Benchmarking AI
DALL·E 3 Prompt: Photo of a podium set against a tech-themed backdrop. On each tier of the podium, there are AI chips with intricate designs. The top chip has a gold medal hanging from it, the second one has a silver medal, and the third has a bronze medal. Banners with ‘AI Olympics’ are displayed prominently in the background.

Purpose
Why does systematic measurement form the foundation of engineering progress in machine learning systems, and how does standardized benchmarking enable scientific advancement in this emerging field?
Engineering disciplines advance through measurement and comparison, establishing benchmarking as essential to machine learning systems development. Without systematic evaluation frameworks, optimization claims lack scientific rigor, hardware investments proceed without evidence, and system improvements cannot be verified or reproduced. Benchmarking transforms subjective impressions into objective data, enabling engineers to distinguish genuine advances from implementation artifacts. This measurement discipline is essential because ML systems involve complex interactions between algorithms, hardware, and data that defy intuitive performance prediction. Standardized benchmarks establish shared baselines allowing meaningful comparison across research groups, enable cumulative progress through reproducible results, and provide empirical foundations necessary for engineering decision-making. Understanding benchmarking principles enables systematic evaluation driving continuous improvement and establishes machine learning systems engineering as rigorous scientific discipline.
Learning Objectives
Analyze the evolution of ML benchmarking and explain how benchmark gaming lessons inform current design
Distinguish between the three dimensions of ML benchmarking (algorithmic, systems, and data) and evaluate how each dimension contributes to comprehensive system assessment
Compare training and inference benchmarking methodologies, identifying specific metrics and evaluation protocols appropriate for each phase of the ML lifecycle
Apply MLPerf benchmarking standards to evaluate solutions and guide optimization decisions
Design statistically rigorous experimental protocols that account for ML system variability, including appropriate sample sizes and confidence interval reporting
Critique existing benchmark results for common fallacies and pitfalls, distinguishing between benchmark performance and real-world deployment effectiveness
Implement production monitoring strategies that extend benchmarking principles to operational environments, including A/B testing and continuous model validation
Evaluate performance trade-offs across accuracy, latency, energy, and fairness for deployment optimization
Machine Learning Benchmarking Framework
The systematic evaluation of machine learning systems presents a critical methodological challenge within the broader discipline of performance engineering. While previous chapters have established comprehensive optimization frameworks, particularly hardware acceleration strategies (Chapter 11: AI Acceleration), the validation of these approaches requires rigorous measurement methodologies that extend beyond traditional computational benchmarking.
Consider the challenge facing engineers evaluating competing AI hardware solutions. A vendor might demonstrate impressive performance gains on carefully selected benchmarks, yet fail to deliver similar improvements in production workloads. Without comprehensive evaluation frameworks, distinguishing genuine advances from implementation artifacts becomes nearly impossible. This challenge illustrates why systematic measurement forms the foundation of engineering progress in machine learning systems.
This chapter examines benchmarking as an essential empirical discipline that enables quantitative assessment of machine learning system performance across diverse operational contexts. Benchmarking establishes the methodological foundation for evidence-based engineering decisions, providing systematic evaluation frameworks that allow practitioners to compare competing approaches, validate optimization strategies, and ensure reproducible performance claims in both research and production environments.
Machine learning benchmarking presents unique challenges that distinguish it from conventional systems evaluation. The probabilistic nature of machine learning algorithms introduces inherent performance variability that traditional deterministic benchmarks cannot adequately characterize. ML system performance exhibits complex dependencies on data characteristics, model architectures, and computational resources, creating multidimensional evaluation spaces that require specialized measurement approaches.
Contemporary machine learning systems demand evaluation frameworks that accommodate multiple, often competing, performance objectives. Beyond computational efficiency, these systems must be assessed across dimensions including predictive accuracy, convergence properties, energy consumption, fairness, and robustness. This multi-objective evaluation paradigm necessitates sophisticated benchmarking methodologies that can characterize trade-offs and guide system design decisions within specific operational constraints.
The field has evolved to address these challenges through comprehensive evaluation approaches that operate across three core dimensions:
This chapter provides a systematic examination of machine learning benchmarking methodologies, beginning with the historical evolution of computational evaluation frameworks and their adaptation to address the unique requirements of probabilistic systems. We analyze standardized evaluation frameworks such as MLPerf that establish comparative baselines across diverse hardware architectures and implementation strategies. The discussion subsequently examines the essential distinctions between training and inference evaluation, exploring the specialized metrics and methodologies required to characterize their distinct computational profiles and operational requirements.
The analysis extends to specialized evaluation contexts, including resource-constrained mobile and edge deployment scenarios that present unique measurement challenges. We conclude by investigating production monitoring methodologies that extend benchmarking principles beyond controlled experimental environments into dynamic operational contexts. This comprehensive treatment demonstrates how rigorous measurement validates the performance improvements achieved through the optimization techniques and hardware acceleration strategies examined in preceding chapters, while establishing the empirical foundation essential for the deployment strategies explored in Part IV.
Historical Context
The evolution from simple performance metrics to comprehensive ML benchmarking reveals three critical methodological shifts, each addressing failures of previous evaluation paradigms that directly inform our current approach.
Performance Benchmarks
The evolution from synthetic operations to representative workloads emerged when early benchmark gaming undermined evaluation validity. Mainframe benchmarks like Whetstone (1964) and LINPACK (1979) measured isolated operations, enabling vendors to optimize for narrow tests rather than practical performance. SPEC CPU (1989) pioneered using real application workloads to ensure evaluation reflects actual deployment scenarios. This lesson directly shapes ML benchmarking, as optimization claims from Chapter 10: Model Optimizations require validation on representative tasks. MLPerf’s inclusion of real models like ResNet-50 and BERT ensures benchmarks capture deployment complexity rather than idealized test cases.
As deployment contexts diversified, benchmarks evolved from single-dimension to multi-objective evaluation. Graphics benchmarks measured quality alongside speed; mobile benchmarks evaluated battery life with performance. The multi-objective challenges from Chapter 9: Efficient AI, balancing accuracy, latency, and energy, manifest directly in modern ML evaluation where no single metric captures deployment viability.
The shift from isolated components to integrated systems occurred when distributed computing revealed that component optimization fails to predict system performance. ML training depends not just on accelerator compute (Chapter 11: AI Acceleration) but on data pipelines, gradient synchronization, and storage throughput. MLPerf evaluates complete workflows, recognizing that performance emerges from component interactions.
These lessons culminate in MLPerf (2018), which synthesizes representative workloads, multi-objective evaluation, and integrated measurement while addressing ML-specific challenges (Ranganathan and Hölzle 2024).
Ranganathan, Parthasarathy, and Urs Hölzle. 2024. “Twenty Five Years of Warehouse-Scale Computing.” IEEE Micro 44 (5): 11–22. https://doi.org/10.1109/mm.2024.3409469.
Energy Benchmarks
The multi-objective evaluation paradigm naturally extended to energy efficiency as computing diversified beyond mainframes with unlimited power budgets. Mobile devices demanded battery life optimization, while warehouse-scale systems faced energy costs rivaling hardware expenses. This shift established energy as a first-class metric alongside performance, spawning benchmarks like SPEC Power1 for servers, Green5002 for supercomputers, and ENERGY STAR3 for consumer systems.
1 SPEC Power: Introduced in 2007 to address the growing importance of energy efficiency in server design, SPEC Power measures performance per watt across 10 different load levels from 10% to 100%. Results show that modern servers achieve 8-12 SPECpower_ssj2008 scores per watt, compared to 1-3 for systems from the mid-2000s, representing approximately 3-4x efficiency improvement.
2 Green500: Started in 2007 as a counterpart to the Top500 supercomputer list, Green500 ranks systems by FLOPS per watt rather than raw performance. The most efficient systems achieve over 60 gigaFLOPS per watt compared to less than 1 gigaFLOPS/watt for early 2000s supercomputers, demonstrating improvements in computational efficiency.
3 ENERGY STAR: Launched by the EPA in 1992, this voluntary program has prevented over 4 billion tons of greenhouse gas emissions and saved consumers $450 billion on energy bills. Computing equipment must meet strict efficiency requirements: ENERGY STAR computers typically consume 30-65% less energy than standard models during operation and sleep modes.
Despite these advances, power benchmarking faces ongoing challenges in accounting for diverse workload patterns and system configurations across computing environments. Recent advancements, such as the MLPerf Power benchmark, have introduced specialized methodologies for measuring the energy impact of machine learning workloads, directly addressing the growing importance of energy efficiency in AI-driven computing.
Energy benchmarking extends beyond hardware energy measurement alone. Algorithmic energy optimization represents an equally critical dimension of modern AI benchmarking, where energy-efficient algorithms achieve performance improvements through computational reduction rather than purely hardware enhancement. Neural network pruning reduces energy consumption by eliminating unnecessary computations: pruned BERT models can achieve 90% of original task accuracy with 10x fewer parameters, delivering 4-8x inference speedup and 8-12x energy reduction depending on pruning method and hardware (Han, Mao, and Dally 2015). Quantization techniques achieve similar gains by reducing precision requirements: INT8 quantization typically provides 4x inference speedup with 4x energy reduction while maintaining 99%+ accuracy preservation (Jacob et al. 2018).
Han, Song, Huizi Mao, and William J. Dally. 2015. “Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding,” October. http://arxiv.org/abs/1510.00149v5.
Jacob, Benoit, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. 2018. “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference.” In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2704–13. CVPR ’18. IEEE. https://doi.org/10.1109/cvpr.2018.00286.
Howard, Andrew G., Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. 2017. “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.” arXiv Preprint arXiv:1704.04861, April. http://arxiv.org/abs/1704.04861v1.
Knowledge distillation offers another algorithmic energy optimization pathway, where smaller “student” models learn from larger “teacher” models. MobileNet architectures demonstrate this principle, achieving 10x energy reduction versus ResNet while maintaining similar accuracy through depthwise separable convolutions and width multipliers (Howard et al. 2017). Model compression techniques collectively enable deployment of sophisticated AI capabilities within severe energy constraints, making techniques essential for mobile and edge computing scenarios.
Energy-aware benchmarking must evaluate not just hardware power consumption, but also algorithmic efficiency metrics including FLOP reduction through sparsity, memory access reduction through compression, and computational energy benefits from quantization. These algorithmic optimizations often achieve greater energy savings than hardware improvements alone, providing a critical dimension for energy benchmarking frameworks.
As artificial intelligence and edge computing evolve, power benchmarking will drive energy-efficient hardware and software innovations. This connects directly to sustainable AI practices discussed in Chapter 18: Sustainable AI, where energy-aware design principles guide environmentally responsible AI development.
Domain-Specific Benchmarks
Computing diversification necessitated specialized benchmarks tailored to domain-specific requirements that generic metrics cannot capture. Domain-specific benchmarks address three categories of specialization:
Deployment constraints shape core metric priorities. Datacenter workloads optimize for throughput with kilowatt-scale power budgets, while mobile AI operates within 2-5W thermal envelopes, and IoT devices require milliwatt-scale operation. These constraints, rooted in efficiency principles from Chapter 9: Efficient AI, determine whether benchmarks prioritize total throughput or energy per operation.
Application requirements impose functional and regulatory constraints beyond performance. Healthcare AI demands interpretability metrics alongside accuracy; financial systems require microsecond latency with audit compliance; autonomous vehicles need safety-critical reliability (ASIL-D: <10^-8 failure/hour). These requirements, connecting to responsible AI principles in Chapter 17: Responsible AI, extend evaluation beyond traditional performance metrics.
Operational conditions determine real-world viability. Autonomous vehicles face -40°C to +85°C temperatures and degraded sensor inputs; datacenters handle millions of concurrent requests with network partitions; industrial IoT endures years-long deployment without maintenance. Hardware capabilities from Chapter 11: AI Acceleration only deliver value when validated under these conditions.
Machine learning presents a prominent example of this transition toward domain-specific evaluation. Traditional CPU and GPU benchmarks prove insufficient for assessing ML workloads, which involve complex interactions between computation, memory bandwidth, and data movement patterns. MLPerf has standardized performance measurement for machine learning models across these three categories: MLPerf Training addresses datacenter deployment constraints with multi-node scaling benchmarks, MLPerf Inference evaluates latency-critical application requirements across server to edge deployments, and MLPerf Tiny assesses ultra-constrained operational conditions for microcontroller deployments. This tiered structure reflects the systematic application of our three-category framework to ML-specific evaluation needs.
The strength of domain-specific benchmarks lies in their ability to capture these specialized requirements that general benchmarks overlook. By systematically addressing deployment constraints, application requirements, and operational conditions, these benchmarks provide insights that drive targeted optimizations in both hardware and software while ensuring that improvements translate to real-world deployment success rather than merely optimizing for narrow laboratory conditions.
This historical progression from general computing benchmarks through energy-aware measurement to domain-specific evaluation frameworks provides the foundation for understanding contemporary ML benchmarking challenges. The lessons learned (representative workloads over synthetic tests, multi-objective over single metrics, and integrated systems over isolated components) directly shape how we approach AI system evaluation today.
Machine Learning Benchmarks
The historical evolution culminates in machine learning benchmarking, where the complexity exceeds all previous computing domains. Unlike traditional workloads with deterministic behavior, ML systems introduce inherent uncertainty through their probabilistic nature. A CPU benchmark produces identical results given the same inputs; an ML model’s performance varies with training data, initialization, and even the order of operations. This inherent variability, combined with the lessons from decades of benchmark evolution, necessitates our three-dimensional evaluation framework.
Building on the framework and optimization techniques from previous chapters, ML benchmarks must evaluate not just computational efficiency but the intricate interplay between algorithms, hardware, and data. The evolution of benchmarks reaches its current apex in machine learning, where our established three-dimensional framework reflects decades of computing measurement evolution. Early machine learning benchmarks focused primarily on algorithmic performance, measuring how well models could perform specific tasks (Lecun et al. 1998). However, as machine learning applications scaled dramatically and computational demands grew exponentially, the focus naturally expanded to include system performance and hardware efficiency (Jouppi et al. 2017). Recently, the role of data quality has emerged as the third dimension of evaluation (Gebru et al. 2021).
Jouppi, Norman P., Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, et al. 2017. “In-Datacenter Performance Analysis of a Tensor Processing Unit.” In Proceedings of the 44th Annual International Symposium on Computer Architecture, 45:1–12. 2. ACM. https://doi.org/10.1145/3079856.3080246.
AI benchmarks differ from traditional performance metrics through their inherent variability, which introduces accuracy as a new evaluation dimension alongside deterministic characteristics like computational speed or energy consumption. The probabilistic nature of machine learning models means the same system can produce different results depending on the data it encounters, making accuracy a defining factor in performance assessment. This distinction adds complexity: benchmarking AI systems requires measuring not only raw computational efficiency but also understanding trade-offs between accuracy, generalization, and resource constraints.
Energy efficiency emerges as a cross-cutting concern that influences all three dimensions of our framework: algorithmic choices affect computational complexity and power requirements, hardware capabilities determine energy-performance trade-offs, and dataset characteristics influence training energy costs. This multifaceted evaluation approach represents a departure from earlier benchmarks that focused on isolated aspects like computational speed or energy efficiency (Hernandez and Brown 2020).
Hernandez, Danny, and Tom B. Brown. 2020. “Measuring the Algorithmic Efficiency of Neural Networks.” arXiv Preprint arXiv:2007.03051, May. https://doi.org/10.48550/arxiv.2005.04305.
Jouppi, Norman P., Doe Hyun Yoon, Matthew Ashcraft, Mark Gottscho, Thomas B. Jablin, George Kurian, James Laudon, et al. 2021. “Ten Lessons from Three Generations Shaped Google’s TPUv4i : Industrial Product.” In 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), 64:1–14. 5. IEEE. https://doi.org/10.1109/isca52012.2021.00010.
Bender, Emily M., Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜.” In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–23. ACM. https://doi.org/10.1145/3442188.3445922.
This evolution in benchmark complexity directly mirrors the field’s evolving understanding of what truly drives machine learning system success. While algorithmic innovations initially dominated progress metrics throughout the research phase, the practical challenges of deploying models at scale revealed the critical importance of hardware efficiency (Jouppi et al. 2021). Subsequently, high-profile failures of machine learning systems in real-world deployments highlighted how data quality and representation directly determine system reliability and fairness (Bender et al. 2021). Understanding how these dimensions interact has become necessary for accurately assessing machine learning system performance, informing development decisions, and measuring technological progress in the field.
ML Measurement Challenges
The unique characteristics of ML systems create measurement challenges that traditional benchmarks never faced. Unlike deterministic algorithms that produce identical outputs given the same inputs, ML systems exhibit inherent variability from multiple sources: algorithmic randomness from weight initialization and data shuffling, hardware thermal states affecting clock speeds, system load variations from concurrent processes, and environmental factors including network conditions and power management. This variability requires rigorous statistical methodology to distinguish genuine performance improvements from measurement noise.
To address this variability, effective benchmark protocols require multiple experimental runs with different random seeds. Running each benchmark 5-10 times and reporting statistical measures beyond simple means (including standard deviations or 95% confidence intervals) quantifies result stability and allows practitioners to distinguish genuine performance improvements from measurement noise.
Recent studies have highlighted how inadequate statistical rigor can lead to misleading conclusions. Many reinforcement learning papers report improvements that fall within statistical noise (Henderson et al. 2018), while GAN comparisons often lack proper experimental protocols, leading to inconsistent rankings across different random seeds (Lucic et al. 2018). These findings underscore the importance of establishing comprehensive measurement protocols that account for ML’s probabilistic nature.
Henderson, Peter, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. 2018. “Deep Reinforcement Learning That Matters.” Proceedings of the AAAI Conference on Artificial Intelligence 32 (1). https://doi.org/10.1609/aaai.v32i1.11694.
Lucic, Mario, Karol Kurach, Marcin Michalski, Sylvain Gelly, and Olivier Bousquet. 2018. “Are GANs Created Equal? A Large-Scale Study.” In Advances in Neural Information Processing Systems. Vol. 31. https://proceedings.neurips.cc/paper/2018/file/e46e7bb42968e44f4b3e72f703b6de8f-Paper.pdf.
Representative workload selection critically determines benchmark validity. Synthetic microbenchmarks often fail to capture the complexity of real ML workloads where data movement, memory allocation, and dynamic batching create performance patterns not visible in simplified tests. Comprehensive benchmarking requires workloads that reflect actual deployment patterns: variable sequence lengths in language models, mixed precision training regimes, and realistic data loading patterns that include preprocessing overhead. The distinction between statistical significance and practical significance requires careful interpretation. A small performance improvement might achieve statistical significance across hundreds of trials but prove operationally irrelevant if it falls within measurement noise or costs exceed benefits.
Addressing this requires careful benchmark design that prioritizes representative workloads over synthetic tests. Effective system evaluation relies on end-to-end application benchmarks like MLPerf that incorporate data preprocessing and reflect realistic deployment patterns. When developing custom evaluation frameworks, profiling production workloads helps identify the representative data distributions, batch sizes, and computational patterns essential for meaningful assessment.
Current benchmarking paradigms often fall short by measuring narrow task performance while missing characteristics that determine real-world system effectiveness. Most existing benchmarks evaluate supervised learning performance on static datasets, primarily testing pattern recognition capabilities rather than the adaptability and resilience required for production deployment. This limitation becomes apparent when models achieve excellent benchmark performance yet fail when deployed in slightly different conditions or domains. To address these shortcomings, comprehensive system evaluation must measure learning efficiency, continual learning capability, and out-of-distribution generalization alongside traditional metrics.
Algorithmic Benchmarks
Algorithmic benchmarks focus specifically on the first dimension of our framework: measuring model performance, accuracy, and efficiency. While hardware systems and training data quality certainly influence results, algorithmic benchmarks deliberately isolate model capabilities to enable clear understanding of the trade-offs between accuracy, computational complexity, and generalization.
AI algorithms face the complex challenge of balancing multiple performance objectives simultaneously, including accuracy, speed, resource efficiency, and generalization capability. As machine learning applications continue to span diverse domains, including computer vision, natural language processing, speech recognition, and reinforcement learning, evaluating these competing objectives requires carefully standardized methodologies tailored to each domain’s unique challenges. Algorithmic benchmarks, such as ImageNet4 (Deng et al. 2009), establish these evaluation frameworks, providing a consistent basis for comparing different machine learning approaches.
4 ImageNet: Created by Fei-Fei Li at Stanford starting in 2007, this dataset contains 14 million images across 20,000 categories, with 1.2 million images used for the annual classification challenge (ILSVRC). ImageNet’s impact is profound: it sparked the deep learning revolution when AlexNet achieved 15.3% top-5 error in 2012, compared to 25.8% for traditional methods, the largest single-year improvement in computer vision.
Algorithmic benchmarks advance AI through several functions. They establish clear performance baselines, enabling objective comparisons between competing approaches. By systematically evaluating trade-offs between model complexity, computational requirements, and task performance, they help researchers and practitioners identify optimal design choices. They track technological progress by documenting improvements over time, guiding the development of new techniques while exposing limitations in existing methodologies.
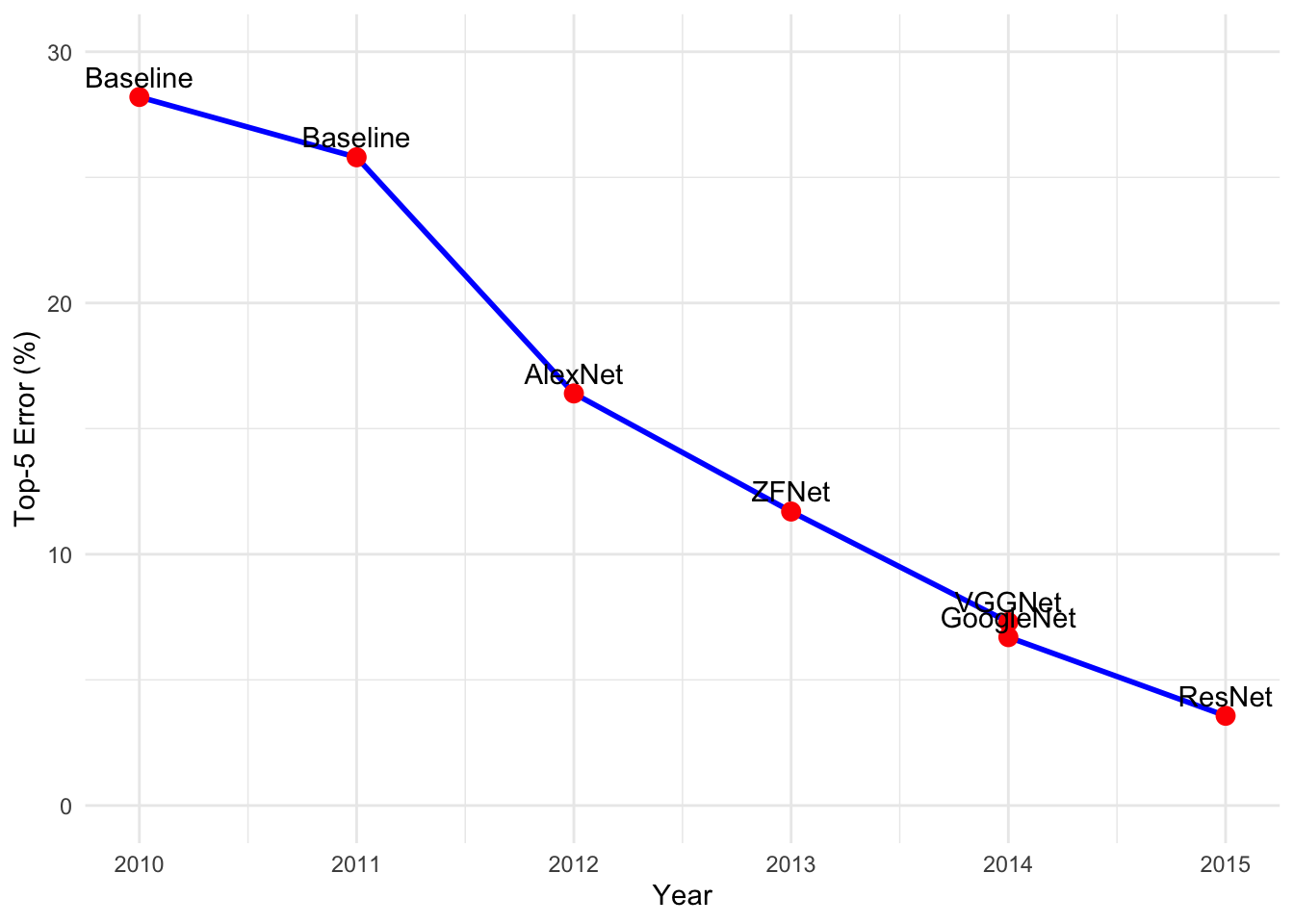
The graph in Figure 1 illustrates the reduction in error rates on the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) classification task over the years. Starting from the baseline models in 2010 and 2011, the introduction of AlexNet5 in 2012 marked an improvement, reducing the error rate from 25.8% to 16.4%. Subsequent models like ZFNet, VGGNet, GoogleNet, and ResNet6 continued this trend, with ResNet achieving an error rate of 3.57% by 2015 (Russakovsky et al. 2015). This progression highlights how algorithmic benchmarks measure current capabilities and drive advancements in AI performance.
5 AlexNet: Developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton at the University of Toronto, this 8-layer neural network revolutionized computer vision in 2012. With 60 million parameters trained on two GTX 580 GPUs, AlexNet introduced key innovations in neural network design that became standard techniques in modern AI.
6 ResNet: Microsoft’s Residual Networks, introduced in 2015 by Kaiming He and colleagues, solved the vanishing gradient problem with skip connections, enabling networks with 152+ layers. ResNet-50 became the de facto standard for transfer learning, while ResNet-152 achieved superhuman performance on ImageNet with 3.57% top-5 error, exceeding the estimated 5% human error rate.
Russakovsky, Olga, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, et al. 2015. “ImageNet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision 115 (3): 211–52. https://doi.org/10.1007/s11263-015-0816-y.
System Benchmarks
Moving to the second dimension of our framework, we address hardware performance: how efficiently different computational systems execute machine learning workloads. System benchmarks measure the computational foundation that enables algorithmic capabilities, systematically examining how hardware architectures, memory systems, and interconnects affect overall performance. Understanding these hardware limitations and capabilities proves necessary for optimizing the algorithm-system interaction.
AI computations place significant demands on computational resources, far exceeding traditional computing workloads. The underlying hardware infrastructure, encompassing general-purpose CPUs, graphics processing units (GPUs), tensor processing units (TPUs)7, and application-specific integrated circuits (ASICs)8, determines the speed, efficiency, and scalability of AI solutions. System benchmarks establish standardized methodologies for evaluating hardware performance across AI workloads, measuring metrics including computational throughput, memory bandwidth, power efficiency, and scaling characteristics (Reddi et al. 2019; Mattson et al. 2020).
7 Tensor Processing Unit (TPU): Google’s custom ASIC designed specifically for neural network workloads, first deployed secretly in 2015 and announced in 2016. The first-generation TPU achieved 15-30x better performance per watt than contemporary GPUs for inference, while TPU v4 pods deliver 1.1 exaFLOPS of BF16 computing power (full pod configuration), demonstrating the capabilities of specialized AI hardware.
8 Application-Specific Integrated Circuit (ASIC): Custom chips designed for specific computational tasks, offering superior performance and energy efficiency compared to general-purpose processors. AI ASICs like Google’s TPUs, Tesla’s FSD chips, and Bitcoin mining ASICs can achieve 100-1000x better efficiency than CPUs for their target applications, but lack the flexibility for other workloads.
Mattson, Peter, Vijay Janapa Reddi, Christine Cheng, Cody Coleman, Greg Diamos, David Kanter, Paulius Micikevicius, et al. 2020. “MLPerf: An Industry Standard Benchmark Suite for Machine Learning Performance.” IEEE Micro 40 (2): 8–16. https://doi.org/10.1109/mm.2020.2974843.
These system benchmarks perform two critical functions in the AI ecosystem. First, they enable developers and organizations to make informed decisions when selecting hardware platforms for their AI applications by providing comparative performance data across system configurations. Evaluation factors include training speed, inference latency, energy efficiency, and cost-effectiveness. Second, hardware manufacturers rely on these benchmarks to quantify generational improvements and guide the development of specialized AI accelerators, driving advancement in computational capabilities.
However, effective benchmark interpretation requires deep understanding of the performance characteristics inherent to target hardware. Critically, understanding whether specific AI workloads are compute-bound or memory-bound provides essential insight for optimization decisions. Computational intensity, measured as FLOPS9 per byte of data movement, determines performance limits. Consider an NVIDIA A100 GPU with 312 TFLOPS of tensor performance and 1.6 TB/s memory bandwidth, yielding an arithmetic intensity threshold of 195 FLOPS/byte. The architectural foundations for understanding these hardware characteristics are established in Chapter 11: AI Acceleration, which provides context for interpreting system benchmark results.
9 FLOPS: Floating-Point Operations Per Second, a measure of computational performance indicating how many floating-point calculations a processor can execute in one second. Modern AI accelerators achieve high FLOPS ratings: NVIDIA A100 delivers 312 TFLOPS (trillion FLOPS) for tensor operations, while high-end CPUs achieve 1-10 TFLOPS. FLOPS measurements help compare hardware capabilities and determine computational bottlenecks in ML workloads.
Choquette, Jack, Wishwesh Gandhi, Olivier Giroux, Nick Stam, and Ronny Krashinsky. 2021. “NVIDIA A100 Tensor Core GPU: Performance and Innovation.” IEEE Micro 41 (2): 29–35. https://doi.org/10.1109/mm.2021.3061394.
High-intensity operations like dense matrix multiplication in certain AI model operations (typically >200 FLOPS/byte) achieve near-peak computational throughput on the A100. For example, a ResNet-50 forward pass on large batch sizes (256+) achieves arithmetic intensity of ~300 FLOPS/byte, enabling 85-90% of peak tensor performance (approximately 280 TFLOPS achieved vs 312 TFLOPS theoretical) (Choquette et al. 2021). Conversely, low-intensity operations like activation functions and certain lightweight operations (<10 FLOPS/byte) become memory bandwidth limited, utilizing only a fraction of the GPU’s computational capacity. A BERT inference with batch size 1 achieves only 8 FLOPS/byte arithmetic intensity, limiting performance to 12.8 TFLOPS (1.6 TB/s × 8 FLOPS/byte), representing just 4% of peak computational capability.
This quantitative analysis, formalized in roofline models10, provides a systematic framework that guides both algorithm design and hardware selection by clearly identifying the dominant performance constraints for specific workloads. Understanding these quantitative relationships allows engineers to predict performance bottlenecks accurately and optimize both model architectures and deployment strategies accordingly. For instance, increasing batch size from 1 to 32 for transformer inference can shift operations from memory-bound (8 FLOPS/byte) to compute-bound (150 FLOPS/byte), improving GPU utilization from 4% to 65% (Pope et al. 2022).
10 Roofline Model: A visual performance model developed at UC Berkeley that plots computational intensity (FLOPS/byte) against performance (FLOPS/second) to identify whether algorithms are compute-bound or memory-bound. The “roofline” represents theoretical peak performance limits, with flat sections indicating memory bandwidth constraints and sloped sections showing compute capacity limits. This model helps optimize both algorithms and hardware selection by revealing performance bottlenecks.
Pope, Reiner, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Anselm Levskaya, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. 2022. “Efficiently Scaling Transformer Inference.” arXiv Preprint arXiv:2211.05102, November. http://arxiv.org/abs/2211.05102v1.
System benchmarks evaluate performance across scales, ranging from single-chip configurations to large distributed systems, and AI workloads including both training and inference tasks. This evaluation approach ensures that benchmarks accurately reflect real-world deployment scenarios and deliver insights that inform both hardware selection decisions and system architecture design. Figure 2 illustrates the correlation between ImageNet classification error rates and GPU adoption from 2010 to 2014. These results highlight how improved hardware capabilities, combined with algorithmic advances, drove progress in computer vision performance.

The ImageNet example above demonstrates how hardware advances enable algorithmic breakthroughs, but effective system benchmarking requires understanding the nuanced relationship between workload characteristics and hardware utilization. Modern AI systems rarely achieve theoretical peak performance due to complex interactions between computational patterns, memory hierarchies, and system architectures. This reality gap between theoretical and achieved performance shapes how we design meaningful system benchmarks.
Understanding realistic hardware utilization patterns becomes essential for actionable benchmark design. Different AI workloads interact with hardware architectures in distinctly different ways, creating utilization patterns that vary dramatically based on model architecture, batch size, and precision choices. GPU utilization varies from 85% for well-optimized ResNet-50 training with batch size 64 to only 15% with batch size 1 (You et al. 2019) due to insufficient parallelism. Memory bandwidth utilization ranges from 20% for parameter-heavy transformer models to 90% for activation-heavy convolutional networks, directly impacting achievable performance across different precision levels.
You, Yang, Zhao Zhang, Cho-Jui Hsieh, James Demmel, and Kurt Keutzer. 2019. “Scaling SGD Batch Size to 32K for ImageNet Training.” In Proceedings of Machine Learning and Systems.
Energy efficiency considerations add another critical dimension to system benchmarking. Performance per watt varies by three orders of magnitude across computing platforms, making energy efficiency a critical benchmark dimension for production deployments. Utilization significantly impacts efficiency: underutilized GPUs consume disproportionate power while delivering minimal performance, creating substantial efficiency penalties that affect operational costs and environmental impact.
Distributed system performance introduces additional complexity that system benchmarks must capture. Traditional roofline models extend to multi-GPU and multi-node scenarios, but distributed training introduces communication bottlenecks that often dominate performance. Inter-node bandwidth limitations, NUMA topology effects, and network congestion create performance variations that single-node benchmarks cannot reveal.
Production distributed systems face challenges that require specialized benchmarking methodologies addressing real-world deployment scenarios. Network partitions during multi-node training affect gradient synchronization and model consistency, requiring fault tolerance evaluation under partial connectivity conditions. Clock synchronization becomes critical for accurate distributed performance measurement across geographically distributed nodes, where timestamp drift can invalidate benchmark results.
Scaling efficiency measurement reveals critical distributed systems bottlenecks in production ML workloads. Linear scaling efficiency degrades significantly beyond 64-128 nodes for most models due to communication overhead: ResNet-50 training achieves 90% scaling efficiency up to 32 nodes but only 60% efficiency at 128 nodes. Gradient aggregation latency increases quadratically with cluster size in traditional parameter server architectures, while all-reduce communication patterns achieve better scaling but require high-bandwidth interconnects.
Consensus mechanisms for benchmark completion across distributed nodes introduce coordination challenges absent from single-node evaluation. Determining benchmark completion requires distributed agreement on convergence criteria, handling node failures during benchmark execution, and ensuring consistent state across all participating nodes. Byzantine fault tolerance becomes necessary for benchmarks spanning multiple administrative domains or cloud providers.
Network topology effects significantly impact distributed training performance in production environments. InfiniBand interconnects achieve 200 Gbps per link with microsecond latency, enabling near-linear scaling for communication-intensive workloads. Ethernet-based clusters with 100 Gbps links experience 10-100x higher latency, limiting scaling efficiency for gradient-heavy models. NUMA topology within nodes creates memory bandwidth contention that affects local gradient computation before network communication.
Dynamic resource allocation in production distributed systems requires benchmarking frameworks that account for resource heterogeneity and temporal variations. Cloud instances with different memory capacities, CPU speeds, and network bandwidth create load imbalance that degrades overall training performance. Spot instance availability fluctuations require fault-tolerant benchmarking that measures recovery time from node failures and resource scaling responsiveness.
These distributed systems considerations highlight the gap between idealized single-node benchmarks and production deployment realities. Effective distributed ML benchmarking must therefore evaluate communication patterns, fault tolerance, resource heterogeneity, and coordination overhead to guide real-world system design decisions.
These hardware utilization insights directly inform benchmark design principles. Effective system benchmarks must evaluate performance across realistic utilization scenarios rather than focusing solely on peak theoretical capabilities. This approach ensures that benchmark results translate to practical deployment guidance, enabling engineers to make informed decisions about hardware selection, system configuration, and optimization strategies.
This transition from computational infrastructure evaluation naturally leads us to the third and equally critical dimension of comprehensive ML system benchmarking: data quality assessment.
Data Benchmarks
The third dimension of our framework systematically examines data quality, representativeness, and bias in machine learning evaluation. Data benchmarks assess how dataset characteristics affect model performance and reveal critical limitations that may not be apparent from algorithmic or system metrics alone. This dimension is particularly critical because data quality constraints often determine real-world deployment success regardless of algorithmic sophistication or hardware capability.
Data quality, scale, and diversity shape machine learning system performance, directly influencing how effectively algorithms learn and generalize to new situations. To address this dependency, data benchmarks establish standardized datasets and evaluation methodologies that enable consistent comparison of different approaches. These frameworks assess critical aspects of data quality, including domain coverage, potential biases, and resilience to real-world variations in input data (Gebru et al. 2021). The data engineering practices necessary for creating reliable benchmarks are detailed in Chapter 6: Data Engineering, while fairness considerations in benchmark design connect to broader responsible AI principles covered in Chapter 17: Responsible AI.
Gebru, Timnit, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. “Datasheets for Datasets.” Communications of the ACM 64 (12): 86–92. https://doi.org/10.1145/3458723.
Data benchmarks serve an essential function in understanding AI system behavior under diverse data conditions. Through systematic evaluation, they help identify common failure modes, expose critical gaps in data coverage, and reveal underlying biases that could significantly impact model behavior in deployment. By providing common frameworks for data evaluation, these benchmarks enable the AI community to systematically improve data quality and address potential issues before deploying systems in production environments. This proactive approach to data quality assessment has become increasingly critical as AI systems take on more complex and consequential tasks across different domains.
Community-Driven Standardization
Building on our three-dimensional framework, we face a critical challenge created by the proliferation of benchmarks spanning performance, energy efficiency, and domain-specific applications: establishing industry-wide standards. While early computing benchmarks primarily measured simple metrics like processor speed and memory bandwidth, modern benchmarks must evaluate sophisticated aspects of system performance, from complex power consumption profiles to highly specialized application-specific capabilities. This evolution in scope and complexity necessitates comprehensive validation and consensus from the computing community, particularly in rapidly evolving fields like machine learning where performance must be evaluated across multiple interdependent dimensions.
The lasting impact of any benchmark depends critically on its acceptance by the broader research community, where technical excellence alone is insufficient for adoption. Benchmarks developed without broad community input often fail to gain meaningful traction, frequently missing critical metrics that leading research groups consider essential. Successful benchmarks emerge through collaborative development involving academic institutions, industry partners, and domain experts. This inclusive approach ensures benchmarks evaluate capabilities most crucial for advancing the field, while balancing theoretical and practical considerations.
In contrast, benchmarks developed through extensive collaboration among respected institutions carry the authority necessary to drive widespread adoption, while those perceived as advancing particular corporate interests face skepticism and limited acceptance. The remarkable success of ImageNet demonstrates how sustained community engagement through workshops and challenges establishes long-term viability and lasting impact. This community-driven development creates a foundation for formal standardization, where organizations like IEEE and ISO transform these benchmarks into official standards.
The standardization process provides crucial infrastructure for benchmark formalization and adoption. IEEE working groups transform community-developed benchmarking methodologies into formal industry standards, establishing precise specifications for measurement and reporting. The IEEE 2416-2019 standard for system power modeling exemplifies this process, codifying best practices developed through community consensus. Similarly, ISO/IEC technical committees develop international standards for benchmark validation and certification, ensuring consistent evaluation across global research and industry communities. These organizations bridge the gap between community-driven innovation and formal standardization, providing frameworks that enable reliable comparison of results across different institutions and geographic regions.
Successful community benchmarks establish clear governance structures for managing their evolution. Through rigorous version control systems and detailed change documentation, benchmarks maintain backward compatibility while incorporating new advances. This governance includes formal processes for proposing, reviewing, and implementing changes, ensuring that benchmarks remain relevant while maintaining stability. Modern benchmarks increasingly emphasize reproducibility requirements, incorporating automated verification systems and standardized evaluation environments.
Open access accelerates benchmark adoption and ensures consistent implementation. Projects that provide open-source reference implementations, comprehensive documentation, validation suites, and containerized evaluation environments reduce barriers to entry. This standardization enables research groups to evaluate solutions using uniform methods and metrics. Without such coordinated implementation frameworks, organizations might interpret benchmarks inconsistently, compromising result reproducibility and meaningful comparison across studies.
The most successful benchmarks strike a careful balance between academic rigor and industry practicality. Academic involvement ensures theoretical soundness and comprehensive evaluation methodology, while industry participation grounds benchmarks in practical constraints and real-world applications. This balance proves particularly crucial in machine learning benchmarks, where theoretical advances must translate to practical improvements in deployed systems (Patterson et al. 2021). These evaluation methodology principles guide both training and inference benchmark design throughout this chapter.
Community consensus establishes enduring benchmark relevance, while fragmentation impedes scientific progress. Through collaborative development and transparent operation, benchmarks evolve into authoritative standards for measuring advancement. The most successful benchmarks in energy efficiency and domain-specific applications share this foundation of community development and governance, demonstrating how collective expertise and shared purpose create lasting impact in rapidly advancing fields.
Benchmarking Granularity
The three-dimensional framework and measurement foundations established above provide the conceptual structure for benchmarking. However, implementing these principles requires choosing the appropriate level of detail for evaluation, from individual tensor operations to complete ML applications. Just as the optimization techniques from Chapter 10: Model Optimizations operate at different granularities, benchmarks must adapt their evaluation scope to match specific optimization goals. This hierarchical perspective allows practitioners to isolate performance bottlenecks at the micro level or assess system-wide behavior at the macro level.
System level benchmarking provides a structured and systematic approach to assessing a ML system’s performance across various dimensions. Given the complexity of ML systems, we can dissect their performance through different levels of granularity and obtain a comprehensive view of the system’s efficiency, identify potential bottlenecks, and pinpoint areas for improvement. To this end, various types of benchmarks have evolved over the years and continue to persist.
Figure 3 shows the different layers of granularity of an ML system. At the application level, end-to-end benchmarks assess the overall system performance, considering factors like data preprocessing, model training, and inference. While at the model layer, benchmarks focus on assessing the efficiency and accuracy of specific models. This includes evaluating how well models generalize to new data and their computational efficiency during training and inference. Benchmarking can extend to hardware and software infrastructure, examining the performance of individual components like GPUs or TPUs.

Micro Benchmarks
Micro-benchmarks are specialized evaluation tools that assess distinct components or specific operations within a broader machine learning process. These benchmarks isolate individual tasks to provide detailed insights into the computational demands of particular system elements, from neural network layers to optimization techniques to activation functions. For example, micro-benchmarks might measure the time required to execute a convolutional layer in a deep learning model or evaluate the speed of data preprocessing operations that prepare training data.
A key area of micro-benchmarking focuses on tensor operations11, which are the computational core of deep learning. Libraries like cuDNN12 by NVIDIA provide benchmarks for measuring fundamental computations such as convolutions and matrix multiplications across different hardware configurations. These measurements help developers understand how their hardware handles the core mathematical operations that dominate ML workloads.
11 Tensor Operations: Multi-dimensional array computations that form the backbone of neural networks, including matrix multiplication (GEMM), convolution, and element-wise operations. Modern AI accelerators optimize these primitives: NVIDIA’s Tensor Cores can achieve 312 TFLOPS for mixed-precision matrix multiplications (BF16), compared to 15-20 TFLOPS for traditional FP32 computations, representing approximately 15-20x speedup.
12 cuDNN: CUDA Deep Neural Network library, NVIDIA’s GPU-accelerated library of primitives for deep neural networks. Released in 2014, cuDNN provides highly optimized implementations for convolutions, pooling, normalization, and activation layers, delivering up to 10x performance improvements over naive implementations and becoming the de facto standard for GPU-accelerated deep learning.
13 Sigmoid Function: A mathematical activation function S(x) = 1/(1+e^(-x)) that maps any real number to a value between 0 and 1, historically important in early neural networks. Despite being computationally expensive due to exponential operations and suffering from vanishing gradient problems, sigmoid functions remain relevant for binary classification output layers and gates in LSTM cells.
14 Tanh Function: Hyperbolic tangent activation function tanh(x) = (e^x - e(-x))/(ex + e^(-x)) that maps inputs to values between -1 and 1, providing zero-centered outputs unlike sigmoid. While computationally intensive and still subject to vanishing gradients, tanh often performs better than sigmoid in hidden layers due to stronger gradients and symmetric output range.
15 LSTM (Long Short-Term Memory): A type of recurrent neural network architecture introduced by Hochreiter and Schmidhuber in 1997, designed to solve the vanishing gradient problem in traditional RNNs. LSTMs use gates (forget, input, output) to control information flow, enabling them to learn dependencies over hundreds of time steps, making them crucial for sequence modeling before the Transformer era.
Micro-benchmarks also examine activation functions and neural network layers in isolation. This includes measuring the performance of various activation functions like ReLU, Sigmoid13, and Tanh14 under controlled conditions, as well as evaluating the computational efficiency of distinct neural network components such as LSTM15 cells or Transformer blocks when processing standardized inputs.
DeepBench, developed by Baidu, was one of the first to demonstrate the value of comprehensive micro-benchmarking. It evaluates these fundamental operations across different hardware platforms, providing detailed performance data that helps developers optimize their deep learning implementations. By isolating and measuring individual operations, DeepBench enables precise comparison of hardware platforms and identification of potential performance bottlenecks.
Macro Benchmarks
While micro-benchmarks examine individual operations like tensor computations and layer performance, macro benchmarks evaluate complete machine learning models. This shift from component-level to model-level assessment provides insights into how architectural choices and component interactions affect overall model behavior. For instance, while micro-benchmarks might show optimal performance for individual convolutional layers, macro-benchmarks reveal how these layers work together within a complete convolutional neural network.
Macro-benchmarks measure multiple performance dimensions that emerge only at the model level. These include prediction accuracy, which shows how well the model generalizes to new data; memory consumption patterns across different batch sizes and sequence lengths; throughput under varying computational loads; and latency across different hardware configurations. Understanding these metrics helps developers make informed decisions about model architecture, optimization strategies, and deployment configurations.
The assessment of complete models occurs under standardized conditions using established datasets and tasks. For example, computer vision models might be evaluated on ImageNet, measuring both computational efficiency and prediction accuracy. Natural language processing models might be assessed on translation tasks, examining how they balance quality and speed across different language pairs.
Several industry-standard benchmarks enable consistent model evaluation across platforms. MLPerf Inference provides comprehensive testing suites adapted for different computational environments (Reddi et al. 2019). MLPerf Mobile focuses on mobile device constraints (Janapa Reddi et al. 2022), while MLPerf Tiny addresses microcontroller deployments (Banbury et al. 2021). For embedded systems, EEMBC’s MLMark emphasizes both performance and power efficiency. The AI-Benchmark suite specializes in mobile platforms, evaluating models across diverse tasks from image recognition to face parsing.
Janapa Reddi, Vijay et al. 2022. “MLPerf Mobile V2. 0: An Industry-Standard Benchmark Suite for Mobile Machine Learning.” In Proceedings of Machine Learning and Systems, 4:806–23.
Banbury, Colby, Vijay Janapa Reddi, Peter Torelli, Jeremy Holleman, Nat Jeffries, Csaba Kiraly, Pietro Montino, et al. 2021. “MLPerf Tiny Benchmark.” arXiv Preprint arXiv:2106.07597, June. http://arxiv.org/abs/2106.07597v4.
End-to-End Benchmarks
End-to-end benchmarks provide an all-inclusive evaluation that extends beyond the boundaries of the ML model itself. Rather than focusing solely on a machine learning model’s computational efficiency or accuracy, these benchmarks encompass the entire pipeline of an AI system. This includes initial ETL (Extract-Transform-Load) or ELT (Extract-Load-Transform) data processing, the core model’s performance, post-processing of results, and critical infrastructure components like storage and network systems.
Data processing is the foundation of all AI systems, transforming raw data into a format suitable for model training or inference. In ETL pipelines, data undergoes extraction from source systems, transformation through cleaning and feature engineering, and loading into model-ready formats. These preprocessing steps’ efficiency, scalability, and accuracy significantly impact overall system performance. End-to-end benchmarks must assess standardized datasets through these pipelines to ensure data preparation doesn’t become a bottleneck.
The post-processing phase plays an equally important role. This involves interpreting the model’s raw outputs, converting scores into meaningful categories, filtering results based on predefined tasks, or integrating with other systems. For instance, a computer vision system might need to post-process detection boundaries, apply confidence thresholds, and format results for downstream applications. In real-world deployments, this phase proves crucial for delivering actionable insights.
Beyond core AI operations, infrastructure components heavily influence overall performance and user experience. Storage solutions, whether cloud-based, on-premises, or hybrid, can significantly impact data retrieval and storage times, especially with vast AI datasets. Network interactions, vital for distributed systems, can become performance bottlenecks if not optimized. End-to-end benchmarks must evaluate these components under specified environmental conditions to ensure reproducible measurements of the entire system.
To date, there are no public, end-to-end benchmarks that fully account for data storage, network, and compute performance. While MLPerf Training and Inference approach end-to-end evaluation, they primarily focus on model performance rather than real-world deployment scenarios. Nonetheless, they provide valuable baseline metrics for assessing AI system capabilities.
Given the inherent specificity of end-to-end benchmarking, organizations typically perform these evaluations internally by instrumenting production deployments. This allows engineers to develop result interpretation guidelines based on realistic workloads, but given the sensitivity and specificity of the information, these benchmarks rarely appear in public settings.
Granularity Trade-offs and Selection Criteria
As shown in Table 1, different challenges emerge at different stages of an AI system’s lifecycle. Each benchmarking approach provides unique insights: micro-benchmarks help engineers optimize specific components like GPU kernel implementations or data loading operations, macro-benchmarks guide model architecture decisions and algorithm selection, while end-to-end benchmarks reveal system-level bottlenecks in production environments.
| Component | Micro Benchmarks | Macro Benchmarks | End-to-End Benchmarks |
|---|---|---|---|
| Focus | Individual operations | Complete models | Full system pipeline |
| Scope | Tensor ops, layers, activations | Model architecture, training, inference | ETL, model, infrastructure |
| Example | Conv layer performance on cuDNN | ResNet-50 on ImageNet | Production recommendation system |
| Advantages | Precise bottleneck identification, Component optimization | Model architecture comparison, Standardized evaluation | Realistic performance assessment, System-wide insights |
| Challenges | May miss interaction effects | Limited infrastructure insights | Complex to standardize, Often proprietary |
| Typical Use | Hardware selection, Operation optimization | Model selection, Research comparison | Production system evaluation |
Figure 4 visualizes the core trade-off between diagnostic power and real-world representativeness across benchmark granularity levels. This relationship illustrates why comprehensive ML system evaluation requires multiple benchmark types: micro-benchmarks provide precise optimization guidance for isolated components, while end-to-end benchmarks capture the complex interactions that emerge in production systems. The optimal benchmarking strategy combines insights from all three levels to balance detailed component analysis with realistic system-wide assessment.

Component interaction often produces unexpected behaviors. For example, while micro-benchmarks might show excellent performance for individual convolutional layers, and macro-benchmarks might demonstrate strong accuracy for the complete model, end-to-end evaluation could reveal that data preprocessing creates unexpected bottlenecks during high-traffic periods. These system-level insights often remain hidden when components undergo isolated testing.
With benchmarking granularity established, understanding which level of evaluation serves specific optimization goals, we now examine the concrete components that constitute benchmark implementations at any granularity level.
Benchmark Components
Using our established framework, we now examine the practical components that constitute any benchmark implementation. These components provide the concrete structure for measuring performance across all three dimensions simultaneously. Whether evaluating model accuracy (algorithmic dimension), measuring inference latency (system dimension), or assessing dataset quality (data dimension), benchmarks share common structural elements that ensure systematic and reproducible evaluation.
The granularity level established in the previous section directly shapes how these components are instantiated. Micro-benchmarks measuring tensor operations require synthetic inputs that isolate specific computational patterns, enabling precise performance characterization of individual kernels as discussed in Chapter 11: AI Acceleration. Macro-benchmarks evaluating complete models demand representative datasets like ImageNet that capture realistic task complexity while enabling standardized comparison across architectures. End-to-end benchmarks assessing production systems must incorporate real-world data characteristics including distribution shift, noise, and edge cases absent from curated evaluation sets. Similarly, evaluation metrics shift focus across granularity levels: micro-benchmarks emphasize FLOPS and memory bandwidth utilization, macro-benchmarks balance accuracy and inference speed, while end-to-end benchmarks prioritize system reliability and operational efficiency under load. Understanding this systematic variation ensures that component choices align with evaluation objectives rather than applying uniform approaches across different benchmarking scales.
Having established how benchmark granularity shapes evaluation scope (from micro-benchmarks isolating tensor operations to end-to-end assessments of complete systems), we now examine how these conceptual levels translate into concrete benchmark implementations. The components discussed abstractly above must be instantiated through specific choices about tasks, datasets, models, and metrics. This implementation process follows a systematic workflow that ensures reproducible and meaningful evaluation regardless of the chosen granularity level.
An AI benchmark provides this structured framework for systematically evaluating artificial intelligence systems. While individual benchmarks vary significantly in their specific focus and granularity, they share common implementation components that enable consistent evaluation and comparison across different approaches.
Figure 5 illustrates this structured workflow, showcasing how the essential components (task definition, dataset selection, model selection, and evaluation metrics) interconnect to form a complete evaluation pipeline. Each component builds upon the previous one, creating a systematic progression from problem specification through deployment assessment.

Effective benchmark design must account for the optimization techniques established in preceding chapters. Quantization and pruning affect model accuracy-efficiency trade-offs, requiring benchmarks that measure both speedup and accuracy preservation simultaneously. Hardware acceleration techniques influence arithmetic intensity and memory bandwidth utilization, necessitating roofline model analysis to interpret results correctly. Understanding these optimization foundations enables benchmark selection that validates claimed improvements rather than measuring artificial scenarios.
Problem Definition
As illustrated in Figure 5, a benchmark implementation begins with a formal specification of the machine learning task and its evaluation criteria. In machine learning, tasks represent well-defined problems that AI systems must solve. Consider an anomaly detection system that processes audio signals to identify deviations from normal operation patterns, as shown in Figure 5. This industrial monitoring application exemplifies how formal task specifications translate into practical implementations.
The formal definition of any benchmark task encompasses both the computational problem and its evaluation framework. While the specific tasks vary significantly by domain, well-established categories have emerged across major fields of AI research. Natural language processing tasks, for example, include machine translation, question answering (Hirschberg and Manning 2015), and text classification. Computer vision similarly employs standardized tasks such as object detection, image segmentation, and facial recognition (Everingham et al. 2009).
Hirschberg, Julia, and Christopher D. Manning. 2015. “Advances in Natural Language Processing.” Science 349 (6245): 261–66. https://doi.org/10.1126/science.aaa8685.
Everingham, Mark, Luc Van Gool, Christopher K. I. Williams, John Winn, and Andrew Zisserman. 2009. “The Pascal Visual Object Classes (VOC) Challenge.” International Journal of Computer Vision 88 (2): 303–38. https://doi.org/10.1007/s11263-009-0275-4.
Every benchmark task specification must define three essential elements. The input specification determines what data the system processes. In Figure 5, this consists of audio waveform data. The output specification describes the required system response, such as the binary classification of normal versus anomalous patterns. The performance specification establishes quantitative requirements for accuracy, processing speed, and resource utilization.
Task design directly impacts the benchmark’s ability to evaluate AI systems effectively. The audio anomaly detection example clearly illustrates this relationship through its specific requirements: processing continuous signal data, adapting to varying noise conditions, and operating within strict time constraints. These practical constraints create a detailed framework for assessing model performance, ensuring evaluations reflect real-world operational demands.
The implementation of a benchmark proceeds systematically from this foundational task definition. Each subsequent phase, from dataset selection through deployment, builds directly upon these initial specifications, ensuring that evaluations maintain consistency while addressing the defined requirements across different approaches and implementations.
Standardized Datasets
Building directly upon the problem definition established in the previous phase, standardized datasets provide the essential foundation for training and evaluating models. These carefully curated collections ensure all models undergo testing under identical conditions, enabling direct comparisons across different approaches and architectures. Figure 5 demonstrates this through an audio anomaly detection example, where waveform data serves as the standardized input for evaluating detection performance.
In computer vision, datasets such as ImageNet (Deng et al. 2009), COCO (Lin et al. 2014), and CIFAR-1016 (Krizhevsky, Hinton, et al. 2009) serve as reference standards. For natural language processing, collections such as SQuAD17 (Rajpurkar et al. 2016), GLUE18 (Wang et al. 2018), and WikiText (Merity et al. 2016) fulfill similar functions. These datasets encompass a range of complexities and edge cases to thoroughly evaluate machine learning systems.
16 CIFAR-10: A dataset of 60,000 32×32 color images across 10 classes (airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck), collected by Alex Krizhevsky and Geoffrey Hinton at the University of Toronto in 2009. Despite its small image size, CIFAR-10 became fundamental for comparing deep learning architectures, with top-1 error rates improving from 18.5% with traditional methods to 2.6% with modern deep networks.
Krizhevsky, Alex, Geoffrey Hinton, et al. 2009. “Learning Multiple Layers of Features from Tiny Images.”
17 SQuAD: Stanford Question Answering Dataset, introduced in 2016, containing 100,000+ question-answer pairs based on Wikipedia articles. SQuAD became the gold standard for evaluating reading comprehension, with human performance at 87.4% F1 score and leading AI systems achieving over 90% by 2018, marking the first time machines exceeded human performance on this benchmark.
Rajpurkar, Pranav, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. “SQuAD: 100,000+ Questions for Machine Comprehension of Text.” arXiv Preprint arXiv:1606.05250, June, 2383–92. https://doi.org/10.18653/v1/d16-1264.
18 GLUE: General Language Understanding Evaluation, a collection of nine English sentence understanding tasks including sentiment analysis, textual entailment, and similarity. Introduced in 2018, GLUE provided standardized evaluation with a human baseline of 87.1% and became obsolete when BERT achieved 80.5% in 2019, leading to the more challenging SuperGLUE benchmark.
Merity, Stephen, Caiming Xiong, James Bradbury, and Richard Socher. 2016. “Pointer Sentinel Mixture Models.” arXiv Preprint arXiv:1609.07843, September. http://arxiv.org/abs/1609.07843v1.
The strategic selection of datasets, shown early in the workflow of Figure 5, shapes all subsequent implementation steps and ultimately determines the benchmark’s effectiveness. In the audio anomaly detection example, the dataset must include representative waveform samples of normal operation alongside comprehensive examples of various anomalous conditions. Notable examples include datasets like ToyADMOS for industrial manufacturing anomalies and Google Speech Commands for general sound recognition. Regardless of the specific dataset chosen, the data volume must suffice for both model training and validation, while incorporating real-world signal characteristics and noise patterns that reflect deployment conditions.
The selection of benchmark datasets directly shapes experimental outcomes and model evaluation. Effective datasets must balance two key requirements: accurately representing real-world challenges while maintaining sufficient complexity to differentiate model performance meaningfully. While research often utilizes simplified datasets like ToyADMOS19 (Koizumi et al. 2019), these controlled environments, though valuable for methodological development, may not fully capture real-world deployment complexities.
19 ToyADMOS: A dataset for anomaly detection in machine operating sounds, developed by NTT Communications in 2019 containing audio recordings from toy car and toy conveyor belt operations. The dataset includes 1,000+ normal samples and 300+ anomalous samples per machine type, designed to standardize acoustic anomaly detection research with reproducible experimental conditions.
Koizumi, Yuma, Shoichiro Saito, Hisashi Uematsu, Noboru Harada, and Keisuke Imoto. 2019. “ToyADMOS: A Dataset of Miniature-Machine Operating Sounds for Anomalous Sound Detection.” In 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 313–17. IEEE; IEEE. https://doi.org/10.1109/waspaa.2019.8937164.
Model Selection
Following dataset specification, the benchmark process advances systematically to model architecture selection and implementation. This critical phase establishes performance baselines and determines the optimal modeling approach for the specific task at hand. The selection process directly builds upon the architectural foundations established in Chapter 4: DNN Architectures and must account for the framework-specific considerations discussed in Chapter 7: AI Frameworks. Figure 5 illustrates this progression through the model selection stage and subsequent training code development.
Baseline models serve as the reference points for evaluating novel approaches. These span from basic implementations, including linear regression for continuous predictions and logistic regression for classification tasks, to advanced architectures with proven success in comparable domains. The choice of baseline depends critically on the deployment framework—a PyTorch implementation may exhibit different performance characteristics than its TensorFlow equivalent due to framework-specific optimizations and operator implementations. In natural language processing applications, advanced language models like BERT20 have emerged as standard benchmarks for comparative analysis. The architectural details of transformers and their performance characteristics are thoroughly covered in Chapter 4: DNN Architectures.
20 BERT: Bidirectional Encoder Representations from Transformers, introduced by Google in 2018, revolutionized natural language processing by pre-training on vast text corpora using masked language modeling. BERT-Large contains 340 million parameters and achieved state-of-the-art results on 11 NLP tasks, establishing the foundation for modern language models like GPT and ChatGPT.
Selecting the right baseline model requires careful evaluation of architectures against benchmark requirements. This selection process directly informs the development of training code, which is the cornerstone of benchmark reproducibility. The training implementation must thoroughly document all aspects of the model pipeline, from data preprocessing through training procedures, enabling precise replication of model behavior across research teams.
With model architecture selected, model development follows two primary optimization paths: training and inference. During training optimization, efforts concentrate on achieving target accuracy metrics while operating within computational constraints. The training implementation must demonstrate consistent achievement of performance thresholds under specified conditions.
In parallel, the inference optimization path addresses deployment considerations, particularly the critical transition from development to production environments. A key example involves precision reduction through numerical optimization techniques, progressing from high-precision to lower-precision representations to enhance deployment efficiency. This process demands careful calibration to maintain model accuracy while reducing resource requirements. The benchmark must detail both the quantization methodology and verification procedures that confirm preserved performance.
The intersection of these two optimization paths with real-world constraints shapes overall deployment strategy. Comprehensive benchmarks must therefore specify requirements for both training and inference scenarios, ensuring models maintain consistent performance from development through deployment. This crucial connection between development and production metrics naturally leads to the establishment of evaluation criteria.
The optimization process must balance four key objectives: model accuracy, computational speed, memory utilization, and energy efficiency. Following our three-dimensional benchmarking framework, this complex optimization landscape necessitates robust evaluation metrics that can effectively quantify performance across algorithmic, system, and data dimensions. As models transition from development to deployment, these metrics serve as critical tools for guiding optimization decisions and validating performance enhancements.
Evaluation Metrics
Building upon the optimization framework established through model selection, evaluation metrics provide the quantitative measures needed to assess machine learning model performance. These metrics establish objective standards for comparing different approaches, allowing researchers and practitioners to gauge solution effectiveness. The selection of appropriate metrics represents a critical aspect of benchmark design, as they must align with task objectives while providing meaningful insights into model behavior across both training and deployment scenarios. Importantly, metric computation can vary between frameworks—the training methodologies from Chapter 8: AI Training demonstrate how different frameworks handle loss computation and gradient accumulation differently, affecting reported metrics.
Task-specific metrics quantify a model’s performance on its intended function. For example, classification tasks employ metrics including accuracy (overall correct predictions), precision (positive prediction accuracy), recall (positive case detection rate), and F1 score (precision-recall harmonic mean) (Sokolova and Lapalme 2009). Regression problems utilize error measurements like Mean Squared Error (MSE) and Mean Absolute Error (MAE) to assess prediction accuracy. Domain-specific applications often require specialized metrics - for example, machine translation uses the BLEU score21 to evaluate the semantic and syntactic similarity between machine-generated and human reference translations (Papineni et al. 2001).
Sokolova, Marina, and Guy Lapalme. 2009. “A Systematic Analysis of Performance Measures for Classification Tasks.” Information Processing &Amp; Management 45 (4): 427–37. https://doi.org/10.1016/j.ipm.2009.03.002.
21 BLEU Score: Bilingual Evaluation Understudy, introduced by IBM in 2002, measures machine translation quality by comparing n-gram overlap between machine and human reference translations. BLEU scores range from 0-100, with scores above 30 considered useful, above 50 good, and above 60 high quality. Google Translate achieved BLEU scores of 40+ on major language pairs by 2016.
Papineni, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2001. “BLEU: A Method for Automatic Evaluation of Machine Translation.” In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics - ACL ’02, 311. Association for Computational Linguistics. https://doi.org/10.3115/1073083.1073135.
However, as models transition from research to production deployment, implementation metrics become equally important. Model size, measured in parameters or memory footprint, directly affects deployment feasibility across different hardware platforms. Processing latency, typically measured in milliseconds per inference, determines whether the model meets real-time requirements. Energy consumption, measured in watts or joules per inference, indicates operational efficiency. These practical considerations reflect the growing need for solutions that balance accuracy with computational efficiency. The operational challenges of maintaining these metrics in production environments are explored in deployment strategies (Chapter 13: ML Operations).
Consequently, the selection of appropriate metrics requires careful consideration of both task requirements and deployment constraints. A single metric rarely captures all relevant aspects of performance in real-world scenarios. For instance, in anomaly detection systems, high accuracy alone may not indicate good performance if the model generates frequent false alarms. Similarly, a fast model with poor accuracy fails to provide practical value.
Figure 5 demonstrates this multi-metric evaluation approach. The anomaly detection system reports performance across multiple dimensions: model size (270 Kparameters), processing speed (10.4 ms/inference), and detection accuracy (0.86 AUC22). This combination of metrics ensures the model meets both technical and operational requirements in real-world deployment scenarios.
22 AUC (Area Under the Curve): A performance metric for binary classification that measures the area under the Receiver Operating Characteristic (ROC) curve, representing the trade-off between true positive and false positive rates. AUC values range from 0 to 1, where 0.5 indicates random performance, 0.7-0.8 is acceptable, 0.8-0.9 is excellent, and above 0.9 is outstanding discrimination ability.
Benchmark Harness
While evaluation metrics provide the measurement framework, a benchmark harness implements the systematic infrastructure for evaluating model performance under controlled conditions. This critical component ensures reproducible testing by managing how inputs are delivered to the system under test and how measurements are collected, effectively transforming theoretical metrics into quantifiable measurements.
The harness design should align with the intended deployment scenario and usage patterns. For server deployments, the harness implements request patterns that simulate real-world traffic, typically generating inputs using a Poisson distribution23 to model random but statistically consistent server workloads. The harness manages concurrent requests and varying load intensities to evaluate system behavior under different operational conditions.
23 Poisson Distribution: A mathematical model that describes the frequency of events occurring independently at a constant average rate, named after French mathematician Siméon Denis Poisson in 1837. In server workloads, Poisson distributions accurately model request arrivals with average rates of 10-1000 requests per second, where the probability of exactly k requests in time t follows P(k) = (λt)^k * e^(-λt) / k!.
For embedded and mobile applications, the harness generates input patterns that reflect actual deployment conditions. This might involve sequential image injection for mobile vision applications or synchronized multi-sensor streams for autonomous systems. Such precise input generation and timing control ensures the system experiences realistic operational patterns, revealing performance characteristics that would emerge in actual device deployment.
The harness must also accommodate different throughput models. Batch processing scenarios require the ability to evaluate system performance on large volumes of parallel inputs, while real-time applications need precise timing control for sequential processing. Figure 5 illustrates this in the embedded implementation phase, where the harness must support precise measurement of inference time and energy consumption per operation.
Reproducibility demands that the harness maintain consistent testing conditions across different evaluation runs. This includes controlling environmental factors such as background processes, thermal conditions, and power states that might affect performance measurements. The harness must also provide mechanisms for collecting and logging performance metrics without significantly impacting the system under test.
System Specifications
Complementing the benchmark harness that controls test execution, system specifications are fundamental components of machine learning benchmarks that directly impact model performance, training time, and experimental reproducibility. These specifications encompass the complete computational environment, ensuring that benchmarking results can be properly contextualized, compared, and reproduced by other researchers.
Hardware specifications typically include:
- Processor type and speed (e.g., CPU model, clock rate)
- GPUs, or TPUs, including model, memory capacity, and quantity if used for distributed training
- Memory capacity and type (e.g., RAM size, DDR4)
- Storage type and capacity (e.g., SSD, HDD)
- Network configuration, if relevant for distributed computing
Software specifications generally include:
- Operating system and version
- Programming language and version
- Machine learning frameworks and libraries (e.g., TensorFlow, PyTorch) with version numbers
- Compiler information and optimization flags
- Custom software or scripts used in the benchmark process
- Environment management tools and configuration (e.g., Docker containers24, virtual environments)
24 Docker: Containerization platform that packages applications and their dependencies into lightweight, portable containers ensuring consistent execution across different environments. Widely adopted in ML benchmarking since 2013, Docker eliminates “works on my machine” problems by providing identical runtime environments, with MLPerf and other benchmark suites distributing official Docker images to guarantee reproducible results.
The precise documentation of these specifications is essential for experimental validity and reproducibility. This documentation enables other researchers to replicate the benchmark environment with high fidelity, provides critical context for interpreting performance metrics, and facilitates understanding of resource requirements and scaling characteristics across different models and tasks.
In many cases, benchmarks may include results from multiple hardware configurations to provide a more comprehensive view of model performance across different computational environments. This approach is particularly valuable as it highlights the trade-offs between model complexity, computational resources, and performance.
As the field evolves, hardware and software specifications increasingly incorporate detailed energy consumption metrics and computational efficiency measures, such as FLOPS/watt and total power usage over training time. This expansion reflects growing concerns about the environmental impact of large-scale machine learning models and supports the development of more sustainable AI practices. Comprehensive specification documentation thus serves multiple purposes: enabling reproducibility, supporting fair comparisons, and advancing both the technical and environmental aspects of machine learning research.
Run Rules
Beyond the technical infrastructure, run rules establish the procedural framework that ensures benchmark results can be reliably replicated by researchers and practitioners, complementing the technical environment defined by system specifications. These guidelines are essential for validating research claims, building upon existing work, and advancing machine learning. Central to reproducibility in AI benchmarks is the management of controlled randomness, the systematic handling of stochastic processes such as weight initialization and data shuffling that ensures consistent, verifiable results.
Comprehensive documentation of hyperparameters forms a critical component of reproducibility. Hyperparameters are configuration settings that control how models learn, such as learning rates and batch sizes, which must be documented for reproducibility. Given that minor hyperparameter adjustments can significantly impact model performance, their precise documentation is essential. Benchmarks mandate the preservation and sharing of training and evaluation datasets. When direct data sharing is restricted by privacy or licensing constraints, benchmarks must provide detailed specifications for data preprocessing and selection criteria, enabling researchers to construct comparable datasets or understand the characteristics of the original experimental data.
Code provenance and availability constitute another vital aspect of reproducibility guidelines. Contemporary benchmarks typically require researchers to publish implementation code in version-controlled repositories, encompassing not only the model implementation but also comprehensive scripts for data preprocessing, training, and evaluation. Advanced benchmarks often provide containerized environments that encapsulate all dependencies and configurations. Detailed experimental logging is mandatory, including systematic recording of training metrics, model checkpoints, and documentation of any experimental adjustments.
These reproducibility guidelines serve multiple crucial functions: they enhance transparency, enable rigorous peer review, and accelerate scientific progress in AI research. By following these protocols, the research community can effectively verify results, iterate on successful approaches, and identify methodological limitations. In the rapidly evolving landscape of machine learning, these robust reproducibility practices form the foundation for reliable and progressive research.
Result Interpretation
Building on the foundation established by run rules, result interpretation guidelines provide the essential framework for understanding and contextualizing benchmark outcomes. These guidelines help researchers and practitioners draw meaningful conclusions from benchmark results, ensuring fair and informative comparisons between different models or approaches. A critical aspect is understanding the statistical significance of performance differences. Benchmarks typically specify protocols for conducting statistical tests and reporting confidence intervals, enabling practitioners to distinguish between meaningful improvements and variations attributable to random factors.
However, result interpretation requires careful consideration of real-world applications and context. While a 1% improvement in accuracy might be crucial for medical diagnostics or financial systems, other applications might prioritize inference speed or model efficiency over marginal accuracy gains. Understanding these context-specific requirements is essential for meaningful interpretation of benchmark results. Users must also recognize inherent benchmark limitations, as no single evaluation framework can encompass all possible use cases. Common limitations include dataset biases, task-specific characteristics, and constraints of evaluation metrics.
Modern benchmarks often necessitate multi-dimensional analysis across various performance metrics. For instance, when a model demonstrates superior accuracy but requires substantially more computational resources, interpretation guidelines help practitioners evaluate these trade-offs based on their specific constraints and requirements. The guidelines also address the critical issue of benchmark overfitting, where models might be excessively optimized for specific benchmark tasks at the expense of real-world generalization. To mitigate this risk, guidelines often recommend evaluating model performance on related but distinct tasks and considering practical deployment scenarios.
These comprehensive interpretation frameworks ensure that benchmarks serve their intended purpose: providing standardized performance measurements while enabling nuanced understanding of model capabilities. This balanced approach supports evidence-based decision-making in both research contexts and practical machine learning applications.
Example Benchmark
To illustrate how these components work together in practice, a complete benchmark run evaluates system performance by synthesizing multiple components under controlled conditions to produce reproducible measurements. Figure 5 illustrates this integration through an audio anomaly detection system. It shows how performance metrics are systematically measured and reported within a framework that encompasses problem definition, datasets, model selection, evaluation criteria, and standardized run rules.
The benchmark measures several key performance dimensions. For computational resources, the system reports a model size of 270 Kparameters and requires 10.4 milliseconds per inference. For task effectiveness, it achieves a detection accuracy of 0.86 AUC (Area Under Curve) in distinguishing normal from anomalous audio patterns. For operational efficiency, it consumes 516 µJ of energy per inference.
The relative importance of these metrics varies by deployment context. Energy consumption per inference is critical for battery-powered devices but less consequential for systems with constant power supply. Model size constraints differ significantly between cloud deployments with abundant resources and embedded devices with limited memory. Processing speed requirements depend on whether the system must operate in real-time or can process data in batches.
The benchmark reveals inherent trade-offs between performance metrics in machine learning systems. For instance, reducing the model size from 270 Kparameters might improve processing speed and energy efficiency but could decrease the 0.86 AUC detection accuracy. Figure 5 illustrates how these interconnected metrics contribute to overall system performance in the deployment phase.
Ultimately, whether these measurements constitute a “passing” benchmark depends on the specific requirements of the intended application. The benchmark framework provides the structure and methodology for consistent evaluation, while the acceptance criteria must align with deployment constraints and performance requirements.
Compression Benchmarks
Extending beyond general benchmarking principles, as machine learning models continue to grow in size and complexity, neural network compression has emerged as a critical optimization technique for deployment across resource-constrained environments. Compression benchmarking methodologies evaluate the effectiveness of techniques including pruning, quantization, knowledge distillation, and architecture optimization. These specialized benchmarks measure the core trade-offs between model size reduction, accuracy preservation, and computational efficiency improvements.
Model compression benchmarks assess multiple dimensions simultaneously. The primary dimension involves size reduction metrics that evaluate parameters (counting), memory footprint (bytes), and storage requirements (compressed file size). Effective compression achieves significant reduction while maintaining accuracy: MobileNetV2 achieves approximately 72% ImageNet top-1 accuracy with 3.4 million parameters versus ResNet-50’s 76% accuracy with 25.6 million parameters, representing a 7.5x efficiency improvement in the parameter-to-accuracy ratio.
Beyond basic size metrics, sparsity evaluation frameworks distinguish between structured and unstructured pruning efficiency. Structured pruning removes entire neurons or filters, achieving consistent speedups but typically lower compression ratios (2-4x). Unstructured pruning eliminates individual weights, achieving higher compression ratios (10-100x) but requiring specialized sparse computation support for speedup realization. Benchmark protocols must specify hardware platform and software implementation to ensure meaningful sparse acceleration measurements.
Complementing sparsity techniques, quantization benchmarking protocols evaluate precision reduction techniques across multiple data types. INT8 quantization typically provides 4x memory reduction and 2-4x inference speedup while maintaining 99%+ accuracy preservation for most computer vision models. Mixed-precision approaches achieve optimal efficiency by applying different precision levels to different layers: critical layers retain FP16 precision while computation-heavy layers utilize INT8 or INT4, enabling fine-grained efficiency optimization.
Another critical dimension involves knowledge transfer effectiveness metrics that measure performance relationships between different model sizes. Successful knowledge transfer achieves 90-95% of larger model accuracy while reducing model size by 5-10x. Compact models can demonstrate this approach, achieving high performance with significantly fewer parameters and faster inference, illustrating the potential for efficiency without significant capability loss.
Finally, acceleration factor measurements for optimized models reveal the practical benefits across different hardware platforms. Optimized models achieve varying speedup factors: sparse models deliver 2-5x speedup on CPUs, reduced-precision models achieve 2-8x speedup on mobile processors, and efficient architectures provide 5-20x speedup on specialized edge accelerators. These hardware-specific measurements ensure efficiency benchmarks reflect real deployment scenarios.
Efficiency-aware benchmarking addresses critical gaps in traditional evaluation frameworks. Current benchmark suites like MLPerf focus primarily on dense, unoptimized models that do not represent production deployments, where optimized models are ubiquitous. Future benchmarking frameworks should include efficiency model divisions specifically evaluating optimized architectures, reduced-precision inference, and compact models to accurately reflect real deployment practices and guide efficiency research toward practical impact.
Mobile and Edge Benchmarks
Mobile SoCs integrate heterogeneous processors (CPU, GPU, DSP, NPU) requiring specialized benchmarking that captures workload distribution complexity while accounting for thermal and battery constraints. Effective processor coordination achieves 3-5x performance improvements, but sustained workloads trigger thermal throttling. Snapdragon 8 Gen 3 drops from 35 TOPS peak to 20 TOPS sustained. Battery impact varies dramatically: computational photography consumes 2-5W while background AI requires 5-50mW for acceptable endurance.
Mobile benchmarking must also evaluate 5G/WiFi edge-cloud coordination, with URLLC25 demanding <1ms latency for critical applications. Automotive deployments add ASIL validation, multi-sensor fusion, and -40°C to +85°C environmental testing. These unique requirements necessitate comprehensive frameworks evaluating sustained performance under thermal constraints, battery efficiency across usage patterns, and connectivity-dependent behavior, extending beyond isolated peak measurements.
25 URLLC: 5G service category requiring 99.999% reliability and <1ms latency for mission-critical applications.
Training vs. Inference Evaluation
The benchmark components and granularity levels apply differently to ML systems’ two primary operational phases: training and inference. While both phases process data through neural networks, their contrasting objectives create distinct benchmarking requirements. The training methodologies from Chapter 8: AI Training focus on iterative optimization over large datasets, while deployment strategies from Chapter 13: ML Operations prioritize consistent, low-latency serving. These differences cascade through metric selection, resource allocation, and scaling behavior.
Training involves iterative optimization with bidirectional computation (forward and backward passes), while inference performs single forward passes with fixed model parameters. ResNet-50 training requires 8GB GPU memory for gradients and optimizer states compared to 0.5GB for inference-only forward passes. Training GPT-3 utilized 1024 A100 GPUs for months, while inference deploys single models across thousands of concurrent requests with millisecond response requirements.
Training prioritizes throughput and convergence speed, measured in samples processed per unit time and training completion time. BERT-Large training achieves optimal performance at batch size 512 with 32-hour convergence time, while BERT inference optimizes for <10ms latency per query with batch size 1-4. Training can sacrifice latency for throughput (processing 10,000 samples/second), while inference sacrifices throughput for latency consistency.
Training can leverage extensive computational resources with batch processing, accepting longer completion times for better resource efficiency. Multi-node training scales efficiently with batch sizes 4096-32,768, achieving 90% compute utilization. Inference must respond to individual requests with minimal latency, constraining batch sizes to 1-16 for real-time applications, resulting in 15-40% GPU utilization but meeting strict latency requirements.
Training requires simultaneous access to parameters, gradients, optimizer states, and activations, creating 3-4x memory overhead compared to inference. Mixed-precision training (FP16/FP32) reduces memory usage by 50% while maintaining convergence, whereas inference can utilize INT8 quantization for 4x memory reduction with minimal accuracy loss.
Training employs gradient compression, mixed-precision training, and progressive pruning during optimization, achieving 1.8x speedup with 0.1% accuracy loss. Inference optimization utilizes post-training quantization (4x speedup), knowledge distillation (5-10x model size reduction), and neural architecture search, delivering 4x inference speedup with 0.5% accuracy degradation.
Training energy costs are amortized across model lifetime and measured in total energy per trained model. GPT-3 training consumed approximately 1,287 MWh over several months. Inference energy costs accumulate per query and directly impact operational efficiency: transformer inference consumes 0.01-0.1 Wh per query, making energy optimization critical for billion-query services.
This comparative framework guides benchmark design by highlighting which metrics matter most for each phase and how evaluation methodologies should differ to capture phase-specific performance characteristics. Training benchmarks emphasize convergence time and scaling efficiency, while inference benchmarks prioritize latency consistency and resource efficiency across diverse deployment scenarios.
Training Benchmarks
Building on our three-dimensional benchmarking framework, training benchmarks focus on evaluating the efficiency, scalability, and resource demands during model training. They allow practitioners to assess how different design choices, including model architectures, data loading mechanisms, hardware configurations, and distributed training strategies, impact performance across the system dimension of our framework. These benchmarks are particularly vital as machine learning systems grow in scale, requiring billions of parameters, terabytes of data, and distributed computing environments.
For instance, large-scale models like OpenAI’s GPT-326 (Brown et al. 2020), which consists of 175 billion parameters trained on 45 terabytes of data, highlight the immense computational demands of modern training. Training benchmarks provide systematic evaluation of the underlying systems to ensure that hardware and software configurations can meet these unprecedented demands efficiently.
26 GPT-3: OpenAI’s 2020 language model with 175 billion parameters, trained on 300 billion tokens using 10,000 NVIDIA V100 GPUs for several months at an estimated cost of $4.6 million (Lambda Labs estimate). GPT-3 demonstrated emergent abilities like few-shot learning and in-context reasoning, establishing the paradigm of scaling laws where larger models consistently outperform smaller ones across diverse language tasks.
Beyond computational demands, efficient data storage and delivery during training also play a major role in the training process. For instance, in a machine learning model that predicts bounding boxes around objects in an image, thousands of images may be required. However, loading an entire image dataset into memory is typically infeasible, so practitioners rely on data loaders from ML frameworks. Successful model training depends on timely and efficient data delivery, making it essential to benchmark tools like data pipelines, preprocessing speed, and storage retrieval times to understand their impact on training performance.
In addition to data pipeline efficiency, hardware selection represents another key factor in training machine learning systems, as it can significantly impact training time. Training benchmarks evaluate CPU, GPU, memory, and network utilization during the training phase to guide system optimizations. Understanding how resources are used is essential: Are GPUs being fully leveraged? Is there unnecessary memory overhead? Benchmarks can uncover bottlenecks or inefficiencies in resource utilization, leading to cost savings and performance improvements.
In many cases, using a single hardware accelerator, such as a single GPU, is insufficient to meet the computational demands of large-scale model training. Machine learning models are often trained in data centers with multiple GPUs or TPUs, where distributed computing enables parallel processing across nodes. Training benchmarks assess how efficiently the system scales across multiple nodes, manages data sharding, and handles challenges like node failures or drop-offs during training.
To illustrate these benchmarking principles, we will reference MLPerf Training throughout this section. MLPerf, introduced earlier in Section 1.2, provides the standardized framework we reference throughout this analysis of training benchmarks.
Training Benchmark Motivation
From a systems perspective, training machine learning models represents a computationally intensive process that requires careful optimization of resources. Training benchmarks serve as essential tools for evaluating system efficiency, identifying bottlenecks, and ensuring that machine learning systems can scale effectively. They provide a standardized approach to measuring how various system components, including hardware accelerators, memory, storage, and network infrastructure, affect training performance.
Consequently, training benchmarks allow researchers and engineers to push the state-of-the-art, optimize configurations, improve scalability, and reduce overall resource consumption by systematically evaluating these factors. As shown in Figure 6, the performance improvements in progressive versions of MLPerf Training benchmarks have consistently outpaced Moore’s Law, which demonstrates that what gets measured gets improved. Using standardized benchmarking trends allows us to rigorously showcase the rapid evolution of ML computing.

Importance of Training Benchmarks
As machine learning models grow in complexity, training becomes increasingly demanding in terms of compute power, memory, and data storage. The ability to measure and compare training efficiency is critical to ensuring that systems can effectively handle large-scale workloads. Training benchmarks provide a structured methodology for assessing performance across different hardware platforms, software frameworks, and optimization techniques.
One of the primary challenges in training machine learning models is the efficient allocation of computational resources. Training a large-scale language model such as GPT-3, which consists of 175 billion parameters and requires processing terabytes of data, places an enormous burden on modern computing infrastructure. Without standardized benchmarks, it becomes difficult to determine whether a system is fully utilizing its resources or whether inefficiencies, including slow data loading, underutilized accelerators, and excessive memory overhead, are limiting performance.
Training benchmarks help uncover such inefficiencies by measuring key performance indicators, including system throughput, time-to-accuracy, and hardware utilization. Recall from Chapter 11: AI Acceleration that GPUs achieve approximately 15,700 GFLOPS for mixed-precision operations while TPUs deliver 275,000 INT8 operations per second for specialized tensor workloads. Training benchmarks allow us to measure whether these theoretical hardware capabilities translate to actual training speedups under realistic conditions. These benchmarks allow practitioners to analyze whether accelerators are being leveraged effectively or whether specific bottlenecks, such as memory bandwidth constraints from hardware limitations (Chapter 11: AI Acceleration), are reducing overall system performance. For example, a system using TF32 precision1 may achieve higher throughput than one using FP32, but if TF32 introduces numerical instability that increases the number of iterations required to reach the target accuracy, the overall training time may be longer. By providing insights into these factors, benchmarks support the design of more efficient training workflows that maximize hardware potential while minimizing unnecessary computation.
Hardware & Software Optimization
The performance of machine learning training is heavily influenced by the choice of hardware and software. Training benchmarks guide system designers in selecting optimal configurations by measuring how different architectures, including GPUs, TPUs, and emerging AI accelerators, handle computational workloads. These benchmarks also evaluate how well deep learning frameworks, such as TensorFlow and PyTorch, optimize performance across different hardware setups.
For example, the MLPerf Training benchmark suite is widely used to compare the performance of different accelerator architectures on tasks such as image classification, natural language processing, and recommendation systems. By running standardized benchmarks across multiple hardware configurations, engineers can determine whether certain accelerators are better suited for specific training workloads. This information is particularly valuable in large-scale data centers and cloud computing environments, where selecting the right combination of hardware and software can lead to significant performance gains and cost savings.
Beyond hardware selection, training benchmarks also inform software optimizations. Machine learning frameworks implement various low-level optimizations, including mixed-precision training27, memory-efficient data loading, and distributed training strategies, that can significantly impact system performance. Benchmarks help quantify the impact of these optimizations, ensuring that training systems are configured for maximum efficiency.
27 Mixed-Precision Training: A training technique that uses both 16-bit (FP16) and 32-bit (FP32) floating-point representations to accelerate training while maintaining model accuracy. Introduced by NVIDIA in 2017, mixed precision can achieve 1.5-2x speedups on modern GPUs with Tensor Cores while reducing memory usage by ~40%, enabling larger batch sizes and faster convergence for large models.
Scalability & Efficiency
As machine learning workloads continue to grow, efficient scaling across distributed computing environments has become a key concern. Many modern deep learning models are trained across multiple GPUs or TPUs, requiring efficient parallelization strategies to ensure that additional computing resources lead to meaningful performance improvements. Training benchmarks measure how well a system scales by evaluating system throughput, memory efficiency, and overall training time as additional computational resources are introduced.
Effective scaling is not always guaranteed. While adding more GPUs or TPUs should, in theory, reduce training time, issues such as communication overhead, data synchronization latency, and memory bottlenecks can limit scaling efficiency. Training benchmarks help identify these challenges by quantifying how performance scales with increasing hardware resources. A well-designed system should exhibit near-linear scaling, where doubling the number of GPUs results in a near-halving of training time. However, real-world inefficiencies often prevent perfect scaling, and benchmarks provide the necessary insights to optimize system design accordingly.
Another crucial factor in training efficiency is time-to-accuracy, which measures how quickly a model reaches a target accuracy level. This metric bridges the algorithmic and system dimensions of our framework, connecting model convergence characteristics with computational efficiency. By leveraging training benchmarks, system designers can assess whether their infrastructure is capable of handling large-scale workloads efficiently while maintaining training stability and accuracy.
Cost & Energy Factors
The computational cost of training large-scale models has risen sharply in recent years, making cost-efficiency a critical consideration. Training a model such as GPT-3 can require millions of dollars in cloud computing resources, making it imperative to evaluate cost-effectiveness across different hardware and software configurations. Training benchmarks provide a means to quantify the cost per training run by analyzing computational expenses, cloud pricing models, and energy consumption.
Beyond financial cost, energy efficiency has become an increasingly important metric. Large-scale training runs consume vast amounts of electricity, contributing to significant carbon emissions. Benchmarks help evaluate energy efficiency by measuring power consumption per unit of training progress, allowing organizations to identify sustainable approaches to AI development.
For example, MLPerf includes an energy benchmarking component that tracks the power consumption of various hardware accelerators during training. This allows researchers to compare different computing platforms not only in terms of raw performance but also in terms of their environmental impact. By integrating energy efficiency metrics into benchmarking studies, organizations can design AI systems that balance computational power with sustainability goals.
Fair ML Systems Comparison
One of the primary functions of training benchmarks is to establish a standardized framework for comparing ML systems. Given the wide variety of hardware architectures, deep learning frameworks, and optimization techniques available today, ensuring fair and reproducible comparisons is essential.
Standardized benchmarks provide a common evaluation methodology, allowing researchers and practitioners to assess how different training systems perform under identical conditions. MLPerf Training benchmarks enable vendor-neutral comparisons by defining strict evaluation criteria for deep learning tasks such as image classification, language modeling, and recommendation systems. This ensures that performance results are meaningful and not skewed by differences in dataset preprocessing, hyperparameter tuning, or implementation details.
This standardized approach addresses reproducibility concerns in machine learning research by providing clearly defined evaluation methodologies. Results can be consistently reproduced across different computing environments, enabling researchers to make informed decisions when selecting hardware, software, and training methodologies while driving systematic progress in AI systems development.
Training Metrics
Evaluating the performance of machine learning training requires a set of well-defined metrics that go beyond conventional algorithmic measures. From a systems perspective, training benchmarks assess how efficiently and effectively a machine learning model can be trained to a predefined accuracy threshold. Metrics such as throughput, scalability, and energy efficiency are only meaningful in relation to whether the model successfully reaches its target accuracy. Without this constraint, optimizing for raw speed or resource utilization may lead to misleading conclusions.
Training benchmarks, such as MLPerf Training, define specific accuracy targets for different machine learning tasks, ensuring that performance measurements are made in a fair and reproducible manner. A system that trains a model quickly but fails to reach the required accuracy is not considered a valid benchmark result. Conversely, a system that achieves the best possible accuracy but takes an excessive amount of time or resources may not be practically useful. Effective benchmarking requires balancing speed, efficiency, and accuracy convergence.
Time and Throughput
One of the primary metrics for evaluating training efficiency is the time required to reach a predefined accuracy threshold. Training time (\(T_{\text{train}}\)) measures how long a model takes to converge to an acceptable performance level, reflecting the overall computational efficiency of the system. It is formally defined as: \[ T_{\text{train}} = \arg\min_{t} \big\{ \text{accuracy}(t) \geq \text{target accuracy} \big\} \]
This metric ensures that benchmarking focuses on how quickly and effectively a system can achieve meaningful results.
Throughput, often expressed as the number of training samples processed per second, provides an additional measure of system performance: \[ \text{Throughput} = \frac{N_{\text{samples}}}{T_{\text{train}}} \] where \(N_{\text{samples}}\) is the total number of training samples processed. However, throughput alone does not guarantee meaningful results, as a model may process a large number of samples quickly without necessarily reaching the desired accuracy.
For example, in MLPerf Training, the benchmark for ResNet-50 may require reaching an accuracy target like 75.9% top-1 on the ImageNet dataset. A system that processes 10,000 images per second but fails to achieve this accuracy is not considered a valid benchmark result, while a system that processes fewer images per second but converges efficiently is preferable. This highlights why throughput must always be evaluated in relation to time-to-accuracy rather than as an independent performance measure.
Scalability & Parallelism
As machine learning models increase in size, training workloads often require distributed computing across multiple processors or accelerators. Scalability measures how effectively training performance improves as more computational resources are added. An ideal system should exhibit near-linear scaling, where doubling the number of GPUs or TPUs leads to a proportional reduction in training time. However, real-world performance is often constrained by factors such as communication overhead, memory bandwidth limitations, and inefficiencies in parallelization strategies.
When training large-scale models such as GPT-3, OpenAI employed approximately 10,000 NVIDIA V100 GPUs in a distributed training setup. Google’s systems have demonstrated similar scaling challenges with their 4,096-node TPU v4 clusters, where adding computational resources provides more raw power but performance improvements are constrained by network communication overhead between nodes. Benchmarks such as MLPerf quantify how well a system scales across multiple GPUs, providing insights into where inefficiencies arise in distributed training.
Parallelism in training is categorized into data parallelism28, model parallelism29, and pipeline parallelism, each presenting distinct challenges. Data parallelism, the most commonly used strategy, involves splitting the training dataset across multiple compute nodes. The efficiency of this approach depends on synchronization mechanisms and gradient communication overhead. In contrast, model parallelism partitions the neural network itself, requiring efficient coordination between processors. Benchmarks evaluate how well a system manages these parallelism strategies without degrading accuracy convergence.
28 Data Parallelism: The most common distributed training strategy where each GPU processes a different subset of the training batch, then synchronizes gradients across all nodes. Modern implementations use techniques like gradient accumulation and all-reduce operations to achieve near-linear scaling up to hundreds of GPUs, though communication overhead typically limits efficiency beyond 1000+ GPUs.
29 Model Parallelism: A distributed training approach where different parts of the neural network are placed on different GPUs, essential for models too large to fit in a single GPU’s memory. GPT-3’s 175B parameters required model parallelism across multiple nodes, as even high-memory GPUs can only hold ~40B parameters in mixed precision.
Resource Utilization
The efficiency of machine learning training depends not only on speed and scalability but also on how well available hardware resources are utilized. Compute utilization measures the extent to which processing units, such as GPUs or TPUs, are actively engaged during training. Low utilization may indicate bottlenecks in data movement, memory access, or inefficient workload scheduling.
For instance, when training BERT on a TPU cluster, researchers observed that input pipeline inefficiencies were limiting overall throughput. Although the TPUs had high raw compute power, the system was not keeping them fully utilized due to slow data retrieval from storage. By profiling the resource utilization, engineers identified the bottleneck and optimized the input pipeline using TFRecord and data prefetching, leading to improved performance.
Memory bandwidth is another critical factor, as deep learning models require frequent access to large volumes of data during training. If memory bandwidth becomes a limiting factor, increasing compute power alone will not improve training speed. Benchmarks assess how well models leverage available memory, ensuring that data transfer rates between storage, main memory, and processing units do not become performance bottlenecks.
I/O performance also plays a significant role in training efficiency, particularly when working with large datasets that cannot fit entirely in memory. Benchmarks evaluate the efficiency of data loading pipelines, including preprocessing operations, caching mechanisms, and storage retrieval speeds. Systems that fail to optimize data loading can experience significant slowdowns, regardless of computational power.
Energy Efficiency & Cost
Training large-scale machine learning models requires substantial computational resources, leading to significant energy consumption and financial costs. Energy efficiency metrics quantify the power usage of training workloads, helping identify systems that optimize computational efficiency while minimizing energy waste. The increasing focus on sustainability has led to the inclusion of energy-based benchmarks, such as those in MLPerf Training, which measure power consumption per training run.
Training GPT-3 was estimated to consume 1,287 MWh of electricity (Patterson et al. 2021), which is comparable to the yearly energy usage of 100 US households. If a system can achieve the same accuracy with fewer training iterations, it directly reduces energy consumption. Energy-aware benchmarks help guide the development of hardware and training strategies that optimize power efficiency while maintaining accuracy targets.
Patterson, David, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. 2021. “Carbon Emissions and Large Neural Network Training.” arXiv Preprint arXiv:2104.10350, April. http://arxiv.org/abs/2104.10350v3.
Cost considerations extend beyond electricity usage to include hardware expenses, cloud computing costs, and infrastructure maintenance. Training benchmarks provide insights into the cost-effectiveness of different hardware and software configurations by measuring training time in relation to resource expenditure. Organizations can use these benchmarks to balance performance and budget constraints when selecting training infrastructure.
Fault Tolerance & Robustness
Training workloads often run for extended periods, sometimes spanning days or weeks, making fault tolerance an essential consideration. A robust system must be capable of handling unexpected failures, including hardware malfunctions, network disruptions, and memory errors, without compromising accuracy convergence.
In large-scale cloud-based training, node failures are common due to hardware instability. If a GPU node in a distributed cluster fails, training must continue without corrupting the model. MLPerf Training includes evaluations of fault-tolerant training strategies, such as checkpointing, where models periodically save their progress. This ensures that failures do not require restarting the entire training process.
Reproducibility & Standardization
For benchmarks to be meaningful, results must be reproducible across different runs, hardware platforms, and software frameworks. Variability in training results can arise due to stochastic processes, hardware differences, and software optimizations. Ensuring reproducibility requires standardizing evaluation protocols, controlling for randomness in model initialization, and enforcing consistency in dataset processing.
MLPerf Training enforces strict reproducibility requirements, ensuring that accuracy results remain stable across multiple training runs. When NVIDIA submitted benchmark results for MLPerf, they had to demonstrate that their ResNet-50 ImageNet training time remained consistent across different GPUs. This ensures that benchmarks measure true system performance rather than noise from randomness.
Training Performance Evaluation
Evaluating the performance of machine learning training systems involves more than just measuring how fast a model can be trained. A comprehensive benchmarking approach considers multiple dimensions, each capturing a different aspect of system behavior. The specific metrics used depend on the goals of the evaluation, whether those are optimizing speed, improving resource efficiency, reducing energy consumption, or ensuring robustness and reproducibility.
Table 2 provides an overview of the core categories and associated metrics commonly used to benchmark system-level training performance. These categories serve as a framework for understanding how training systems behave under different workloads and configurations.
| Category | Key Metrics | Example Benchmark Use |
|---|---|---|
| Training Time and Throughput | Time-to-accuracy (seconds, minutes, hours); Throughput (samples/sec) | Comparing training speed across different GPU architectures |
| Scalability and Parallelism | Scaling efficiency (% of ideal speedup); Communication overhead (latency, bandwidth) | Analyzing distributed training performance for large models |
| Resource Utilization | Compute utilization (% GPU/TPU usage); Memory bandwidth (GB/s); I/O efficiency (data loading speed) | Optimizing data pipelines to improve GPU utilization |
| Energy Efficiency and Cost | Energy consumption per run (MWh, kWh); Performance per watt (TOPS/W) | Evaluating energy-efficient training strategies |
| Fault Tolerance and Robustness | Checkpoint overhead (time per save); Recovery success rate (%) | Assessing failure recovery in cloud-based training systems |
| Reproducibility and Standardization | Variance across runs (% difference in accuracy, training time); Framework consistency (TensorFlow vs. PyTorch vs. JAX) | Ensuring consistency in benchmark results across hardware |
Training time and throughput are often the first metrics considered when evaluating system performance. Time-to-accuracy, the duration required for a model to achieve a specified accuracy level, is a practical and widely used benchmark. Throughput, typically measured in samples per second, provides insight into how efficiently data is processed during training. For example, when comparing a ResNet-50 model trained on NVIDIA A100 versus V100 GPUs, the A100 generally offers higher throughput and faster convergence. However, it is important to ensure that increased throughput does not come at the expense of convergence quality, especially when reduced numerical precision (e.g., TF32) is used to speed up computation.
As model sizes continue to grow, scalability becomes a critical performance dimension. Efficient use of multiple GPUs or TPUs is essential for training large models such as GPT-3 or T5. In this context, scaling efficiency and communication overhead are key metrics. A system might scale linearly up to 64 GPUs, but beyond that, performance gains may taper off due to increased synchronization and communication costs. Benchmarking tools that monitor interconnect bandwidth and gradient aggregation latency can reveal how well a system handles distributed training.
Resource utilization complements these measures by examining how effectively a system leverages its compute and memory resources. Metrics such as GPU utilization, memory bandwidth, and data loading efficiency help identify performance bottlenecks. For instance, a BERT pretraining task that exhibits only moderate GPU utilization may be constrained by an underperforming data pipeline. Optimizations like sharding input files or prefetching data into device memory can often resolve these inefficiencies.
In addition to raw performance, energy efficiency and cost have become increasingly important considerations. Training large models at scale can consume significant power, raising environmental and financial concerns. Metrics such as energy consumed per training run and performance per watt (e.g., TOPS/W) help evaluate the sustainability of different hardware and system configurations. For example, while two systems may reach the same accuracy in the same amount of time, the one that uses significantly less energy may be preferred for long-term deployment.
Fault tolerance and robustness address how well a system performs under non-ideal conditions, which are common in real-world deployments. Training jobs frequently encounter hardware failures, preemptions, or network instability. Metrics like checkpoint overhead and recovery success rate provide insight into the resilience of a training system. In practice, checkpointing can introduce non-trivial overhead. For example, pausing training every 30 minutes to write a full checkpoint may reduce overall throughput by 5-10%. Systems must strike a balance between failure recovery and performance impact.
Finally, reproducibility and standardization ensure that benchmark results are consistent, interpretable, and transferable. Even minor differences in software libraries, initialization seeds, or floating-point behavior can affect training outcomes. Comparing the same model across frameworks, such as comparing PyTorch with Automatic Mixed Precision to TensorFlow with XLA, can reveal variation in convergence rates or final accuracy. Reliable benchmarking requires careful control of these variables, along with repeated runs to assess statistical variance.
Together, these dimensions provide a holistic view of training performance. They help researchers, engineers, and system designers move beyond simplistic comparisons and toward a more nuanced understanding of how machine learning systems behave under realistic conditions. As established in our statistical rigor framework earlier, measuring these dimensions accurately requires systematic methodology that distinguishes between true performance differences and statistical noise, accounting for factors like GPU boost clock30 behavior and thermal throttling31 that can significantly impact measurements.
30 GPU Boost Clock: NVIDIA’s dynamic frequency scaling technology that automatically increases GPU core and memory clocks above base frequencies when thermal and power conditions allow. Boost clocks can increase performance by 10-30% in cool conditions but decrease under sustained workloads, causing benchmark variability. For example, RTX 4090 base clock is 2230 MHz but can boost to 2520 MHz when cool.
31 Thermal Throttling: A protection mechanism that reduces processor frequency when temperatures exceed safe operating limits (typically 83-90°C for GPUs, 100-105°C for CPUs). Thermal throttling can reduce performance by 20-50% during sustained AI workloads, making thermal management crucial for consistent benchmark results. Modern systems implement sophisticated thermal monitoring with temperature sensors every few millimeters across the chip.
Training Benchmark Pitfalls
Despite the availability of well-defined benchmarking methodologies, certain misconceptions and flawed evaluation practices often lead to misleading conclusions. Understanding these pitfalls is important for interpreting benchmark results correctly.
Overemphasis on Raw Throughput
A common mistake in training benchmarks is assuming that higher throughput always translates to better training performance. It is possible to artificially increase throughput by using lower numerical precision, reducing synchronization, or even bypassing certain computations. However, these optimizations do not necessarily lead to faster convergence.
For example, a system using TF32 precision may achieve higher throughput than one using FP32, but if TF32 introduces numerical instability that increases the number of iterations required to reach the target accuracy, the overall training time may be longer. The correct way to evaluate throughput is in relation to time-to-accuracy, ensuring that speed optimizations do not come at the expense of convergence efficiency.
Isolated Single-Node Performance
Benchmarking training performance on a single node without considering distributed scaling can lead to misleading conclusions. A GPU may demonstrate excellent throughput when used independently, but when deployed in large clusters like Google’s 4,096-node TPU v4 configurations, communication overhead and synchronization constraints significantly diminish these efficiency gains.
For instance, a system optimized for single-node performance may employ memory optimizations that do not generalize to multi-node environments. Large-scale models such as GPT-3 require efficient gradient synchronization across thousands of nodes, making comprehensive scalability assessment essential. Google’s experience with 4,096-node TPU clusters demonstrates that gradient synchronization challenges become dominant performance factors at this scale.
Ignoring Failures & Interference
Many benchmarks assume an idealized training environment where hardware failures, memory corruption, network instability, or interference from other processes do not occur. However, real-world training jobs often experience unexpected failures and workload interference that require checkpointing, recovery mechanisms, and resource management.
A system optimized for ideal-case performance but lacking fault tolerance and interference handling may achieve impressive benchmark results under controlled conditions, but frequent failures, inefficient recovery, and resource contention could make it impractical for large-scale deployment. Effective benchmarking should consider checkpointing overhead, failure recovery efficiency, and the impact of interference from other processes rather than assuming perfect execution conditions.
Linear Scaling Assumption
When evaluating distributed training, it is often assumed that increasing the number of GPUs or TPUs will result in proportional speedups. In practice, communication bottlenecks, memory contention, and synchronization overheads lead to diminishing returns as more compute nodes are added.
For example, training a model across 1,000 GPUs does not necessarily provide 100 times the speed of training on 10 GPUs. At a certain scale, gradient communication costs become a limiting factor, offsetting the benefits of additional parallelism. Proper benchmarking should assess scalability efficiency rather than assuming idealized linear improvements.
Ignoring Reproducibility
Benchmark results are often reported without verifying their reproducibility across different hardware and software frameworks. Even minor variations in floating-point arithmetic, memory layouts, or optimization strategies can introduce statistical differences in training time and accuracy.
For example, a benchmark run on TensorFlow with XLA optimizations may exhibit different convergence characteristics compared to the same model trained using PyTorch with Automatic Mixed Precision (AMP). Proper benchmarking requires evaluating results across multiple frameworks to ensure that software-specific optimizations do not distort performance comparisons.
Training Benchmark Synthesis
Training benchmarks provide valuable insights into machine learning system performance, but their interpretation requires careful consideration of real-world constraints. High throughput does not necessarily mean faster training if it compromises accuracy convergence. Similarly, scaling efficiency must be evaluated holistically, taking into account both computational efficiency and communication overhead.
Avoiding common benchmarking pitfalls and employing structured evaluation methodologies allows machine learning practitioners to gain a deeper understanding of how to optimize training workflows, design efficient AI systems, and develop scalable machine learning infrastructure. As models continue to increase in complexity, benchmarking methodologies must evolve to reflect real-world challenges, ensuring that benchmarks remain meaningful and actionable in guiding AI system development.
Inference Benchmarks
Complementing training benchmarks within our framework, inference benchmarks focus on evaluating the efficiency, latency, and resource demands during model deployment and serving. Unlike training, where the focus is on optimizing large-scale computations over extensive datasets, inference involves deploying trained models to make real-time or batch predictions efficiently. These benchmarks help assess how various factors, including model architectures, hardware configurations, precision optimization techniques, and runtime optimizations, impact inference performance.
As deep learning models grow exponentially in complexity and size, efficient inference becomes an increasingly critical challenge, particularly for applications requiring real-time decision-making, such as autonomous driving, healthcare diagnostics, and conversational AI. For example, serving large-scale language models involves handling billions of parameters while maintaining acceptably low latency. Inference benchmarks provide systematic evaluation of the underlying hardware and software stacks to ensure that models can be deployed efficiently across different environments, from cloud data centers to edge devices.
Unlike training, which is typically conducted in large-scale data centers with ample computational resources, inference must be optimized for dramatically diverse deployment scenarios, including mobile devices, IoT systems, and embedded processors. Efficient inference depends on multiple interconnected factors, such as optimized data pipelines, model optimization techniques, and hardware acceleration. Benchmarks help evaluate how well these optimizations improve real-world deployment performance.
Building on these optimization requirements, hardware selection plays an increasingly important role in inference efficiency. While GPUs and TPUs are widely used for training, inference workloads often require specialized accelerators like NPUs (Neural Processing Units)32, FPGAs33, and dedicated inference chips such as Google’s Edge TPU34. Inference benchmarks evaluate the utilization and performance of these hardware components, helping practitioners choose the right configurations for their deployment needs.
32 Neural Processing Unit (NPU): Specialized processors designed specifically for AI workloads, featuring optimized architectures for neural network operations. Modern smartphones include NPUs capable of 1-15 TOPS (Tera Operations Per Second), enabling on-device AI while consuming 100-1000x less power than GPUs for the same ML tasks.
33 Field-Programmable Gate Array (FPGA): Reconfigurable silicon chips that can be programmed after manufacturing to implement custom digital circuits. Unlike fixed ASICs, FPGAs offer flexibility to optimize for different algorithms, achieving 10-100x better energy efficiency than CPUs for specific ML workloads while maintaining adaptability to algorithm changes.
34 Edge TPU: Google’s ultra-low-power AI accelerator designed for edge devices, consuming only 2 watts while delivering 4 TOPS of performance. Each Edge TPU is optimized for TensorFlow Lite models and costs around $25, making distributed AI deployment economically viable at massive scale.
Scaling inference workloads across cloud servers, edge platforms, mobile devices, and tinyML systems introduces additional complexity. As illustrated in Figure 7, there is a significant differential in power consumption among these systems, ranging from microwatts to megawatts. Inference benchmarks evaluate the trade-offs between latency, cost, and energy efficiency, thereby assisting organizations in making informed deployment decisions.
As with training, we will reference MLPerf Inference throughout this section to illustrate benchmarking principles. MLPerf’s inference benchmarks, building on the foundation established in Section 1.2, provide standardized evaluation across deployment scenarios from cloud to edge devices.
Inference Benchmark Motivation
Deploying machine learning models for inference introduces a unique set of challenges distinct from training. While training optimizes large-scale computation over extensive datasets, inference must deliver predictions efficiently and at scale in real-world environments. Inference benchmarks evaluate deployment-specific performance challenges, identifying bottlenecks that emerge when models transition from development to production serving.
Unlike training, which typically runs on dedicated high-performance hardware, inference must adapt to varying constraints. A model deployed in a cloud server might prioritize high-throughput batch processing, while the same model running on a mobile device must operate under strict latency and power constraints. On edge devices with limited compute and memory, model optimization techniques become critical. Benchmarks help assess these trade-offs, ensuring that inference systems maintain the right balance between accuracy, speed, and efficiency across different platforms.
Inference benchmarks help answer essential questions about model deployment. How quickly can a model generate predictions in real-world conditions? What are the trade-offs between inference speed and accuracy? Can an inference system handle increasing demand while maintaining low latency? By evaluating these factors, benchmarks guide optimizations in both hardware and software to improve overall efficiency (Reddi et al. 2019).
Importance of Inference Benchmarks
Inference plays a critical role in AI applications, where performance directly affects usability and cost. Unlike training, which is often performed offline, inference typically operates in real-time or near real-time, making latency a primary concern. A self-driving car processing camera feeds must react within milliseconds, while a voice assistant generating responses should feel instantaneous to users.
Different applications impose varying constraints on inference. Some workloads require single-instance inference, where predictions must be made as quickly as possible for each individual input. This is crucial in real-time systems such as robotics, augmented reality, and conversational AI, where even small delays can impact responsiveness. Other workloads, such as large-scale recommendation systems or search engines, process massive batches of queries simultaneously, prioritizing throughput over per-query latency. Benchmarks allow engineers to evaluate both scenarios and ensure models are optimized for their intended use case.
A key difference between training and inference is that inference workloads often run continuously in production, meaning that small inefficiencies can compound over time. Unlike a training job that runs once and completes, an inference system deployed in the cloud may serve millions of queries daily, and a model running on a smartphone must manage battery consumption over extended use. Benchmarks provide a structured way to measure inference efficiency under these real-world constraints, helping developers make informed choices about model optimization, hardware selection, and deployment strategies.
Hardware & Software Optimization
Efficient inference depends on both hardware acceleration and software optimizations. While GPUs and TPUs dominate training, inference is more diverse in its hardware needs. A cloud-based AI service might leverage powerful accelerators for large-scale workloads, whereas mobile devices rely on specialized inference chips like NPUs or optimized CPU execution. On embedded systems, where resources are constrained, achieving high performance requires careful memory and compute efficiency. Benchmarks help evaluate how well different hardware platforms handle inference workloads, guiding deployment decisions.
Software optimizations are just as important. Frameworks like TensorRT35, ONNX Runtime36, and TVM37 apply optimizations such as operator fusion38, numerical precision adjustments, and kernel tuning to improve inference speed and reduce computational overhead. These optimizations can make a significant difference, especially in environments with limited resources. Benchmarks allow developers to measure the impact of such techniques on latency, throughput, and power efficiency, ensuring that optimizations translate into real-world improvements without degrading model accuracy.
35 TensorRT: NVIDIA’s high-performance inference optimizer and runtime library that accelerates deep learning models on NVIDIA GPUs. Introduced in 2016, TensorRT applies graph optimizations, kernel fusion, and precision calibration to achieve 1.5-7x speedups over naive implementations, supporting FP16, INT8, and sparse matrix operations.
36 ONNX Runtime: Microsoft’s cross-platform, high-performance ML inferencing and training accelerator supporting the Open Neural Network Exchange (ONNX) format. Released in 2018, it enables models trained in any framework to run efficiently across different hardware (CPU, GPU, NPU) with optimizations like graph fusion and memory pattern optimization.
37 TVM: An open-source deep learning compiler stack that optimizes tensor programs for diverse hardware backends including CPUs, GPUs, and specialized accelerators. Developed at the University of Washington, TVM uses machine learning to automatically generate optimized code, achieving performance competitive with hand-tuned libraries while supporting new hardware architectures.
38 Operator Fusion: A compiler optimization technique that combines multiple neural network operations into single kernels to reduce memory bandwidth requirements and improve cache efficiency. For example, fusing convolution with batch normalization and ReLU can eliminate intermediate memory writes, achieving 20-40% speedups in inference workloads.
Scalability & Efficiency
Inference workloads vary significantly in their scaling requirements. A cloud-based AI system handling millions of queries per second must ensure that increasing demand does not cause delays, while a mobile application running a model locally must execute quickly even under power constraints. Unlike training, which is typically performed on a fixed set of high-performance machines, inference must scale dynamically based on usage patterns and available computational resources.
Benchmarks evaluate how inference systems scale under different conditions. They measure how well performance holds up under increasing query loads, whether additional compute resources improve inference speed, and how efficiently models run across different deployment environments. Large-scale inference deployments often involve distributed inference servers, where multiple copies of a model process incoming requests in parallel. Benchmarks assess how efficiently this scaling occurs and whether additional resources lead to meaningful improvements in latency and throughput.
Another key factor in inference efficiency is cold-start performance, the time it takes for a model to load and begin processing queries. This is especially relevant for applications that do not run inference continuously but instead load models on demand. Benchmarks help determine whether a system can quickly transition from idle to active execution without significant overhead.
Cost & Energy Factors
Because inference workloads run continuously, operational cost and energy efficiency are critical factors. Unlike training, where compute costs are incurred once, inference costs accumulate over time as models are deployed in production. Running an inefficient model at scale can significantly increase cloud compute expenses, while an inefficient mobile inference system can drain battery life quickly. Benchmarks provide insights into cost per inference request, helping organizations optimize for both performance and affordability.
Energy efficiency is also a growing concern, particularly for mobile and edge AI applications. Many inference workloads run on battery-powered devices, where excessive computation can impact usability. A model running on a smartphone, for example, must be optimized to minimize power consumption while maintaining responsiveness. Benchmarks help evaluate inference efficiency per watt, ensuring that models can operate sustainably across different platforms.
Fair ML Systems Comparison
Applying the standardized evaluation principles established for training benchmarks, inference evaluation requires the same rigorous comparison methodologies. MLPerf Inference extends these principles to deployment scenarios, defining evaluation criteria for tasks such as image classification, object detection, and speech recognition across different hardware platforms and optimization techniques. This ensures that inference performance comparisons remain meaningful and reproducible while accounting for deployment-specific constraints like latency requirements and energy efficiency.
Inference Metrics
Evaluating the performance of inference systems requires a distinct set of metrics from those used for training. While training benchmarks emphasize throughput, scalability, and time-to-accuracy, inference benchmarks must focus on latency, efficiency, and resource utilization in practical deployment settings. These metrics ensure that machine learning models perform well across different environments, from cloud data centers handling millions of requests to mobile and edge devices operating under strict power and memory constraints.
Unlike training benchmarks that emphasize throughput and time-to-accuracy as established earlier, inference benchmarks evaluate how efficiently a trained model can process inputs and generate predictions at scale. The following sections describe the most important inference benchmarking metrics, explaining their relevance and how they are used to compare different systems.
Latency & Tail Latency
Latency is one of the most critical performance metrics for inference, particularly in real-time applications where delays can negatively impact user experience or system safety. Latency refers to the time taken for an inference system to process an input and produce a prediction. While the average latency of a system is useful, it does not capture performance in high-demand scenarios where occasional delays can degrade reliability.
To account for this, benchmarks often measure tail latency39, which reflects the worst-case delays in a system. These are typically reported as the 95th percentile (p95) or 99th percentile (p99) latency, meaning that 95% or 99% of inferences are completed within a given time. For applications such as autonomous driving or real-time trading, maintaining low tail latency is essential to avoid unpredictable delays that could lead to catastrophic outcomes.
39 Tail Latency: The worst-case response times (typically 95th or 99th percentile) that determine user experience in production systems. While average latency might be 50ms, 99th percentile could be 500ms due to garbage collection, thermal throttling, or resource contention. Production SLAs are set based on tail latency, not averages.
Tail latency’s connection to user experience at scale becomes critical in production systems serving millions of users. Even small P99 latency degradations create compounding effects across large user bases: if 1% of requests experience 10x latency (e.g., 1000ms instead of 100ms), this affects 10,000 users per million requests, potentially leading to timeout errors, poor user experience, and customer churn. Search engines and recommendation systems demonstrate this sensitivity: Google found that 500ms additional latency reduces search traffic by 20%, while Amazon discovered that 100ms latency increase decreases sales by 1%.
Service level objectives (SLOs) in production systems therefore focus on tail latency rather than mean latency to ensure consistent user experience. Typical production SLOs specify P95 < 100ms and P99 < 500ms for interactive services, recognizing that occasional slow responses have disproportionate impact on user satisfaction. Large-scale systems like Netflix and Uber optimize for P99.9 latency to handle traffic spikes and infrastructure variations that affect service reliability.
Throughput & Batch Efficiency
While latency measures the speed of individual inference requests, throughput measures how many inference requests a system can process per second. It is typically expressed in queries per second (QPS) or frames per second (FPS) for vision tasks. Some inference systems operate on a single-instance basis, where each input is processed independently as soon as it arrives. Other systems process multiple inputs in parallel using batch inference, which can significantly improve efficiency by leveraging hardware optimizations.
For example, cloud-based services handling millions of queries per second benefit from batch inference, where large groups of inputs are processed together to maximize computational efficiency. In contrast, applications like robotics, interactive AI, and augmented reality require low-latency single-instance inference, where the system must respond immediately to each new input.
Benchmarks must consider both single-instance and batch throughput to provide a comprehensive understanding of inference performance across different deployment scenarios.
Precision & Accuracy Trade-offs
Optimizing inference performance often involves reducing numerical precision, which can significantly accelerate computation while reducing memory and energy consumption. However, lower-precision calculations can introduce accuracy degradation, making it essential to benchmark the trade-offs between speed and predictive quality.
Inference benchmarks evaluate how well models perform under different numerical settings, such as FP3240, FP1641, and INT842. Many modern AI accelerators support mixed-precision inference, allowing systems to dynamically adjust numerical representation based on workload requirements. Model compression techniques43 further improve efficiency, but their impact on model accuracy varies depending on the task and dataset. Benchmarks help determine whether these optimizations are viable for deployment, ensuring that improvements in efficiency do not come at the cost of unacceptable accuracy loss.
40 FP32: 32-bit floating-point format providing high numerical precision with approximately 7 decimal digits of accuracy. Standard for research and training, FP32 operations consume maximum memory and computational resources but ensure numerical stability. Modern GPUs achieve 15-20 TFLOPS in FP32, serving as the baseline for precision comparisons.
41 FP16: 16-bit floating-point format that halves memory usage compared to FP32 while maintaining reasonable numerical precision. Widely supported by modern AI accelerators, FP16 can achieve 2-4x speedups over FP32 with minimal accuracy loss for most deep learning models, making it the preferred format for inference and mixed-precision training.
42 INT8: 8-bit integer format providing maximum memory and computational efficiency, requiring only 25% of FP32 storage. Post-training precision reduction to INT8 can achieve 4x memory reduction and 2-4x speedup on specialized hardware, but requires careful calibration to minimize accuracy degradation, typically maintaining 95-99% of original model performance.
43 Model Compression: Techniques to reduce model size and computational requirements including precision reduction (reducing numerical precision), structural optimization (removing unnecessary parameters), knowledge transfer (training smaller models to mimic larger ones), and tensor decomposition. These methods can achieve 10-100x size reduction while maintaining 90-99% of original accuracy.
Memory Footprint & Model Size
Beyond computational optimizations, memory footprint is another critical consideration for inference systems, particularly for devices with limited resources. Efficient inference depends not only on speed but also on memory usage. Unlike training, where large models can be distributed across powerful GPUs or TPUs, inference often requires models to run within strict memory budgets. The total model size determines how much storage is required for deployment, while RAM usage reflects the working memory needed during execution. Some models require large memory bandwidth to efficiently transfer data between processing units, which can become a bottleneck if the hardware lacks sufficient capacity.
Inference benchmarks evaluate these factors to ensure that models can be deployed effectively across a range of devices. A model that achieves high accuracy but exceeds memory constraints may be impractical for real-world use. To address this, various compression techniques are often applied to reduce model size while maintaining accuracy. Benchmarks help assess whether these optimizations strike the right balance between memory efficiency and predictive performance.
Cold-Start & Model Load Time
Once memory requirements are optimized, cold-start performance becomes critical for ensuring inference systems are ready to respond quickly upon deployment. In many deployment scenarios, models are not always kept in memory but instead loaded on demand when needed. This can introduce significant delays, particularly in serverless AI environments44, where resources are allocated dynamically based on incoming requests. Cold-start performance measures how quickly a system can transition from idle to active execution, ensuring that inference is available without excessive wait times.
44 Serverless AI: Cloud computing paradigm where ML models are deployed as functions that automatically scale from zero to handle incoming requests, with users paying only for actual inference time. Popular platforms like AWS Lambda, Google Cloud Functions, and Azure Functions support serverless AI, but cold-start latencies of 1-10 seconds for large models can impact user experience compared to always-on deployments.
Model load time refers to the duration required to load a trained model into memory before it can process inputs. In some cases, particularly on resource-limited devices, models must be reloaded frequently to free up memory for other applications. The time taken for the first inference request is also an important consideration, as it reflects the total delay users experience when interacting with an AI-powered service. Benchmarks help quantify these delays, ensuring that inference systems can meet real-world responsiveness requirements.
Dynamic Workload Scaling
While cold-start latency addresses initial responsiveness, scalability ensures that inference systems can handle fluctuating workloads and concurrent demands over time Inference workloads must scale effectively across different usage patterns. In cloud-based AI services, this means efficiently handling millions of concurrent users, while on mobile or embedded devices, it involves managing multiple AI models running simultaneously without overloading the system.
Scalability measures how well inference performance improves when additional computational resources are allocated. In some cases, adding more GPUs or TPUs increases throughput significantly, but in other scenarios, bottlenecks such as memory bandwidth limitations or network latency may limit scaling efficiency. Benchmarks also assess how well a system balances multiple concurrent models in real-world deployment, where different AI-powered features may need to run at the same time without interference.
For cloud-based AI, benchmarks evaluate how efficiently a system handles fluctuating demand, ensuring that inference servers can dynamically allocate resources without compromising latency. In mobile and embedded AI, efficient multi-model execution is essential for running multiple AI-powered features simultaneously without degrading system performance.
Energy Consumption & Efficiency
Since inference workloads run continuously in production, power consumption and energy efficiency are critical considerations. This is particularly important for mobile and edge devices, where battery life and thermal constraints limit available computational resources. Even in large-scale cloud environments, power efficiency directly impacts operational costs and sustainability goals.
The energy required for a single inference is often measured in joules per inference, reflecting how efficiently a system processes inputs while minimizing power draw. In cloud-based inference, efficiency is commonly expressed as queries per second per watt (QPS/W) to quantify how well a system balances performance and energy consumption. For mobile AI applications, optimizing inference power consumption extends battery life and allows models to run efficiently on resource-constrained devices. Reducing energy use also plays a key role in making large-scale AI systems more environmentally sustainable, ensuring that computational advancements align with energy-conscious deployment strategies. By balancing power consumption with performance, energy-efficient inference systems enable AI to scale sustainably across diverse applications, from data centers to edge devices.
Inference Performance Evaluation
Evaluating inference performance is a critical step in understanding how well machine learning systems meet the demands of real-world applications. Unlike training, which is typically conducted offline, inference systems must process inputs and generate predictions efficiently across a wide range of deployment scenarios. Metrics such as latency, throughput, memory usage, and energy efficiency provide a structured way to measure system performance and identify areas for improvement.
Table 3 below summarizes the key metrics used to evaluate inference systems, highlighting their relevance to different contexts. While each metric offers unique insights, it is important to approach inference benchmarking holistically. Trade-offs between metrics, including speed versus accuracy and throughput versus power consumption, are common, and understanding these trade-offs is essential for effective system design.
| Category | Key Metrics | Example Benchmark Use |
|---|---|---|
| Latency and Tail Latency | Mean latency (ms/request); Tail latency (p95, p99, p99.9) | Evaluating real-time performance for safety-critical AI |
| Throughput and Efficiency | Queries per second (QPS); Frames per second (FPS); Batch throughput | Comparing large-scale cloud inference systems |
| Numerical Precision Impact | Accuracy degradation (FP32 vs. INT8); Speedup from reduced precision | Balancing accuracy vs. efficiency in optimized inference |
| Memory Footprint | Model size (MB/GB); RAM usage (MB); Memory bandwidth utilization | Assessing feasibility for edge and mobile deployments |
| Cold-Start and Load Time | Model load time (s); First inference latency (s) | Evaluating responsiveness in serverless AI |
| Scalability | Efficiency under load; Multi-model serving performance | Measuring robustness for dynamic, high-demand systems |
| Power and Energy Efficiency | Power consumption (Watts); Performance per Watt (QPS/W) | Optimizing energy use for mobile and sustainable AI |
Inference Systems Considerations
Inference systems face unique challenges depending on where and how they are deployed. Real-time applications, such as self-driving cars or voice assistants, require low latency to ensure timely responses, while large-scale cloud deployments focus on maximizing throughput to handle millions of queries. Edge devices, on the other hand, are constrained by memory and power, making efficiency critical.
One of the most important aspects of evaluating inference performance is understanding the trade-offs between metrics. For example, optimizing for high throughput might increase latency, making a system unsuitable for real-time applications. Similarly, reducing numerical precision improves power efficiency and speed but may lead to minor accuracy degradation. A thoughtful evaluation must balance these trade-offs to align with the intended application.
The deployment environment also plays a significant role in determining evaluation priorities. Cloud-based systems often prioritize scalability and adaptability to dynamic workloads, while mobile and edge systems require careful attention to memory usage and energy efficiency. These differing priorities mean that benchmarks must be tailored to the context of the system’s use, rather than relying on one-size-fits-all evaluations.
Ultimately, evaluating inference performance requires a holistic approach. Focusing on a single metric, such as latency or energy efficiency, provides an incomplete picture. Instead, all relevant dimensions must be considered together to ensure that the system meets its functional, resource, and performance goals in a balanced way.
Context-Dependent Metrics
Different deployment scenarios require distinctly different metric priorities, as the operational constraints and success criteria vary dramatically across contexts. Understanding these priorities allows engineers to focus benchmarking efforts effectively and interpret results within appropriate decision frameworks. Table 4 illustrates how performance priorities shift across five major deployment contexts, revealing the systematic relationship between operational constraints and optimization targets.
| Deployment Context | Primary Priority | Secondary Priority | Tertiary Priority | Key Design Constraint |
|---|---|---|---|---|
| Real-Time Applications | Latency (p95 < 50ms) | Reliability (99.9%) | Memory Footprint | User experience demands immediate response |
| Cloud-Scale Services | Throughput (QPS) | Cost Efficiency | Average Latency | Business viability requires massive scale |
| Edge/Mobile Devices | Power Consumption | Memory Footprint | Latency | Battery life and resource limits dominate |
| Training Workloads | Training Time | GPU Utilization | Memory Efficiency | Research velocity enables faster experimentation |
| Scientific/Medical | Accuracy | Reliability | Explainability | Correctness cannot be compromised for performance |
The hierarchy shown in Table 4 reflects how operational constraints drive performance optimization strategies. Real-time applications exemplify latency-critical deployments where user experience depends on immediate system response. Autonomous vehicle perception systems must process sensor data within strict timing deadlines, making p95 latency more important than peak throughput. The table shows reliability as the secondary priority because system failures in autonomous vehicles carry safety implications that transcend performance concerns.
Conversely, cloud-scale services prioritize aggregate throughput to handle millions of concurrent users, accepting higher average latency in exchange for improved cost efficiency per query. The progression from throughput to cost efficiency to latency reflects economic realities: cloud providers must optimize for revenue per server while maintaining acceptable user experience. Notice how the same metric (latency) ranks as primary for real-time applications but tertiary for cloud services, demonstrating the context-dependent nature of performance evaluation.
Edge and mobile deployments face distinctly different constraints, where battery life and thermal limitations dominate design decisions. A smartphone AI assistant that improves throughput by 50% but increases power consumption by 30% represents a net regression, as reduced battery life directly impacts user satisfaction. Training workloads present another distinct optimization landscape, where research productivity depends on experiment turnaround time, making GPU utilization efficiency and memory bandwidth critical for enabling larger model exploration.
Scientific and medical applications establish accuracy and reliability as non-negotiable requirements, with performance optimization serving these primary objectives rather than substituting for them. A medical diagnostic system achieving 99.2% accuracy at 10ms latency provides superior value compared to 98.8% accuracy at 5ms latency, demonstrating how context-specific priorities guide meaningful performance evaluation.
This prioritization framework fundamentally shapes benchmark interpretation and optimization strategies. Achieving 2x throughput improvement represents significant value for cloud deployments but provides minimal benefit for battery-powered edge devices where 20% power reduction delivers superior operational impact.
Inference Benchmark Pitfalls
Even with well-defined metrics, benchmarking inference systems can be challenging. Missteps during the evaluation process often lead to misleading conclusions. Below are common pitfalls that students and practitioners should be aware of when analyzing inference performance.
Overemphasis on Average Latency
While average latency provides a baseline measure of response time, it fails to capture how a system performs under peak load. In real-world scenarios, worst-case latency, which is captured through metrics such as p9545 or p9946 tail latency, can significantly impact system reliability. For instance, a conversational AI system may fail to provide timely responses if occasional latency spikes exceed acceptable thresholds.
45 P95 Latency: The 95th percentile latency measurement, meaning 95% of requests complete within this time while 5% take longer. For example, if p95 latency is 100ms, then 19 out of 20 requests finish within 100ms. P95 is widely used in SLA agreements because it captures typical user experience while acknowledging that some requests will naturally take longer due to system variability.
46 P99 Latency: The 99th percentile latency measurement, indicating that 99% of requests complete within this time while only 1% experience longer delays. P99 latency is crucial for user-facing applications where even rare slow responses significantly impact user satisfaction. For instance, if a web service handles 1 million requests daily, p99 latency determines the experience for 10,000 users.
Ignoring Memory & Energy Constraints
A model with excellent throughput or latency may be unsuitable for mobile or edge deployments if it requires excessive memory or power. For example, an inference system designed for cloud environments might fail to operate efficiently on a battery-powered device. Proper benchmarks must consider memory footprint and energy consumption to ensure practicality across deployment contexts.
Ignoring Cold-Start Performance
In serverless environments, where models are loaded on demand, cold-start latency47 is a critical factor. Ignoring the time it takes to initialize a model and process the first request can result in unrealistic expectations for responsiveness. Evaluating both model load time and first-inference latency ensures that systems are designed to meet real-world responsiveness requirements.
47 Cold-Start Latency: The initialization time required when a system or service starts from a completely idle state, including time to load libraries, initialize models, and allocate memory. In serverless AI deployments, cold-start latencies range from 100ms for simple models to 10+ seconds for large language models, significantly impacting user experience compared to warm instances that respond in milliseconds.
Isolated Metrics Evaluation
Benchmarking inference systems often involves balancing competing metrics. For example, maximizing batch throughput might degrade latency, while aggressive precision reduction could reduce accuracy. Focusing on a single metric without considering its impact on others can lead to incomplete or misleading evaluations.
Numerical precision optimization exemplifies this challenge particularly well. Individual accelerator benchmarks show INT8 operations achieving 4x higher TOPS48 (Tera Operations Per Second) compared to FP32, creating compelling performance narratives.
48 TOPS (Tera Operations Per Second): A measure of computational throughput indicating trillions of operations per second, commonly used for AI accelerator performance. Modern AI chips achieve 100-1000 TOPS for INT8 operations: NVIDIA H100 delivers 2000 TOPS INT8, Apple M2 Neural Engine provides 15.8 TOPS, while edge devices like Google Edge TPU achieve 4 TOPS. Higher TOPS enable faster AI inference and training. However, when these accelerators deploy in complete training systems, the chip-level advantage often disappears due to increased convergence time, precision conversion overhead, and mixed-precision coordination complexity. The “4x faster” micro-benchmark translates into slower end-to-end training, demonstrating why isolated hardware metrics cannot substitute for holistic system evaluation. Balanced approaches like FP16 mixed-precision often provide superior system-level performance despite lower peak TOPS measurements. Comprehensive benchmarks must account for these cross-metric interactions and system-level complexities.
Linear Scaling Assumption
Inference performance does not always scale proportionally with additional resources. Bottlenecks such as memory bandwidth, thermal limits, or communication overhead can limit the benefits of adding more GPUs or TPUs. As discussed in Chapter 11: AI Acceleration, these scaling limitations arise from fundamental hardware constraints and interconnect architectures. Benchmarks that assume linear scaling behavior may overestimate system performance, particularly in distributed deployments.
Ignoring Application Requirements
Generic benchmarking results may fail to account for the specific needs of an application. For instance, a benchmark optimized for cloud inference might be irrelevant for edge devices, where energy and memory constraints dominate. Tailoring benchmarks to the deployment context ensures that results are meaningful and actionable.
Statistical Significance & Noise
Distinguishing meaningful performance improvements from measurement noise requires proper statistical analysis. Following the evaluation methodology principles established earlier, MLPerf addresses measurement variability by requiring multiple benchmark runs and reporting percentile-based metrics rather than single measurements (Reddi et al. 2019). For instance, MLPerf Inference reports 99th percentile latency alongside mean performance, capturing both typical behavior and worst-case scenarios that single-run measurements might miss. This approach recognizes that system performance naturally varies due to factors like thermal throttling, memory allocation patterns, and background processes.
Reddi, Vijay Janapa, Christine Cheng, David Kanter, Peter Mattson, Guenther Schmuelling, Carole-Jean Wu, Brian Anderson, et al. 2019. “MLPerf Inference Benchmark.” arXiv Preprint arXiv:1911.02549, November, 446–59. https://doi.org/10.1109/isca45697.2020.00045.
Inference Benchmark Synthesis
Inference benchmarks are essential tools for understanding system performance, but their utility depends on careful and holistic evaluation. Metrics like latency, throughput, memory usage, and energy efficiency provide valuable insights, but their importance varies depending on the application and deployment context. Students should approach benchmarking as a process of balancing multiple priorities, rather than optimizing for a single metric.
Avoiding common pitfalls and considering the trade-offs between different metrics allows practitioners to design inference systems that are reliable, efficient, and suitable for real-world deployment. The ultimate goal of benchmarking is to guide system improvements that align with the demands of the intended application.
MLPerf Inference Benchmarks
The MLPerf Inference benchmark, developed by MLCommons49, provides a standardized framework for evaluating machine learning inference performance across a range of deployment environments. Initially, MLPerf started with a single inference benchmark, but as machine learning systems expanded into diverse applications, it became clear that a one-size-fits-all benchmark was insufficient. Different inference scenarios, including cloud-based AI services and resource-constrained embedded devices, demanded tailored evaluations. This realization led to the development of a family of MLPerf inference benchmarks, each designed to assess performance within a specific deployment setting.
49 MLCommons: Non-profit organization founded in 2018 (originally MLPerf) to develop ML benchmarking standards. Governed by 40+ industry leaders including Google, NVIDIA, Intel, and Facebook, MLCommons has established the de facto standards for AI performance measurement across cloud to edge deployments.
MLPerf Inference
MLPerf Inference serves as the baseline benchmark, originally designed to evaluate large-scale inference systems. It primarily focuses on data center and cloud-based inference workloads, where high throughput, low latency, and efficient resource utilization are essential. The benchmark assesses performance across a range of deep learning models, including image classification, object detection, natural language processing, and recommendation systems. This version of MLPerf remains the gold standard for comparing AI accelerators, GPUs, TPUs, and CPUs in high-performance computing environments.
Major technology companies regularly reference MLPerf results for hardware procurement decisions. When evaluating hardware for recommendation systems infrastructure, MLPerf benchmark scores on DLRM50 (Deep Learning Recommendation Model) workloads directly inform choices between different accelerator generations. Benchmarks consistently show that newer GPU architectures deliver 2-3x higher throughput on recommendation inference compared to previous generations, often justifying premium costs for production deployment at scale. This demonstrates how standardized benchmarks translate directly into multi-million dollar infrastructure decisions across the industry.
50 DLRM (Deep Learning Recommendation Model): Facebook’s neural network architecture for personalized recommendations, released in 2019, combining categorical features through embedding tables with continuous features through multi-layer perceptrons. DLRM models can contain 100+ billion parameters with embedding tables consuming terabytes of memory, requiring specialized hardware optimization for the sparse matrix operations that dominate recommendation system workloads.
The Cost of Comprehensive Benchmarking
While benchmarking is essential for ML system development, it comes with substantial costs that limit participation to well-resourced organizations. Submitting to MLPerf can require significant engineering effort and hundreds of thousands of dollars in hardware and cloud compute time. A comprehensive MLPerf Training submission involves months of engineering time for optimization, tuning, and validation across multiple hardware configurations. The computational costs alone can exceed $100,000 for a full submission covering multiple workloads and system scales.
This cost barrier explains why MLPerf submissions are dominated by major technology companies and hardware vendors, while smaller organizations rely on published results rather than conducting their own comprehensive evaluations. The high barrier to entry motivates the need for more lightweight, internal benchmarking practices that organizations can use to make informed decisions without the expense of full-scale standardized benchmarking.
MLPerf Mobile
MLPerf Mobile extends MLPerf’s evaluation framework to smartphones and other mobile devices. Unlike cloud-based inference, mobile inference operates under strict power and memory constraints, requiring models to be optimized for efficiency without sacrificing responsiveness. The benchmark measures latency and responsiveness for real-time AI tasks, such as camera-based scene detection, speech recognition, and augmented reality applications. MLPerf Mobile has become an industry standard for assessing AI performance on flagship smartphones and mobile AI chips, helping developers optimize models for on-device AI workloads.
MLPerf Client
MLPerf Client focuses on inference performance on consumer computing devices, such as laptops, desktops, and workstations. This benchmark addresses local AI workloads that run directly on personal devices, eliminating reliance on cloud inference. Tasks such as real-time video editing, speech-to-text transcription, and AI-enhanced productivity applications fall under this category. Unlike cloud-based benchmarks, MLPerf Client evaluates how AI workloads interact with general-purpose hardware, such as CPUs, discrete GPUs, and integrated Neural Processing Units (NPUs), making it relevant for consumer and enterprise AI applications.
MLPerf Tiny
MLPerf Tiny was created to benchmark embedded and ultra-low-power AI systems, such as IoT devices, wearables, and microcontrollers. Unlike other MLPerf benchmarks, which assess performance on powerful accelerators, MLPerf Tiny evaluates inference on devices with limited compute, memory, and power resources. This benchmark is particularly relevant for applications such as smart sensors, AI-driven automation, and real-time industrial monitoring, where models must run efficiently on hardware with minimal processing capabilities. MLPerf Tiny plays a crucial role in the advancement of AI at the edge, helping developers optimize models for constrained environments.
Evolution and Future Directions
The evolution of MLPerf Inference from a single benchmark to a spectrum of benchmarks reflects the diversity of AI deployment scenarios. Different environments, including cloud, mobile, desktop, and embedded environments, have unique constraints and requirements, and MLPerf provides a structured way to evaluate AI models accordingly.
MLPerf is an essential tool for:
Understanding how inference performance varies across deployment settings.
Learning which performance metrics are most relevant for different AI applications.
Optimizing models and hardware choices based on real-world usage constraints.
Recognizing the necessity of tailored inference benchmarks deepens our understanding of AI deployment challenges and highlights the importance of benchmarking in developing efficient, scalable, and practical machine learning systems.
Energy efficiency considerations are integrated throughout Training (Section 8.2) and Inference (Section 8.3) benchmark methodologies, recognizing that power consumption affects both phases differently. Training energy costs are amortized across model lifetime, while inference energy costs accumulate per query and directly impact operational efficiency. The following analysis of power measurement techniques supports the energy metrics covered within each benchmarking phase.
Power Measurement Techniques
Energy efficiency benchmarking requires specialized measurement techniques that account for the diverse power scales across ML deployment environments. Building upon energy considerations established in training and inference sections, these techniques enable systematic validation of optimization claims from Chapter 10: Model Optimizations and hardware efficiency improvements from Chapter 11: AI Acceleration.
While performance benchmarks help optimize speed and accuracy, they do not always account for energy efficiency, which has become an increasingly critical factor in real-world deployment. The energy efficiency principles from Chapter 9: Efficient AI, balancing computational complexity, memory access patterns, and hardware utilization, require quantitative validation through standardized energy benchmarks. These benchmarks enable us to verify whether architectural optimizations from Chapter 10: Model Optimizations and hardware-aware designs from Chapter 11: AI Acceleration actually deliver promised energy savings in practice.
However, measuring power consumption in machine learning systems presents fundamentally unique challenges. The energy demands of ML models vary dramatically across deployment environments, spanning multiple orders of magnitude as shown in Table 5. This wide spectrum, spanning from TinyML devices consuming mere microwatts to data center racks requiring kilowatts, illustrates the fundamental challenge in creating standardized benchmarking methodologies (Henderson et al. 2020).
Henderson, Peter, Jieru Hu, Joshua Romoff, Emma Brunskill, Dan Jurafsky, and Joelle Pineau. 2020. “Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning.” CoRR abs/2002.05651 (248): 1–43. https://doi.org/10.48550/arxiv.2002.05651.
| Category | Device Type | Power Consumption |
|---|---|---|
| Tiny | Neural Decision Processor (NDP) | 150 µW |
| Tiny | M7 Microcontroller | 25 mW |
| Mobile | Raspberry Pi 4 | 3.5 W |
| Mobile | Smartphone | 4 W |
| Edge | Smart Camera | 10-15 W |
| Edge | Edge Server | 65-95 W |
| Cloud | ML Server Node | 300-500 W |
| Cloud | ML Server Rack | 4-10 kW |
This dramatic range in power requirements, which spans over four orders of magnitude, presents significant challenges for measurement and benchmarking. Consequently, creating a unified methodology requires careful consideration of each scale’s unique characteristics. For example, accurately measuring microwatt-level consumption in TinyML devices demands different instrumentation and techniques than monitoring kilowatt-scale server racks. Any comprehensive benchmarking framework must accommodate these vastly different scales while ensuring measurements remain consistent, fair, and reproducible across diverse hardware configurations.
Power Measurement Boundaries
To address these measurement challenges, Figure 8 illustrates how power consumption is measured at different system scales, from TinyML devices to full-scale data center inference nodes. Each scenario highlights distinct measurement boundaries, shown in green, which indicate the components included in energy accounting. Components outside these boundaries, shown with red dashed outlines, are excluded from power measurements.

The diagram is organized into three categories, Tiny, Inference, and Training examples, each reflecting different measurement scopes based on system architecture and deployment environment. In TinyML systems, the entire low-power SoC, including compute, memory, and basic interconnects, typically falls within the measurement boundary. Inference nodes introduce more complexity, incorporating multiple SoCs, local storage, accelerators, and memory, while often excluding remote storage and off-chip components. Training deployments span multiple racks, where only selected elements, including compute nodes and network switches, are measured, while storage systems, cooling infrastructure, and parts of the interconnect fabric are often excluded.
System-level power measurement offers a more holistic view than measuring individual components in isolation. While component-level metrics (e.g., accelerator or processor power) are valuable for performance tuning, real-world ML workloads involve intricate interactions between compute units, memory systems, and supporting infrastructure. For instance, analysis of Google’s TensorFlow Mobile workloads shows that data movement accounts for 57.3% of total inference energy consumption (Boroumand et al. 2018), highlighting how memory-bound operations can dominate system power usage.
Boroumand, Amirali, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul Thakur, Daehyun Kim, et al. 2018. “Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks.” In Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems, 316–31. ASPLOS ’18. ACM. https://doi.org/10.1145/3173162.3173177.
Barroso, Luiz André, Jimmy Clidaras, and Urs Hölzle. 2013. The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines. Springer International Publishing. https://doi.org/10.1007/978-3-031-01741-4.
Shared infrastructure presents additional challenges. In data centers, resources such as cooling systems and power delivery are shared across workloads, complicating attribution of energy use to specific ML tasks. Cooling alone can account for 20-30% of total facility power consumption, making it a major factor in energy efficiency assessments (Barroso, Clidaras, and Hölzle 2013). Even at the edge, components like memory and I/O interfaces may serve both ML and non-ML functions, further blurring measurement boundaries.
Shared infrastructure complexity is further compounded by dynamic power management techniques that modern systems employ to optimize energy efficiency. Dynamic voltage and frequency scaling (DVFS) adjusts processor voltage and clock frequency based on workload demands, enabling significant power reductions during periods of lower computational intensity. Advanced DVFS implementations using on-chip switching regulators can achieve substantial energy savings (Kim et al. 2008), causing power consumption to vary by 30-50% for the same ML model depending on system load and concurrent activity. This variability affects not only the compute components but also the supporting infrastructure, as reduced processor activity can lower cooling requirements and overall facility power draw.
Kim, Wonyoung, Meeta S. Gupta, Gu-Yeon Wei, and David Brooks. 2008. “System Level Analysis of Fast, Per-Core DVFS Using on-Chip Switching Regulators.” In 2008 IEEE 14th International Symposium on High Performance Computer Architecture, 123–34. HPCA ’08. IEEE. https://doi.org/10.1109/hpca.2008.4658633.
Barroso, Luiz André, Urs Hölzle, and Parthasarathy Ranganathan. 2019. The Datacenter as a Computer: Designing Warehouse-Scale Machines. Springer International Publishing. https://doi.org/10.1007/978-3-031-01761-2.
Support infrastructure, particularly cooling systems, is a major component of total energy consumption in large-scale deployments. Data centers must maintain operational temperatures, typically between 20-25°C, to ensure system reliability. Cooling overhead is captured in the Power Usage Effectiveness (PUE) metric, which ranges from 1.1 in highly efficient facilities to over 2.0 in less optimized ones (Barroso, Hölzle, and Ranganathan 2019). The interaction between compute workloads and cooling infrastructure creates complex dependencies; for example, power management techniques like DVFS not only reduce direct processor power consumption but also decrease heat generation, creating cascading effects on cooling requirements. Even edge devices require basic thermal management.
Computational Efficiency vs. Power Consumption
The relationship between computational performance and energy efficiency is one of the most important tradeoffs in modern ML system design. As systems push for higher performance, they often encounter diminishing returns in energy efficiency due to fundamental physical limitations in semiconductor scaling and power delivery (Koomey et al. 2011). This relationship is particularly evident in processor frequency scaling, where increasing clock frequency by 20% typically yields only modest performance improvements (around 5%) while dramatically increasing power consumption by up to 50%, reflecting the cubic relationship between voltage, frequency, and power consumption (Le Sueur and Heiser 2010).
Koomey, Jonathan, Stephen Berard, Marla Sanchez, and Henry Wong. 2011. “Implications of Historical Trends in the Electrical Efficiency of Computing.” IEEE Annals of the History of Computing 33 (3): 46–54. https://doi.org/10.1109/mahc.2010.28.
Le Sueur, Etienne, and Gernot Heiser. 2010. “Dynamic Voltage and Frequency Scaling: The Laws of Diminishing Returns.” In Proceedings of the 2010 International Conference on Power Aware Computing and Systems, 1–8.
In deployment scenarios with strict energy constraints, particularly battery-powered edge devices and mobile applications, optimizing this performance-energy tradeoff becomes essential for practical viability. Model optimization techniques offer promising approaches to achieve better efficiency without significant accuracy degradation. Numerical precision optimization techniques, which reduce computational requirements while maintaining model quality, demonstrate this tradeoff effectively. Research shows that reduced-precision computation can maintain model accuracy within 1-2% of the original while delivering 3-4x improvements in both inference speed and energy efficiency.
These optimization strategies span three interconnected dimensions: accuracy, computational performance, and energy efficiency. Advanced optimization methods enable fine-tuned control over this tradeoff space. Similarly, model optimization and compression techniques require careful balancing of accuracy losses against efficiency gains. The optimal operating point among these factors depends heavily on deployment requirements and constraints; mobile applications typically prioritize energy efficiency to extend battery life, while cloud-based services might optimize for accuracy even at higher power consumption costs, leveraging economies of scale and dedicated cooling infrastructure.
As benchmarking methodologies continue to evolve, energy efficiency metrics are becoming increasingly central to AI system evaluation and optimization. The integration of power measurement standards, such as those established in MLPerf Power (Tschand et al. 2024), provides standardized frameworks for comparing energy efficiency across diverse hardware platforms and deployment scenarios. Future advancements in sustainable AI benchmarking will help researchers and engineers design systems that systematically balance performance, power consumption, and environmental impact, ensuring that ML systems operate efficiently while minimizing unnecessary energy waste and supporting broader sustainability goals.
Standardized Power Measurement
While power measurement techniques, such as SPEC Power, have long existed for general computing systems (Lange 2009), machine learning workloads present unique challenges that require specialized measurement approaches. Machine learning systems exhibit distinct power consumption patterns characterized by phases of intense computation interspersed with data movement and preprocessing operations. These patterns vary significantly across different types of models and tasks. A large language model’s power profile looks very different from that of a computer vision inference task.
Lange, Klaus-Dieter. 2009. “Identifying Shades of Green: The SPECpower Benchmarks.” Computer 42 (3): 95–97. https://doi.org/10.1109/mc.2009.84.
Direct power measurement requires careful consideration of sampling rates and measurement windows. For example, certain neural network architectures create short, intense power spikes during complex computations, requiring high-frequency sampling (> 1 KHz) to capture accurately. In contrast, CNN inference tends to show more consistent power draw patterns that can be captured with lower sampling rates. The measurement duration must also account for ML-specific behaviors like warm-up periods, where initial inferences may consume more power due to cache population and pipeline initialization.
Memory access patterns in ML workloads significantly impact power consumption measurements. While traditional compute benchmarks might focus primarily on processor power, ML systems often spend substantial energy moving data between memory hierarchies. For example, recommendation models like DLRM can spend more energy on memory access than computation. This requires measurement approaches that can capture both compute and memory subsystem power consumption.
Accelerator-specific considerations further complicate power measurement. Many ML systems employ specialized hardware like GPUs, TPUs, or NPUs. These accelerators often have their own power management schemes and can operate independently of the main system processor. Accurate measurement requires capturing power consumption across all relevant compute units while maintaining proper time synchronization. This is particularly challenging in heterogeneous systems that may dynamically switch between different compute resources based on workload characteristics or power constraints.
The scale and distribution of ML workloads also influences measurement methodology. In distributed training scenarios, power measurement must account for both local compute power and the energy cost of gradient synchronization across nodes. Similarly, edge ML deployments must consider both active inference power and the energy cost of model updates or data preprocessing.
Batch size and throughput considerations add another layer of complexity. Unlike traditional computing workloads, ML systems often process inputs in batches to improve computational efficiency. However, the relationship between batch size and power consumption is non-linear. While larger batches generally improve compute efficiency, they also increase memory pressure and peak power requirements. Measurement methodologies must therefore capture power consumption across different batch sizes to provide a complete efficiency profile.
System idle states require special attention in ML workloads, particularly in edge scenarios where systems operate intermittently, actively processing when new data arrives, then entering low-power states between inferences. A wake-word detection Tiny ML system, for instance, might only actively process audio for a small fraction of its operating time, making idle power consumption a critical factor in overall efficiency.
Temperature effects play a crucial role in ML system power measurement. Sustained ML workloads can cause significant temperature increases, triggering thermal throttling and changing power consumption patterns. This is especially relevant in edge devices where thermal constraints may limit sustained performance. Measurement methodologies must account for these thermal effects and their impact on power consumption, particularly during extended benchmarking runs.
MLPerf Power Case Study
MLPerf Power (Tschand et al. 2024) is a standard methodology for measuring energy efficiency in machine learning systems. This comprehensive benchmarking framework provides accurate assessment of power consumption across diverse ML deployments. At the datacenter level, it measures power usage in large-scale AI workloads, where energy consumption optimization directly impacts operational costs. For edge computing, it evaluates power efficiency in consumer devices like smartphones and laptops, where battery life constraints are critical. In tiny inference scenarios, it assesses energy consumption for ultra-low-power AI systems, particularly IoT sensors and microcontrollers operating with strict power budgets.
The MLPerf Power methodology applies the standardized evaluation principles discussed earlier, adapting to various hardware architectures from general-purpose CPUs to specialized AI accelerators. This approach ensures meaningful cross-platform comparisons while maintaining measurement integrity across different computing scales.
The benchmark has accumulated thousands of reproducible measurements submitted by industry organizations, which demonstrates their latest hardware capabilities and the sector-wide focus on energy-efficient AI technology. Figure 9 illustrates the evolution of energy efficiency across system scales through successive MLPerf versions.

Tschand, Arya, Arun Tejusve Raghunath Rajan, Sachin Idgunji, Anirban Ghosh, Jeremy Holleman, Csaba Kiraly, Pawan Ambalkar, et al. 2024. “MLPerf Power: Benchmarking the Energy Efficiency of Machine Learning Systems from Microwatts to Megawatts for Sustainable AI.” arXiv Preprint arXiv:2410.12032, October. http://arxiv.org/abs/2410.12032v2.
The MLPerf Power methodology adapts to different hardware architectures, ranging from general-purpose CPUs to specialized AI accelerators, while maintaining a uniform measurement standard. This ensures that comparisons across platforms are meaningful and unbiased.
Across the versions and ML deployment scales of the MLPerf benchmark suite, industry organizations have submitted reproducible measurements on their most recent hardware to observe and quantify the industry-wide emphasis on optimizing AI technology for energy efficiency. Figure 9 shows the trends in energy efficiency from tiny to datacenter scale systems across MLPerf versions.
Analysis of these trends reveals two significant patterns: first, a plateauing of energy efficiency improvements across all three scales for traditional ML workloads, and second, a dramatic increase in energy efficiency specifically for generative AI applications. This dichotomy suggests both the maturation of optimization techniques for conventional ML tasks and the rapid innovation occurring in the generative AI space. These trends underscore the dual challenges facing the field: developing novel approaches to break through efficiency plateaus while ensuring sustainable scaling practices for increasingly powerful generative AI models.
Benchmarking Limitations and Best Practices
Effective benchmarking requires understanding its inherent limitations and implementing practices that mitigate these constraints. Rather than avoiding benchmarks due to their limitations, successful practitioners recognize these challenges and adapt their methodology accordingly. The following analysis examines four interconnected categories of benchmarking challenges while providing actionable guidance for addressing each limitation through improved design and interpretation practices.
Statistical & Methodological Issues
The foundation of reliable benchmarking rests on sound statistical methodology. Three fundamental issues undermine this foundation if left unaddressed.
Incomplete problem coverage represents one of the most fundamental limitations. Many benchmarks, while useful for controlled comparisons, fail to capture the full diversity of real-world applications. For instance, common image classification datasets, such as CIFAR-10, contain a limited variety of images. As a result, models that perform well on these datasets may struggle when applied to more complex, real-world scenarios with greater variability in lighting, perspective, and object composition. This gap between benchmark tasks and real-world complexity means strong benchmark performance provides limited guarantees about practical deployment success.
Statistical insignificance arises when benchmark evaluations are conducted on too few data samples or trials. For example, testing an optical character recognition (OCR) system on a small dataset may not accurately reflect its performance on large-scale, noisy text documents. Without sufficient trials and diverse input distributions, benchmarking results may be misleading or fail to capture true system reliability. The statistical confidence intervals around benchmark scores often go unreported, obscuring whether measured differences represent genuine improvements or measurement noise.
Reproducibility represents a major ongoing challenge. Benchmark results can vary significantly depending on factors such as hardware configurations, software versions, and system dependencies. Small differences in compilers, numerical precision, or library updates can lead to inconsistent performance measurements across different environments. To mitigate this issue, MLPerf addresses reproducibility by providing reference implementations, standardized test environments, and strict submission guidelines. Even with these efforts, achieving true consistency across diverse hardware platforms remains an ongoing challenge. The proliferation of optimization libraries, framework versions, and compiler flags creates a vast configuration space where slight variations produce different results.
Laboratory-to-Deployment Performance Gaps
Beyond statistical rigor, benchmarks must align with practical deployment objectives. Misalignment with Real-World Goals occurs when benchmarks emphasize metrics such as speed, accuracy, and throughput, but practical AI deployments often require balancing multiple objectives, including power efficiency, cost, and robustness. A model that achieves state-of-the-art accuracy on a benchmark may be impractical for deployment if it consumes excessive energy or requires expensive hardware. Similarly, optimizing for average-case performance on benchmark datasets may neglect tail-latency requirements that determine user experience in production systems. The multi-objective nature of real deployment, encompassing resource constraints, operational costs, maintenance complexity, and business requirements, extends far beyond the single-metric optimization that most benchmarks reward.
System Design Challenges
Physical and architectural factors introduce additional variability that benchmarks must address using our established comparison methodologies across diverse deployment contexts.
Environmental Conditions
Environmental conditions in AI benchmarking refer to the physical and operational circumstances under which experiments are conducted. These conditions, while often overlooked in benchmark design, can significantly influence benchmark results and impact the reproducibility of experiments. Physical environmental factors include ambient temperature, humidity, air quality, and altitude. These elements can affect hardware performance in subtle but measurable ways. For instance, elevated temperatures may lead to thermal throttling in processors, potentially reducing computational speed and affecting benchmark outcomes. Similarly, variations in altitude can impact cooling system efficiency and hard drive performance due to changes in air pressure.
Beyond physical factors, operational environmental factors encompass the broader system context in which benchmarks are executed. This includes background processes running on the system, network conditions, and power supply stability. The presence of other active programs or services can compete for computational resources, potentially altering the performance characteristics of the model under evaluation. To ensure the validity and reproducibility of benchmark results, it is essential to document and control these environmental conditions to the extent possible. This may involve conducting experiments in temperature-controlled environments, monitoring and reporting ambient conditions, standardizing the operational state of benchmark systems, and documenting any background processes or system loads.
In scenarios where controlling all environmental variables is impractical, such as in distributed or cloud-based benchmarking, it becomes essential to report these conditions in detail. This information allows other researchers to account for potential variations when interpreting or attempting to reproduce results. As machine learning models are increasingly deployed in diverse real-world environments, understanding the impact of environmental conditions on model performance becomes even more critical. This knowledge not only ensures more accurate benchmarking but also informs the development of robust models capable of consistent performance across varying operational conditions.
Hardware Lottery
A critical and often underappreciated issue in benchmarking is what has been described as the hardware lottery51, a concept introduced by (Hooker 2021). The success of a machine learning model is often dictated not only by its architecture and training data but also by how well it aligns with the underlying hardware used for inference. Some models perform exceptionally well, not because they are inherently better, but because they are optimized for the parallel processing capabilities of GPUs or TPUs. Meanwhile, other promising architectures may be overlooked because they do not map efficiently to dominant hardware platforms.
51 Hardware Lottery: The phenomenon where algorithmic progress is heavily influenced by which approaches happen to align well with available hardware. For example, the Transformer architecture succeeded partly because its matrix multiplication operations perfectly match GPU capabilities, while equally valid architectures like graph neural networks remain underexplored due to poor GPU mapping. This suggests some “breakthrough” algorithms may simply be hardware-compatible rather than fundamentally superior.
Hooker, Sara. 2021. “The Hardware Lottery.” Communications of the ACM 64 (12): 58–65. https://doi.org/10.1145/3467017.
This dependence on hardware compatibility introduces subtle but significant biases into benchmarking results. A model that is highly efficient on a specific GPU may perform poorly on a CPU or a custom AI accelerator. For instance, Figure 10 compares the performance of models across different hardware platforms. The multi-hardware models show comparable results to “MobileNetV3 Large min” on both the CPU uint8 and GPU configurations. However, these multi-hardware models demonstrate significant performance improvements over the MobileNetV3 Large baseline when run on the EdgeTPU and DSP hardware. This emphasizes the variable efficiency of multi-hardware models in specialized computing environments.

Chu, Grace, Okan Arikan, Gabriel Bender, Weijun Wang, Achille Brighton, Pieter-Jan Kindermans, Hanxiao Liu, Berkin Akin, Suyog Gupta, and Andrew Howard. 2021. “Discovering Multi-Hardware Mobile Models via Architecture Search.” In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 34:3016–25. IEEE. https://doi.org/10.1109/cvprw53098.2021.00337.
Without careful benchmarking across diverse hardware configurations, the field risks favoring architectures that “win” the hardware lottery rather than selecting models based on their intrinsic strengths. This bias can shape research directions, influence funding allocation, and impact the design of next-generation AI systems. In extreme cases, it may even stifle innovation by discouraging exploration of alternative architectures that do not align with current hardware trends.
Organizational & Strategic Issues
Competitive pressures and research incentives create systematic biases in how benchmarks are used and interpreted. These organizational dynamics require governance mechanisms and community standards to maintain benchmark integrity.
Benchmark Engineering
While the hardware lottery is an unintended consequence of hardware trends, benchmark engineering is an intentional practice where models or systems are explicitly optimized to excel on specific benchmark tests. This practice can lead to misleading performance claims and results that do not generalize beyond the benchmarking environment.
Benchmark engineering occurs when AI developers fine-tune hyperparameters, preprocessing techniques, or model architectures specifically to maximize benchmark scores rather than improve real-world performance. For example, an object detection model might be carefully optimized to achieve record-low latency on a benchmark but fail when deployed in dynamic, real-world environments with varying lighting, motion blur, and occlusions. Similarly, a language model might be tuned to excel on benchmark datasets but struggle when processing conversational speech with informal phrasing and code-switching.
The pressure to achieve high benchmark scores is often driven by competition, marketing, and research recognition. Benchmarks are frequently used to rank AI models and systems, creating an incentive to optimize specifically for them. While this can drive technical advancements, it also risks prioritizing benchmark-specific optimizations at the expense of broader generalization. This phenomenon exemplifies Goodhart’s Law52.
52 Goodhart’s Law: Originally articulated by British economist Charles Goodhart in 1975, this principle states: “When a measure becomes a target, it ceases to be a good measure.” In ML systems benchmarking, this captures the fundamental tension between using benchmarks as indicators of system quality and the tendency for practitioners to optimize specifically for benchmark scores rather than underlying performance characteristics. As benchmarks become targets for optimization, they progressively lose their value as meaningful proxies for real-world system effectiveness.
Bias and Over-Optimization
To ensure that benchmarks remain useful and fair, several strategies can be employed. Transparency is one of the most important factors in maintaining benchmarking integrity. Benchmark submissions should include detailed documentation on any optimizations applied, ensuring that improvements are clearly distinguished from benchmark-specific tuning. Researchers and developers should report both benchmark performance and real-world deployment results to provide a complete picture of a system’s capabilities.
Another approach is to diversify and evolve benchmarking methodologies. Instead of relying on a single static benchmark, AI systems should be evaluated across multiple, continuously updated benchmarks that reflect real-world complexity. This reduces the risk of models being overfitted to a single test set and encourages general-purpose improvements rather than narrow optimizations.
Standardization and third-party verification can also help mitigate bias. By establishing industry-wide benchmarking standards and requiring independent third-party audits of results, the AI community can improve the reliability and credibility of benchmarking outcomes. Third-party verification ensures that reported results are reproducible across different settings and helps prevent unintentional benchmark gaming.
Another important strategy is application-specific testing. While benchmarks provide controlled evaluations, real-world deployment testing remains essential. AI models should be assessed not only on benchmark datasets but also in practical deployment environments. For instance, an autonomous driving model should be tested in a variety of weather conditions and urban settings rather than being judged solely on controlled benchmark datasets.
Finally, fairness across hardware platforms must be considered. Benchmarks should test AI models on multiple hardware configurations to ensure that performance is not being driven solely by compatibility with a specific platform. This helps reduce the risk of the hardware lottery and provides a more balanced evaluation of AI system efficiency.
Benchmark Evolution
One of the greatest challenges in benchmarking is that benchmarks are never static. As AI systems evolve, so must the benchmarks that evaluate them. What defines “good performance” today may be irrelevant tomorrow as models, hardware, and application requirements change. While benchmarks are essential for tracking progress, they can also quickly become outdated, leading to over-optimization for old metrics rather than real-world performance improvements.
This evolution is evident in the history of AI benchmarks. Early model benchmarks, for instance, focused heavily on image classification and object detection, as these were some of the first widely studied deep learning tasks. However, as AI expanded into natural language processing, recommendation systems, and generative AI, it became clear that these early benchmarks no longer reflected the most important challenges in the field. In response, new benchmarks emerged to measure language understanding (Wang et al. 2018, 2019) and generative AI (Liang et al. 2022).
Wang, Alex, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2018. “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.” arXiv Preprint arXiv:1804.07461, April. http://arxiv.org/abs/1804.07461v3.
Wang, Alex, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.” arXiv Preprint arXiv:1905.00537, May. http://arxiv.org/abs/1905.00537v3.
Liang, Percy, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, et al. 2022. “Holistic Evaluation of Language Models.” arXiv Preprint arXiv:2211.09110, November. http://arxiv.org/abs/2211.09110v2.
Duarte, Javier, Nhan Tran, Ben Hawks, Christian Herwig, Jules Muhizi, Shvetank Prakash, and Vijay Janapa Reddi. 2022a. “FastML Science Benchmarks: Accelerating Real-Time Scientific Edge Machine Learning.” arXiv Preprint arXiv:2207.07958, July. http://arxiv.org/abs/2207.07958v1.
Benchmark evolution extends beyond the addition of new tasks to encompass new dimensions of performance measurement. While traditional AI benchmarks emphasized accuracy and throughput, modern applications demand evaluation across multiple criteria: fairness, robustness, scalability, and energy efficiency. Figure 11 illustrates this complexity through scientific applications, which span orders of magnitude in their performance requirements. For instance, Large Hadron Collider sensors must process data at rates approaching 10\(^{14}\) bytes per second (equivalent to about 100 terabytes per second) with nanosecond-scale computation times, while mobile applications operate at 10\(^{4}\) bytes per second with longer computational windows. This range of requirements necessitates specialized benchmarks. For example, edge AI applications require benchmarks like MLPerf that specifically evaluate performance under resource constraints and scientific application domains need their own “Fast ML for Science” benchmarks (Duarte et al. 2022a).

———. 2022b. “FastML Science Benchmarks: Accelerating Real-Time Scientific Edge Machine Learning,” July. http://arxiv.org/abs/2207.07958v1.
The need for evolving benchmarks also presents a challenge: stability versus adaptability. On the one hand, benchmarks must remain stable for long enough to allow meaningful comparisons over time. If benchmarks change too frequently, it becomes difficult to track long-term progress and compare new results with historical performance. On the other hand, failing to update benchmarks leads to stagnation, where models are optimized for outdated tasks rather than advancing the field. Striking the right balance between benchmark longevity and adaptation is an ongoing challenge for the AI community.
Despite these difficulties, evolving benchmarks is essential for ensuring that AI progress remains meaningful. Without updates, benchmarks risk becoming detached from real-world needs, leading researchers and engineers to focus on optimizing models for artificial test cases rather than solving practical challenges. As AI continues to expand into new domains, benchmarking must keep pace, ensuring that performance evaluations remain relevant, fair, and aligned with real-world deployment scenarios.
MLPerf as Industry Standard
MLPerf has played a crucial role in improving benchmarking by reducing bias, increasing generalizability, and ensuring benchmarks evolve alongside AI advancements. One of its key contributions is the standardization of benchmarking environments. By providing reference implementations, clearly defined rules, and reproducible test environments, MLPerf ensures that performance results are consistent across different hardware and software platforms, reducing variability in benchmarking outcomes.
Recognizing that AI is deployed in a variety of real-world settings, MLPerf has also introduced different categories of inference benchmarks that align with our three-dimensional framework. The inclusion of MLPerf Inference, MLPerf Mobile, MLPerf Client, and MLPerf Tiny reflects an effort to evaluate models across different deployment constraints while maintaining the systematic evaluation principles established throughout this chapter.
Beyond providing a structured benchmarking framework, MLPerf is continuously evolving to keep pace with the rapid progress in AI. New tasks are incorporated into benchmarks to reflect emerging challenges, such as generative AI models and energy-efficient computing, ensuring that evaluations remain relevant and forward-looking. By regularly updating its benchmarking methodologies, MLPerf helps prevent benchmarks from becoming outdated or encouraging overfitting to legacy performance metrics.
By prioritizing fairness, transparency, and adaptability, MLPerf ensures that benchmarking remains a meaningful tool for guiding AI research and deployment. Instead of simply measuring raw speed or accuracy, MLPerf’s evolving benchmarks aim to capture the complexities of real-world AI performance, ultimately fostering more reliable, efficient, and impactful AI systems.
Model and Data Benchmarking
Our three-dimensional benchmarking framework encompasses systems (covered extensively above), models, and data. While system benchmarking has been our primary focus, comprehensive AI evaluation requires understanding how algorithmic and data quality factors complement system performance measurement. AI performance is not determined by system efficiency alone. Machine learning models and datasets play an equally crucial role in shaping AI capabilities. Model benchmarking evaluates algorithmic performance, while data benchmarking ensures that training datasets are high-quality, unbiased, and representative of real-world distributions. Understanding these aspects is vital because AI systems are not just computational pipelines but are deeply dependent on the models they execute and the data they are trained on.
Model Benchmarking
Model benchmarks measure how well different machine learning algorithms perform on specific tasks. Historically, benchmarks focused almost exclusively on accuracy, but as models have grown more complex, additional factors, including fairness, robustness, efficiency, and generalizability, have become equally important.
The evolution of machine learning has been largely driven by benchmark datasets. The MNIST dataset (Lecun et al. 1998) was one of the earliest catalysts, advancing handwritten digit recognition, while the ImageNet dataset (Deng et al. 2009) sparked the deep learning revolution in image classification. More recently, datasets like COCO (Lin et al. 2014) for object detection and GPT-3’s training corpus (Brown et al. 2020) have pushed the boundaries of model capabilities even further.
Lecun, Y., L. Bottou, Y. Bengio, and P. Haffner. 1998. “Gradient-Based Learning Applied to Document Recognition.” Proceedings of the IEEE 86 (11): 2278–2324. https://doi.org/10.1109/5.726791.
Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. “ImageNet: A Large-Scale Hierarchical Image Database.” In 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–55. Ieee; IEEE. https://doi.org/10.1109/cvpr.2009.5206848.
Lin, Tsung-Yi, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. “Microsoft COCO: Common Objects in Context.” In Computer Vision – ECCV 2014, 740–55. Springer; Springer International Publishing. https://doi.org/10.1007/978-3-319-10602-1\_48.
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models Are Few-Shot Learners.” Edited by Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin. Advances in Neural Information Processing Systems 33 (May): 1877–1901. https://doi.org/10.48550/arxiv.2005.14165.
Xu, Ruijie, Zengzhi Wang, Run-Ze Fan, and Pengfei Liu. 2024. “Benchmarking Benchmark Leakage in Large Language Models.” arXiv Preprint arXiv:2404.18824, April. http://arxiv.org/abs/2404.18824v1.
However, model benchmarks face significant limitations, particularly in the era of Large Language Models (LLMs). Beyond the traditional challenge of models failing in real-world conditions, commonly referred to as the Sim2Real gap, a new form of benchmark optimization has emerged, analogous to but distinct from classical benchmark engineering in computer systems. In traditional systems evaluation, developers would explicitly optimize their code implementations to perform well on benchmark suites like SPEC or TPC, which we discussed earlier under “Benchmark Engineering”. In the case of LLMs, this phenomenon manifests through data rather than code: benchmark datasets may inadvertently appear in training data when models are trained on large web corpora, leading to artificially inflated performance scores that reflect memorization rather than genuine capability. For example, if a benchmark test is widely discussed online, it might be included in the web data used to train an LLM, making the model perform well on that test not due to genuine understanding but due to having seen similar examples during training (Xu et al. 2024). This creates fundamental challenges for model evaluation, as high performance on benchmark tasks may reflect memorization rather than genuine capability. The key distinction lies in the mechanism: while systems benchmark engineering occurred through explicit code optimization, LLM benchmark adaptation can occur implicitly through data exposure during pre-training, raising new questions about the validity of current evaluation methodologies.
These challenges extend beyond just LLMs. Traditional machine learning systems continue to struggle with problems of overfitting and bias. The Gender Shades project (Buolamwini and Gebru 2018), for instance, revealed that commercial facial recognition models performed significantly worse on darker-skinned individuals, highlighting the critical importance of fairness in model evaluation. Such findings underscore the limitations of focusing solely on aggregate accuracy metrics.
Buolamwini, Joy, and Timnit Gebru. 2018. “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification.” In Conference on Fairness, Accountability and Transparency, 77–91. PMLR. http://proceedings.mlr.press/v81/buolamwini18a.html.
Moving forward, we must fundamentally rethink its approach to benchmarking. This evolution requires developing evaluation frameworks that go beyond traditional metrics to assess multiple dimensions of model behavior, from generalization and robustness to fairness and efficiency. Key challenges include creating benchmarks that remain relevant as models advance, developing methodologies that can differentiate between genuine capabilities and artificial performance gains, and establishing standards for benchmark documentation and transparency. Success in these areas will help ensure that benchmark results provide meaningful insights about model capabilities rather than reflecting artifacts of training procedures or evaluation design.
Data Benchmarking
The evolution of artificial intelligence has traditionally focused on model-centric approaches, emphasizing architectural improvements and optimization techniques. However, contemporary AI development reveals that data quality, rather than model design alone, often determines performance boundaries. This recognition has elevated data benchmarking to a critical field that ensures AI models learn from datasets that are high-quality, diverse, and free from bias.
This evolution represents a fundamental shift from model-centric to data-centric AI approaches, as illustrated in Figure 12. The traditional model-centric paradigm focuses on enhancing model architectures, refining algorithms, and improving computational efficiency while treating datasets as fixed components. In contrast, the emerging data-centric approach systematically improves dataset quality through better annotations, increased diversity, and bias reduction, while maintaining consistent model architectures and system configurations. Research increasingly demonstrates that methodical dataset enhancement can yield superior performance gains compared to model refinements alone, challenging the conventional emphasis on architectural innovation.

Data quality’s primacy in AI development reflects a fundamental shift in understanding: superior datasets, not just sophisticated models, produce more reliable and robust AI systems. Initiatives like DataPerf and DataComp have emerged to systematically evaluate how dataset improvements affect model performance. For instance, DataComp (Nishigaki 2024) demonstrated that models trained on a carefully curated 30% subset of data achieved better results than those trained on the complete dataset, challenging the assumption that more data automatically leads to better performance (Northcutt, Athalye, and Mueller 2021).
Nishigaki, Shinsuke. 2024. “Eigenphase Distributions of Unimodular Circular Ensembles.” arXiv Preprint arXiv:2401.09045 36 (January). http://arxiv.org/abs/2401.09045v2.
Northcutt, Curtis G., Anish Athalye, and Jonas Mueller. 2021. “Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks.” arXiv Preprint arXiv:2103.14749 34 (March): 19075–90. https://doi.org/10.48550/arxiv.2103.14749.
A significant challenge in data benchmarking emerges from dataset saturation. When models achieve near-perfect accuracy on benchmarks like ImageNet, it becomes crucial to distinguish whether performance gains represent genuine advances in AI capability or merely optimization to existing test sets. Figure 13 illustrates this trend, showing AI systems surpassing human performance across various applications over the past decade.

This saturation phenomenon raises fundamental methodological questions (Kiela et al. 2021). The MNIST dataset provides an illustrative example: certain test images, though nearly illegible to humans, were assigned specific labels during the dataset’s creation in 1994. When models correctly predict these labels, their apparent superhuman performance may actually reflect memorization of dataset artifacts rather than true digit recognition capabilities.
Kiela, Douwe, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, et al. 2021. “Dynabench: Rethinking Benchmarking in NLP.” In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 9:418–34. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.naacl-main.324.
Beyer, Lucas, Olivier J. Hénaff, Alexander Kolesnikov, Xiaohua Zhai, and Aäron van den Oord. 2020. “Are We Done with ImageNet?” arXiv Preprint arXiv:2006.07159, June. http://arxiv.org/abs/2006.07159v1.
These challenges extend beyond individual domains. The provocative question “Are we done with ImageNet?” (Beyer et al. 2020) highlights broader concerns about the limitations of static benchmarks. Models optimized for fixed datasets often struggle with distribution shifts, real-world changes that occur after training data collection. This limitation has driven the development of dynamic benchmarking approaches, such as Dynabench (Kiela et al. 2021), which continuously evolves test data based on model performance to maintain benchmark relevance.
Current data benchmarking efforts encompass several critical dimensions. Label quality assessment remains a central focus, as explored in DataPerf’s debugging challenge. Initiatives like MSWC (Mazumder et al. 2021) for speech recognition address bias and representation in datasets. Out-of-distribution generalization receives particular attention through benchmarks like RxRx and WILDS (Koh et al. 2021). These diverse efforts reflect a growing recognition that advancing AI capabilities requires not just better models and systems, but fundamentally better approaches to data quality assessment and benchmark design.
Mazumder, Mark, Sharad Chitlangia, Colby Banbury, Yiping Kang, Juan Manuel Ciro, Keith Achorn, Daniel Galvez, et al. 2021. “Multilingual Spoken Words Corpus.” In Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2).
Koh, Pang Wei, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, et al. 2021. “WILDS: A Benchmark of in-the-Wild Distribution Shifts.” In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, edited by Marina Meila and Tong Zhang, 139:5637–64. Proceedings of Machine Learning Research. PMLR. http://proceedings.mlr.press/v139/koh21a.html.
Holistic System-Model-Data Evaluation
AI benchmarking has traditionally evaluated systems, models, and data as separate entities. However, real-world AI performance emerges from the interplay between these three components. A fast system cannot compensate for a poorly trained model, and even the most powerful model is constrained by the quality of the data it learns from. This interdependence necessitates a holistic benchmarking approach that considers all three dimensions together.
As illustrated in Figure 14, the future of benchmarking lies in an integrated framework that jointly evaluates system efficiency, model performance, and data quality. This approach enables researchers to identify optimization opportunities that remain invisible when these components are analyzed in isolation. For example, co-designing efficient AI models with hardware-aware optimizations and carefully curated datasets can lead to superior performance while reducing computational costs.

As AI continues to evolve, benchmarking methodologies must advance in tandem. Evaluating AI performance through the lens of systems, models, and data ensures that benchmarks drive improvements not just in accuracy, but also in efficiency, fairness, and robustness. This holistic perspective will be critical for developing AI that is not only powerful but also practical, scalable, and ethical.
Production Environment Evaluation
The benchmarking methodologies discussed thus far (from micro to end-to-end granularity, from training to inference evaluation) primarily address system performance under controlled conditions. However, the deployment strategies introduced in Chapter 13: ML Operations reveal that production environments introduce distinctly different challenges requiring specialized evaluation approaches. Production machine learning systems must handle dynamic workloads, varying data quality, infrastructure failures, and concurrent user demands while maintaining consistent performance and reliability. This necessitates extending our benchmarking framework beyond single-point performance measurement to evaluate system behavior over time, under stress, and during failure scenarios.
Silent failure detection represents a critical production benchmarking dimension absent from research evaluation frameworks. Machine learning models can degrade silently without obvious error signals, producing plausible but incorrect outputs that escape traditional monitoring. Production benchmarking must establish baseline performance distributions and detect subtle accuracy degradation through statistical process control methods. A/B testing frameworks compare new model versions against stable baselines under identical traffic conditions, measuring not just average performance but performance variance and tail behavior.
Continuous data quality monitoring addresses the dynamic nature of production data streams that can introduce distribution shift, adversarial examples, or corrupted inputs. Production benchmarks must evaluate model robustness under realistic data quality variations including missing features, out-of-range values, and input format changes. Monitoring systems track feature distribution drift over time, measuring statistical distances between training and production data to predict when retraining becomes necessary. Data validation pipelines benchmark preprocessing robustness, ensuring models gracefully handle data quality issues without silent failures.
Load testing and capacity planning evaluate system performance under varying traffic patterns that reflect real user behavior. Production ML systems must handle request spikes, concurrent user sessions, and sustained high-throughput operation while maintaining latency requirements. Benchmarking protocols simulate realistic load patterns including diurnal traffic variations, flash traffic events, and organic growth scenarios. Capacity planning benchmarks measure how performance degrades as system utilization approaches limits, enabling proactive scaling decisions.
Operational resilience benchmarking evaluates system behavior during infrastructure failures, network partitions, and resource constraints. Production systems must maintain service availability during partial failures, gracefully degrade when resources become unavailable, and recover quickly from outages. Chaos engineering approaches systematically introduce failures to measure system resilience: killing inference servers, inducing network latency, and limiting computational resources to observe degradation patterns and recovery characteristics.
Multi-objective optimization in production requires benchmarking frameworks that balance accuracy, latency, cost, and resource utilization simultaneously. Production systems optimize for user experience metrics like conversion rates and engagement alongside traditional ML metrics. Cost efficiency benchmarks evaluate compute cost per prediction, storage costs for model artifacts, and operational overhead for system maintenance. Service level objectives (SLOs) define acceptable performance ranges across multiple dimensions, enabling systematic evaluation of production system health.
Continuous model validation implements automated benchmarking pipelines that evaluate model performance on held-out datasets and synthetic test cases over time. Shadow deployment techniques run new models alongside production systems, comparing outputs without affecting user experience. Champion-challenger frameworks systematically evaluate model improvements through controlled rollouts, measuring both performance improvements and potential negative impacts on downstream systems.
Production benchmarking therefore requires end-to-end evaluation frameworks that extend far beyond model accuracy to encompass system reliability, operational efficiency, and user experience optimization. This comprehensive approach ensures that ML systems deliver consistent value in dynamic production environments while maintaining the robustness necessary for mission-critical applications.
Fallacies and Pitfalls
The benchmarking methodologies and frameworks established throughout this chapter (from our three-dimensional evaluation framework to the specific metrics for training and inference) provide powerful tools for systematic evaluation. However, their effectiveness depends critically on avoiding common misconceptions and methodological errors that can undermine benchmark validity. The standardized nature of benchmarks, while enabling fair comparison, often creates false confidence about their universal applicability.
Fallacy: Benchmark performance directly translates to real-world application performance.
This misconception leads teams to select models and systems based solely on benchmark rankings without considering deployment context differences. Benchmarks typically use curated datasets, standardized evaluation protocols, and optimal configurations that rarely match real-world conditions. Production systems face data quality issues, distribution shifts, latency constraints, and resource limitations not captured in benchmark scenarios. A model that achieves state-of-the-art benchmark performance might fail catastrophically when deployed due to these environmental differences. Effective system selection requires augmenting benchmark results with deployment-specific evaluation rather than relying solely on standardized metrics.
Pitfall: Optimizing exclusively for benchmark metrics without considering broader system requirements.
Many practitioners focus intensively on improving benchmark scores without understanding how these optimizations affect overall system behavior. Techniques that boost specific metrics might degrade other important characteristics like robustness, calibration, fairness, or energy efficiency. Overfitting to benchmark evaluation protocols can create models that perform well on specific test conditions but fail to generalize to varied real-world scenarios. This narrow optimization approach, a manifestation of Goodhart’s Law53 discussed in Section 1.10.4.1, often produces systems that excel in controlled environments but struggle with the complexity and unpredictability of practical deployments.
53 Goodhart’s Law: Originally articulated by British economist Charles Goodhart in 1975, this principle states: “When a measure becomes a target, it ceases to be a good measure.” In ML systems benchmarking, this captures the fundamental tension between using benchmarks as indicators of system quality and the tendency for practitioners to optimize specifically for benchmark scores rather than underlying performance characteristics. As benchmarks become targets for optimization, they progressively lose their value as meaningful proxies for real-world system effectiveness.
Fallacy: Single-metric evaluation provides sufficient insight into system performance.
This belief assumes that one primary metric captures all relevant aspects of system performance. Modern AI systems require evaluation across multiple dimensions including accuracy, latency, throughput, energy consumption, fairness, and robustness. Optimizing for accuracy alone might create systems with unacceptable inference delays, while focusing on throughput might compromise result quality. Different stakeholders prioritize different metrics, and deployment contexts create varying constraints that single metrics cannot capture. Comprehensive evaluation requires multidimensional assessment frameworks that reveal trade-offs across all relevant performance aspects.
Pitfall: Using outdated benchmarks that no longer reflect current challenges and requirements.
Teams often continue using established benchmarks long after they cease to represent meaningful challenges or current deployment realities. As model capabilities advance, benchmarks can become saturated, providing little discriminatory power between approaches. Similarly, changing application requirements, new deployment contexts, and evolving fairness standards can make existing benchmarks irrelevant or misleading. Benchmark datasets may also develop hidden biases or quality issues over time as they age. Effective benchmarking requires regular assessment of whether evaluation frameworks still provide meaningful insights for current challenges and deployment scenarios.
Pitfall: Applying research-oriented benchmarks to evaluate production system performance without accounting for operational constraints.
Many teams use academic benchmarks designed for research comparisons to evaluate production systems, overlooking fundamental differences between research and operational environments. Research benchmarks typically assume unlimited computational resources, optimal data quality, and idealized deployment conditions that rarely exist in production settings. Production systems must handle concurrent user loads, varying input quality, network latency, memory constraints, and system failures that significantly impact performance compared to controlled benchmark conditions. Additionally, production systems require optimization for multiple objectives simultaneously including cost efficiency, availability, and user experience that single-metric research benchmarks cannot capture. Effective production evaluation requires augmenting research benchmarks with operational metrics like sustained throughput under load, recovery time from failures, resource utilization efficiency, and end-to-end latency including data preprocessing and postprocessing overhead.
Summary
This chapter established benchmarking as the critical measurement discipline that validates the performance claims and optimization strategies introduced throughout Parts II and III. By developing a comprehensive three-dimensional framework evaluating algorithms, systems, and data simultaneously, we demonstrated how systematic measurement transforms the theoretical advances in efficient AI design (Chapter 9: Efficient AI), model optimization (Chapter 10: Model Optimizations), and hardware acceleration (Chapter 11: AI Acceleration) into quantifiable engineering improvements. The progression from historical computing benchmarks through specialized ML evaluation methodologies revealed why modern AI systems require multifaceted assessment approaches that capture the complexity of real-world deployment.
The technical sophistication of modern benchmarking frameworks reveals how measurement methodology directly influences innovation direction and resource allocation decisions across the entire AI ecosystem. System benchmarks like MLPerf drive hardware optimization and infrastructure development by establishing standardized workloads and metrics that enable fair comparison across diverse architectures. Model benchmarks push algorithmic innovation by defining challenging tasks and evaluation protocols that reveal limitations and guide research priorities. Data benchmarks expose critical issues around representation, bias, and quality that directly impact model fairness and generalization capabilities. The integration of these benchmarking dimensions creates a comprehensive evaluation framework that captures the complexity of real-world AI deployment challenges.
Key Takeaways
- Effective benchmarking requires multidimensional evaluation across systems, models, and data to capture real-world deployment challenges
- Standardized benchmarks like MLPerf drive hardware innovation and enable fair comparison across diverse architectures and implementations
- Benchmark design choices fundamentally shape research priorities and resource allocation across the entire AI ecosystem
- Future benchmarking must evolve to address emerging challenges around AI safety, fairness, and environmental impact
The benchmarking foundations established here provide the measurement infrastructure necessary for the operational deployment strategies explored in Part IV: Robust Deployment. The transition from performance measurement to production deployment requires extending benchmark validation beyond laboratory conditions. While this chapter focused on systematic evaluation under controlled conditions, Part IV addresses the additional complexities of dynamic workloads, evolving data distributions, and operational constraints that characterize real-world ML system deployment. In Chapter 13: ML Operations, we extend these benchmarking principles to production environments, where continuous monitoring detects silent failures, tracks model performance degradation, and validates system behavior under dynamic workloads that offline benchmarks cannot capture. The A/B testing frameworks and champion-challenger methodologies introduced in production monitoring build directly upon the comparative evaluation principles established through training and inference benchmarking.
The privacy and security challenges in Chapter 15: Security & Privacy similarly require specialized benchmarking methodologies that evaluate dimensions beyond pure performance. Adversarial robustness benchmarks measure model resilience against intentional attacks, while privacy-preserving computation frameworks require benchmarking trade-offs between utility and privacy guarantees. The robustness requirements in Chapter 16: Robust AI demand evaluation protocols that assess model behavior under distribution shift, data corruption, and edge cases that traditional benchmarks overlook.
As AI systems become increasingly influential in critical applications, the benchmarking frameworks developed today determine whether we can effectively measure and optimize for societal impacts extending far beyond traditional performance metrics. The responsible AI principles in Chapter 17: Responsible AI and sustainability considerations in Chapter 18: Sustainable AI establish new evaluation dimensions that must be integrated alongside efficiency and accuracy in comprehensive system assessment.