized and reliable.
Meanwhile, machine learning engineers take the baton to integrate these models into production settings. They guarantee that models are nimble, scalable, and fit the constraints of the deployment environment. In rural clinics where computational resources can be scarce, their work in optimizing models was pivotal to enabling on-the-spot diagnosis.
Domain experts, such as ophthalmologists in the DR project, infuse technical progress with practical relevance. Their insights shape early problem definitions and ensure that AI tools align closely with real-world needs, offering a measure of validation that keeps the outcome aligned with clinical and operational realities.
MLOps engineers are the guardians of workflow automation, orchestrating the continuous integration and monitoring systems that keep AI models up and running. They crafted centralized monitoring frameworks in the DR project, ensuring that updates were streamlined and model performance remained optimal across different deployment sites.
Ethicists and compliance officers remind us of the larger responsibility that accompanies AI deployment, ensuring adherence to ethical standards and legal requirements. Their oversight in the DR initiative safeguarded patient privacy amidst strict healthcare regulations.
Project managers weave together these diverse strands, orchestrating timelines, resources, and communication streams to maintain project momentum and alignment with objectives. They acted as linchpins within the project, harmonizing efforts between tech teams, clinical practitioners, and policy makers.
Role Interplay
The synergy between these roles fuels the AI machinery toward successful outcomes. Data engineers establish a solid foundation for data scientists’ creative model-building endeavors. As models transition into real-world applications, ML engineers ensure compatibility and efficiency. Meanwhile, feedback loops between MLOps engineers and data scientists foster continuous improvement, enabling quick adaptation to data-driven discoveries.
Ultimately, the success of the DR project underscores the irreplaceable value of interdisciplinary collaboration. From bridging clinical insights with technical prowess to ensuring ethical deployment, this collective effort exemplifies how AI initiatives can be both technically successful and socially impactful.
This interconnected approach underlines why our exploration in later chapters will delve into various aspects of AI development, including those that may be seen as outside an individual’s primary expertise. Understanding these diverse roles will equip us to build more robust, well-rounded AI solutions. By comprehending the broader context and the interplay of roles, you’ll be better prepared to address challenges and collaborate effectively, paving the way for innovative and responsible AI systems.
Summary
The AI workflow we’ve explored, while illustrated through the Diabetic Retinopathy project, represents a framework applicable across diverse domains of AI application. From finance and manufacturing to environmental monitoring and autonomous vehicles, the core stages of the workflow remain consistent, even as their specific implementations vary widely.
The interconnected nature of the AI lifecycle, illustrated in Figure 4, is a universal constant. The feedback loops, from “Performance Insights” driving data collection to “Validation Issues” triggering model updates, demonstrate how decisions in one stage invariably impact others. Data quality affects model performance, deployment constraints influence architecture choices, and real-world usage patterns drive ongoing refinement through these well-defined feedback paths.
Regardless of the application, the interconnected nature of the AI lifecycle is a universal constant. Whether developing fraud detection systems for banks or predictive maintenance models for industrial equipment, decisions made in one stage invariably impact others. Data quality affects model performance, deployment constraints influence architecture choices, and real-world usage patterns drive ongoing refinement.
This interconnectedness underscores the importance of systems thinking in AI development across all sectors. Success in AI projects, regardless of domain, comes from understanding and managing the complex interactions between stages, always considering the broader context in which the system will operate.
As AI continues to evolve and expand into new areas, this holistic approach becomes increasingly crucial. Future challenges in AI development, whether in healthcare, finance, environmental science, or any other field, will likely center around managing increased complexity, ensuring adaptability, and balancing performance with ethical considerations. By approaching AI development with a systems-oriented mindset, we can create solutions that are not only technically proficient but also robust, adaptable, and aligned with real-world needs across a wide spectrum of applications.