Robust AI
DALL·E 3 Prompt: Create an image featuring an advanced AI system symbolized by an intricate, glowing neural network, deeply nested within a series of progressively larger and more fortified shields. Each shield layer represents a layer of defense, showcasing the system’s robustness against external threats and internal errors. The neural network, at the heart of this fortress of shields, radiates with connections that signify the AI’s capacity for learning and adaptation. This visual metaphor emphasizes not only the technological sophistication of the AI but also its resilience and security, set against the backdrop of a state-of-the-art, secure server room filled with the latest in technological advancements. The image aims to convey the concept of ultimate protection and resilience in the field of artificial intelligence.

Purpose
How do we develop fault-tolerant and resilient machine learning systems for real-world deployment?
The integration of machine learning systems into real-world applications demands fault-tolerant execution. However, these systems are inherently vulnerable to a spectrum of challenges that can degrade their capabilities. From subtle hardware anomalies to sophisticated adversarial attacks and the unpredictable nature of real-world data, the potential for failure is ever-present. This reality underscores the need to fundamentally rethink how AI systems are designed and deployed, placing robustness and trustworthiness at the forefront. Building resilient machine learning systems is not merely a technical objective; it is a foundational requirement for ensuring their safe and effective operation in dynamic and uncertain environments.
- Identify common hardware faults impacting AI performance.
- Explain how hardware faults (transient and permanent) affect AI systems.
- Define adversarial attacks and their impact on ML models.
- Recognize the vulnerabilities of ML models to data poisoning.
- Explain the challenges posed by distribution shifts in ML models.
- Describe the role of software fault detection and mitigation in AI systems.
- Understand the importance of a holistic software development approach for robust AI.
Overview
As ML systems become increasingly integrated into various domains, ranging from cloud-based services to edge devices and embedded systems, the impact of hardware and software faults on their performance and reliability grows more pronounced. Looking ahead, as these systems become more complex and are deployed in safety-critical applications, the need for robust and fault-tolerant designs becomes paramount.
ML systems are expected to play critical roles in autonomous vehicles, smart cities, healthcare, and industrial automation. In these domains, the consequences of systemic failures, including hardware and software faults, and malicious inputs such as adversarial attacks and data poisoning, and environmental shifts, can be severe, potentially resulting in loss of life, economic disruption, or environmental harm.
To address these risks, researchers and engineers must develop advanced techniques for fault detection, isolation, and recovery, ensuring the reliable operation of future ML systems.
Robust Artificial Intelligence (Robust AI) refers to the ability of AI systems to maintain performance and reliability in the presence of internal and external system errors, and malicious inputs and changes to the data or environment. Robust AI systems are designed to be fault-tolerant and error-resilient, capable of functioning effectively despite variations and errors within the operational environment. Achieving Robust AI involves strategies for fault detection, mitigation, and recovery, as well as prioritizing resilience throughout the AI development lifecycle.
We focus specifically on categories of faults and errors that can impact the robustness of ML systems: errors arising from the underlying system, malicious manipulation, and environmental changes.
Systemic hardware failures present significant challenges across computing systems. Whether transient, permanent, or intermittent, these faults can corrupt computations and degrade system performance. The impact ranges from temporary glitches to complete component failures, requiring robust detection and mitigation strategies to maintain reliable operation.
Malicious manipulation of ML models remains a critical concern as ML systems face various threats to their integrity. Adversarial attacks, data poisoning attempts, and distribution shifts can cause models to misclassify inputs, exhibit distorted behavior patterns, or produce unreliable outputs. These vulnerabilities underscore the importance of developing resilient architectures and defensive mechanisms to protect model performance.
Environmental changes introduce another dimension of potential faults that must be carefully managed. Bugs, design flaws, and implementation errors within algorithms, libraries, and frameworks can propagate through the system, creating systemic vulnerabilities. Rigorous testing, monitoring, and quality control processes help identify and address these software-related issues before they impact production systems.
The specific approaches to achieving robustness vary significantly based on deployment context and system constraints. Large-scale cloud computing environments and data centers typically emphasize fault tolerance through redundancy, distributed processing architectures, and sophisticated error detection mechanisms. In contrast, edge devices and embedded systems must address robustness challenges within strict computational, memory, and energy limitations. This necessitates careful optimization and targeted hardening strategies appropriate for resource-constrained environments.
Regardless of deployment context, the essential characteristics of a robust ML system include fault tolerance, error resilience, and sustained performance. By understanding and addressing these multifaceted challenges, it is possible to develop reliable ML systems capable of operating effectively in real-world environments.
This chapter not only explores the tools, frameworks, and techniques used to detect and mitigate faults, attacks, and distribution shifts, but also emphasizes the importance of prioritizing resilience throughout the AI development lifecycle—from data collection and model training to deployment and monitoring. Proactively addressing robustness challenges is key to unlocking the full potential of ML technologies while ensuring their safe, dependable, and responsible deployment.
Real-World Applications
Understanding the importance of robustness in machine learning systems requires examining how faults manifest in practice. Real-world case studies illustrate the consequences of hardware and software faults across cloud, edge, and embedded environments. These examples highlight the critical need for fault-tolerant design, rigorous testing, and robust system architectures to ensure reliable operation in diverse deployment scenarios.
Cloud
In February 2017, Amazon Web Services (AWS) experienced a significant outage due to human error during routine maintenance. An engineer inadvertently entered an incorrect command, resulting in the shutdown of multiple servers. This outage disrupted many AWS services, including Amazon’s AI-powered assistant, Alexa. As a consequence, Alexa-enabled devices, including Amazon Echo and third-party products that utilize Alexa Voice Service, were unresponsive for several hours. This incident underscores the impact of human error on cloud-based ML systems and the importance of robust maintenance protocols and failsafe mechanisms.
In another case (Vangal et al. 2021), Facebook encountered a silent data corruption (SDC) issue in its distributed querying infrastructure, illustrated in Figure 1. SDC refers to undetected errors during computation or data transfer that propagate silently through system layers. Facebook’s system processed SQL-like queries across datasets and supported a compression application designed to reduce data storage footprints. Files were compressed when not in use and decompressed upon read requests. A size check was performed before decompression to ensure the file was valid. However, an unexpected fault occasionally returned a file size of zero for valid files, leading to decompression failures and missing entries in the output database. The issue appeared sporadically, with some computations returning correct file sizes, making it particularly difficult to diagnose.

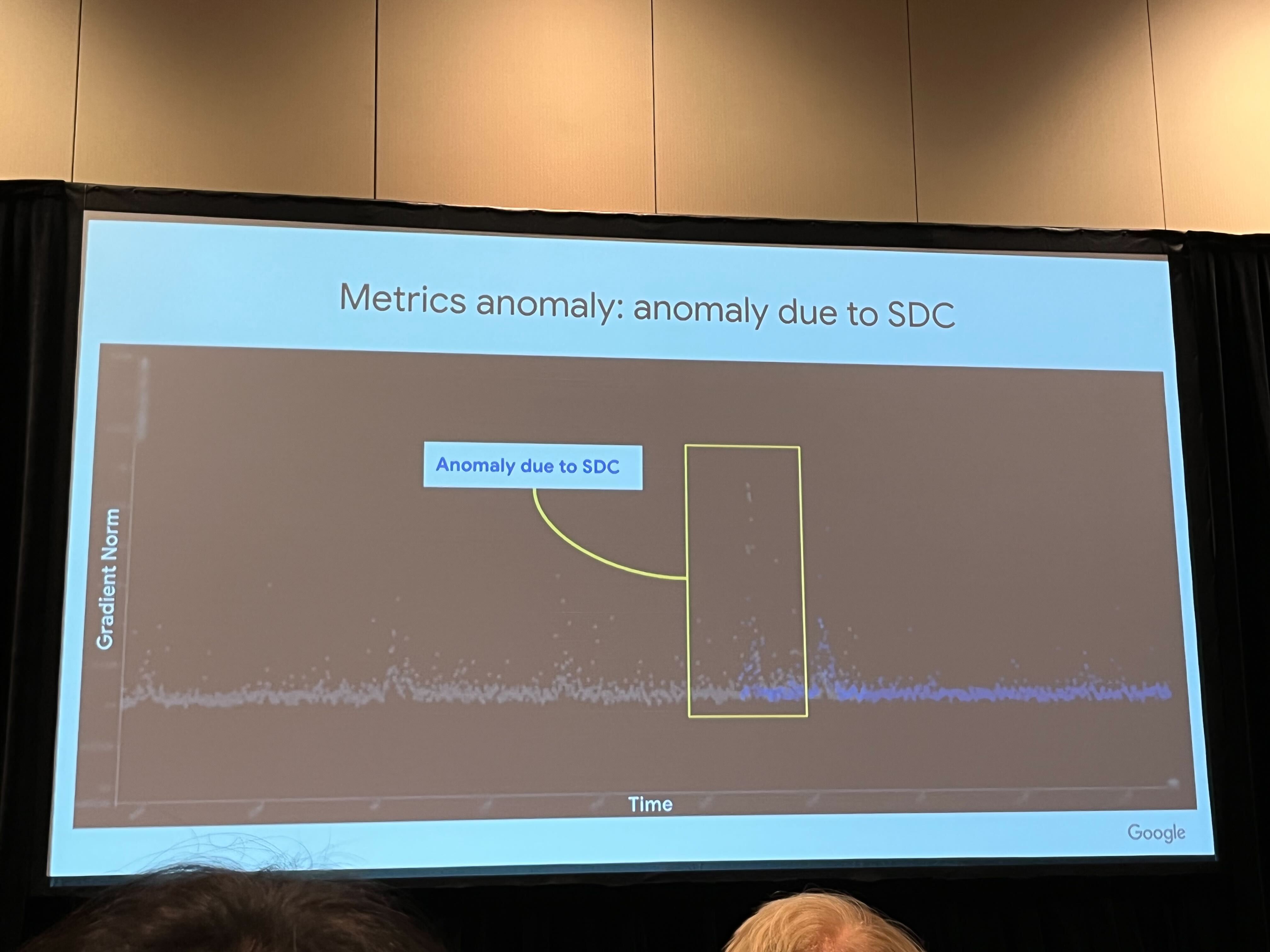
This case illustrates how silent data corruption can propagate across multiple layers of the application stack, resulting in data loss and application failures in large-scale distributed systems. Left unaddressed, such errors can degrade ML system performance. For example, corrupted training data or inconsistencies in data pipelines due to SDC may compromise model accuracy and reliability. Similar challenges have been reported by other major companies. As shown in Figure 2, Jeff Dean, Chief Scientist at Google DeepMind and Google Research, highlighted these issues in AI hypercomputers during a keynote at MLSys 2024.

Edge
In the edge computing domain, self-driving vehicles provide prominent examples of how faults can critically affect ML systems. These vehicles depend on machine learning for perception, decision-making, and control, making them particularly vulnerable to both hardware and software faults.

In May 2016, a fatal crash occurred when a Tesla Model S operating in Autopilot mode1 collided with a white semi-trailer truck. The system, relying on computer vision and ML algorithms, failed to distinguish the trailer against a bright sky, leading to a high-speed impact. The driver, reportedly distracted at the time, did not intervene, as shown in Figure 3. This incident raised serious concerns about the reliability of AI-based perception systems and emphasized the need for robust failsafe mechanisms in autonomous vehicles. A similar case occurred in March 2018, when an Uber self-driving test vehicle struck and killed a pedestrian in Tempe, Arizona. The accident was attributed to a flaw in the vehicle’s object recognition software, which failed to classify the pedestrian as an obstacle requiring avoidance.
1 Autopilot: Tesla’s driver assistance system that provides semi-autonomous capabilities like steering, braking, and acceleration while requiring active driver supervision.
Embedded
Embedded systems operate in resource-constrained and often safety-critical environments. As AI capabilities are increasingly integrated into these systems, the complexity and consequences of faults grow significantly.
One example comes from space exploration. In 1999, NASA’s Mars Polar Lander mission experienced a catastrophic failure due to a software error in its touchdown detection system (Figure 4). The lander’s software misinterpreted the vibrations from the deployment of its landing legs as a successful touchdown, prematurely shutting off its engines and causing a crash. This incident underscores the importance of rigorous software validation and robust system design, particularly for remote missions where recovery is impossible. As AI becomes more integral to space systems, ensuring robustness and reliability will be essential to mission success.

Another example occurred in 2015, when a Boeing 787 Dreamliner experienced a complete electrical shutdown mid-flight due to a software bug in its generator control units. The failure stemmed from a scenario in which powering up all four generator control units simultaneously, following 248 days of uninterrupted operation, caused them to enter failsafe mode, disabling all AC electrical power.
“If the four main generator control units (associated with the engine-mounted generators) were powered up at the same time, after 248 days of continuous power, all four GCUs will go into failsafe mode at the same time, resulting in a loss of all AC electrical power regardless of flight phase.” — Federal Aviation Administration directive (2015)
As AI is increasingly applied in aviation, including tasks such as autonomous flight control and predictive maintenance, the robustness of embedded systems becomes critical for passenger safety.
Finally, consider the case of implantable medical devices. For instance, a smart pacemaker that experiences a fault or unexpected behavior due to software or hardware failure could place a patient’s life at risk. As AI systems take on perception, decision-making, and control roles in such applications, new sources of vulnerability emerge, including data-related errors, model uncertainty2, and unpredictable behaviors in rare edge cases. Moreover, the opaque nature of some AI models complicates fault diagnosis and recovery.
2 Model Uncertainty: The inadequacy of a machine learning model to capture the full complexity of the underlying data-generating process.
Hardware Faults
Hardware faults are a significant challenge in computing systems, including both traditional and ML systems. These faults occur when physical components, including processors, memory modules, storage devices, and interconnects, malfunction or behave abnormally. Hardware faults can cause incorrect computations, data corruption, system crashes, or complete system failure, compromising the integrity and trustworthiness of the computations performed by the system (Jha et al. 2019). A complete system failure refers to a situation where the entire computing system becomes unresponsive or inoperable due to a critical hardware malfunction. This type of failure is the most severe, as it renders the system unusable and may lead to data loss or corruption, requiring manual intervention to repair or replace the faulty components.
ML systems depend on complex hardware architectures and large-scale computations to train and deploy models that learn from data and make intelligent predictions. As a result, hardware faults can disrupt the MLOps pipeline, introducing errors that compromise model accuracy, robustness, and reliability (G. Li et al. 2017). Understanding the types of hardware faults, their mechanisms, and their impact on system behavior is essential for developing strategies to detect, mitigate, and recover from these issues.
The following sections will explore the three main categories of hardware faults: transient, permanent, and intermittent. We will discuss their definitions, characteristics, causes, mechanisms, and examples of how they manifest in computing systems. Detection and mitigation techniques specific to each fault type will also be covered.
Transient Faults: Transient faults are temporary and non-recurring. They are often caused by external factors such as cosmic rays, electromagnetic interference, or power fluctuations. A common example of a transient fault is a bit flip, where a single bit in a memory location or register changes its value unexpectedly. Transient faults can lead to incorrect computations or data corruption, but they do not cause permanent damage to the hardware.
Permanent Faults: Permanent faults, also called hard errors, are irreversible and persist over time. They are typically caused by physical defects or wear-out of hardware components. Examples of permanent faults include stuck-at faults, where a bit or signal is permanently set to a specific value (e.g., always 0 or always 1), and device failures, such as a malfunctioning processor or a damaged memory module. Permanent faults can result in complete system failure or significant performance degradation.
Intermittent Faults: Intermittent faults are recurring faults that appear and disappear intermittently. Unstable hardware conditions, such as loose connections, aging components, or manufacturing defects, often cause them. Intermittent faults can be challenging to diagnose and reproduce because they may occur sporadically and under specific conditions. Examples include intermittent short circuits or contact resistance issues. These faults can lead to unpredictable system behavior and sporadic errors.
Understanding this fault taxonomy and its relevance to both traditional computing and ML systems provides a foundation for making informed decisions when designing, implementing, and deploying fault-tolerant solutions. This knowledge is crucial for improving the reliability and trustworthiness of computing systems and ML applications.
Transient Faults
Transient faults in hardware can manifest in various forms, each with its own unique characteristics and causes. These faults are temporary in nature and do not result in permanent damage to the hardware components.
Characteristics
All transient faults are characterized by their short duration and non-permanent nature. They do not persist or leave any lasting impact on the hardware. However, they can still lead to incorrect computations, data corruption, or system misbehavior if not properly handled. A classic example is shown in Figure 5, where a single bit in memory unexpectedly changes state, potentially altering critical data or computations.
Some of the common types of transient faults include Single Event Upsets (SEUs) caused by ionizing radiation, voltage fluctuations (Reddi and Gupta 2013) due to power supply noise or electromagnetic interference, Electromagnetic Interference (EMI) induced by external electromagnetic fields, Electrostatic Discharge (ESD) resulting from sudden static electricity flow, crosstalk caused by unintended signal coupling, ground bounce triggered by simultaneous switching of multiple outputs, timing violations due to signal timing constraint breaches, and soft errors in combinational logic affecting the output of logic circuits (Mukherjee, Emer, and Reinhardt 2005). Understanding these different types of transient faults is crucial for designing robust and resilient hardware systems that can mitigate their impact and ensure reliable operation.

Causes
External environmental factors represent one of the most significant sources of transient faults. Cosmic rays—high-energy particles originating from outer space—can strike sensitive areas of hardware, such as memory cells or transistors, inducing charge disturbances that alter stored or transmitted data. This is illustrated in Figure 6. Electromagnetic interference (EMI) from nearby devices represents another significant external cause, where electromagnetic fields couple with circuits and cause voltage spikes or glitches that temporarily disrupt normal operation. Electrostatic discharge (ESD) events, resulting from sudden static electricity flow, can also induce transient faults by creating temporary voltage surges that affect sensitive electronic components.
Power and signal integrity issues constitute another major category of transient fault causes. Voltage fluctuations due to power supply noise or instability (Reddi and Gupta 2013) can cause logic circuits to operate outside their specified voltage ranges, leading to incorrect computations. Ground bounce, triggered by simultaneous switching of multiple outputs, creates temporary voltage variations in the ground reference that can affect signal integrity. Crosstalk, caused by unintended signal coupling between adjacent conductors, can induce noise that temporarily corrupts data or control signals.
Finally, timing and logic vulnerabilities create additional pathways for transient faults. Timing violations occur when signals fail to meet setup or hold time requirements due to process variations, temperature changes, or voltage fluctuations. These violations can cause incorrect data capture in sequential elements. Additionally, soft errors in combinational logic can affect circuit outputs even without memory involvement, particularly in deep logic paths where noise margins are reduced (Mukherjee, Emer, and Reinhardt 2005).
Mechanisms
Transient faults can manifest through different mechanisms depending on the affected hardware component. In memory devices like DRAM or SRAM, transient faults often lead to bit flips, where a single bit changes its value from 0 to 1 or vice versa. This can corrupt the stored data or instructions. In logic circuits, transient faults can cause glitches3 or voltage spikes propagating through the combinational logic4, resulting in incorrect outputs or control signals. Transient faults can also affect communication channels, causing bit errors or packet losses during data transmission.
3 Glitches: Momentary deviation in voltage, current, or signal, often causing incorrect operation.
4 Combinational logic: Digital logic, wherein the output depends only on the current input states, not any past states.
Impact on ML
A common example of a transient fault is a bit flip in the main memory. If an important data structure or critical instruction is stored in the affected memory location, it can lead to incorrect computations or program misbehavior. For instance, a bit flip in the memory storing a loop counter can cause the loop to execute indefinitely or terminate prematurely. Transient faults in control registers or flag bits can alter the flow of program execution, leading to unexpected jumps or incorrect branch decisions. In communication systems, transient faults can corrupt transmitted data packets, resulting in retransmissions or data loss.
In ML systems, transient faults can have significant implications during the training phase (He et al. 2023). ML training involves iterative computations and updates to model parameters based on large datasets. If a transient fault occurs in the memory storing the model weights or gradients, it can lead to incorrect updates and compromise the convergence and accuracy of the training process. For example, a bit flip in the weight matrix of a neural network can cause the model to learn incorrect patterns or associations, leading to degraded performance (Wan et al. 2021). Transient faults in the data pipeline, such as corruption of training samples or labels, can also introduce noise and affect the quality of the learned model.
As shown in Figure 7, a real-world example from Google’s production fleet highlights how an SDC anomaly caused a significant deviation in the gradient norm—a measure of the magnitude of updates to the model parameters. Such deviations can disrupt the optimization process, leading to slower convergence or failure to reach an optimal solution.
During the inference phase, transient faults can impact the reliability and trustworthiness of ML predictions. If a transient fault occurs in the memory storing the trained model parameters or during the computation of inference results, it can lead to incorrect or inconsistent predictions. For instance, a bit flip in the activation values of a neural network can alter the final classification or regression output (Mahmoud et al. 2020). In safety-critical applications, such as autonomous vehicles or medical diagnosis, these faults can have severe consequences, resulting in incorrect decisions or actions that may compromise safety or lead to system failures (G. Li et al. 2017; Jha et al. 2019).
5 Stochastic Computing: A collection of techniques using random bits and logic operations to perform arithmetic and data processing, promising better fault tolerance.
Transient faults can be amplified in resource-constrained environments like TinyML, where limited computational and memory resources exacerbate their impact. One prominent example is Binarized Neural Networks (BNNs) (Courbariaux et al. 2016), which represent network weights in single-bit precision to achieve computational efficiency and faster inference times. While this binary representation is advantageous for resource-constrained systems, it also makes BNNs particularly fragile to bit-flip errors. For instance, prior work (Aygun, Gunes, and De Vleeschouwer 2021) has shown that a two-hidden-layer BNN architecture for a simple task such as MNIST classification suffers performance degradation from 98% test accuracy to 70% when random bit-flipping soft errors are inserted through model weights with a 10% probability. To address these vulnerabilities, techniques like flip-aware training and emerging approaches such as stochastic computing5 are being explored to enhance fault tolerance.
Permanent Faults
Permanent faults are hardware defects that persist and cause irreversible damage to the affected components. These faults are characterized by their persistent nature and require repair or replacement of the faulty hardware to restore normal system functionality.
Characteristics
Permanent faults cause persistent and irreversible malfunctions in hardware components. The faulty component remains non-operational until it is repaired or replaced. These faults are consistent and reproducible, meaning the faulty behavior is observed every time the affected component is used. They can impact processors, memory modules, storage devices, or interconnects—potentially leading to system crashes, data corruption, or complete system failure.
One notable example of a permanent fault is the Intel FDIV bug, discovered in 1994. This flaw affected the floating-point division (FDIV) units of certain Intel Pentium processors, causing incorrect results for specific division operations and leading to inaccurate calculations.
The FDIV bug occurred due to an error in the lookup table6 used by the division unit. In rare cases, the processor would fetch an incorrect value, resulting in a slightly less precise result than expected. For instance, Figure 8 shows a fraction 4195835/3145727 plotted on a Pentium processor with the FDIV fault. The triangular regions highlight where erroneous calculations occurred. Ideally, all correct values would round to 1.3338, but the faulty results showed 1.3337, indicating a mistake in the 5th digit.
6 Lookup Table: A data structure used to replace a runtime computation with a simpler array indexing operation.
Although the error was small, it could compound across many operations, significantly affecting results in precision-critical applications such as scientific simulations, financial calculations, and computer-aided design. The bug ultimately led to incorrect outcomes in these domains and underscored the severe consequences permanent faults can have.

The FDIV bug serves as a cautionary tale for ML systems. In such systems, permanent faults in hardware components can result in incorrect computations, impacting model accuracy and reliability. For example, if an ML system relies on a processor with a faulty floating-point unit, similar to the FDIV bug, it could introduce persistent errors during training or inference. These errors may propagate through the model, leading to inaccurate predictions or skewed learning outcomes.
This is especially critical in safety-sensitive applications like autonomous driving, medical diagnosis, or financial forecasting, where the consequences of incorrect computations can be severe. ML practitioners must be aware of these risks and incorporate fault-tolerant techniques, including hardware redundancy, error detection and correction, and robust algorithm design, to mitigate them. Additionally, thorough hardware validation and testing can help identify and resolve permanent faults before they affect system performance and reliability.
Causes
Permanent faults can arise from two primary sources: manufacturing defects and wear-out mechanisms. Manufacturing defects are flaws introduced during the fabrication process, including improper etching, incorrect doping, or contamination. These defects may result in non-functional or partially functional components. In contrast, wear-out mechanisms occur over time due to prolonged use and operational stress. Phenomena like electromigration7, oxide breakdown8, and thermal stress9 degrade component integrity, eventually leading to permanent failure.
7 The movement of metal atoms in a conductor under the influence of an electric field.
8 The failure of an oxide layer in a transistor due to excessive electric field stress.
9 Degradation caused by repeated cycling through high and low temperatures.
Mechanisms
Permanent faults manifest through several mechanisms, depending on their nature and location. A common example is the stuck-at fault (Seong et al. 2010), where a signal or memory cell becomes permanently fixed at either 0 or 1, regardless of the intended input, as shown in Figure 9. This type of fault can occur in logic gates, memory cells, or interconnects and typically results in incorrect computations or persistent data corruption.

Other mechanisms include device failures, in which hardware components such as transistors or memory cells cease functioning entirely due to manufacturing defects or degradation over time. Bridging faults, which occur when two or more signal lines are unintentionally connected, can introduce short circuits or incorrect logic behaviors that are difficult to isolate.
In more subtle cases, delay faults can arise when the propagation time of a signal exceeds the allowed timing constraints. Although the logical values may be correct, the violation of timing expectations can still result in erroneous behavior. Similarly, interconnect faults, including open circuits caused by broken connections, high-resistance paths that impede current flow, and increased capacitance that distorts signal transitions, can significantly degrade circuit performance and reliability.
Memory subsystems are particularly vulnerable to permanent faults. Transition faults can prevent a memory cell from successfully changing its state, while coupling faults result from unwanted interference between adjacent cells, leading to unintentional state changes. Additionally, neighborhood pattern sensitive faults occur when the state of a memory cell is incorrectly influenced by the data stored in nearby cells, reflecting a more complex interaction between circuit layout and logic behavior.
Finally, permanent faults can also occur in critical infrastructure components such as the power supply network or clock distribution system. Failures in these subsystems can affect circuit-wide functionality, introduce timing errors, or cause widespread operational instability.
Taken together, these mechanisms illustrate the varied and often complex ways in which permanent faults can undermine the behavior of computing systems. For ML applications in particular, where correctness and consistency are vital, understanding these fault modes is essential for developing resilient hardware and software solutions.
Impact on ML
Permanent faults can severely disrupt the behavior and reliability of computing systems. For example, a stuck-at fault in a processor’s arithmetic logic unit (ALU) can produce persistent computational errors, leading to incorrect program behavior or crashes. In memory modules, such faults may corrupt stored data, while in storage devices, they can result in bad sectors or total data loss. Interconnect faults may interfere with data transmission, leading to system hangs or corruption.
For ML systems, these faults pose significant risks in both the training and inference phases. During training, permanent faults in processors or memory can lead to incorrect gradient calculations, corrupt model parameters, or prematurely halted training processes (He et al. 2023). Similarly, faults in storage can compromise training datasets or saved models, affecting consistency and reliability.
In the inference phase, faults can distort prediction results or lead to runtime failures. For instance, errors in the hardware storing model weights might lead to outdated or corrupted models being used, while processor faults could yield incorrect outputs (Zhang, Gu, et al. 2018).
To mitigate these impacts, ML systems must incorporate both hardware and software fault-tolerant techniques. Hardware-level methods include component redundancy and error-correcting codes (Kim, Sullivan, and Erez 2015).10 Software approaches, like checkpoint and restart mechanisms11 (Egwutuoha et al. 2013), allow systems to recover to a known-good state after a failure. Regular monitoring, testing, and maintenance can also help detect and replace failing components before critical errors occur.
10 Error-Correcting Codes: Methods used in data storage and transmission to detect and correct errors.
11 Checkpoint and Restart Mechanisms: Techniques that periodically save a program’s state so it can resume from the last saved state after a failure.
Ultimately, designing ML systems with built-in fault tolerance is essential to ensure resilience. Incorporating redundancy, error-checking, and fail-safe mechanisms helps preserve model integrity, accuracy, and trustworthiness—even in the face of permanent hardware faults.
Intermittent Faults
Intermittent faults are hardware faults that occur sporadically and unpredictably in a system. An example is illustrated in Figure 10, where cracks in the material can introduce increased resistance in circuitry. These faults are particularly challenging to detect and diagnose because they appear and disappear intermittently, making it difficult to reproduce and isolate the root cause. Depending on their frequency and location, intermittent faults can lead to system instability, data corruption, and performance degradation.

Characteristics
Intermittent faults are defined by their sporadic and non-deterministic behavior. They occur irregularly and may manifest for short durations, disappearing without a consistent pattern. Unlike permanent faults, they do not appear every time the affected component is used, which makes them particularly difficult to detect and reproduce. These faults can affect a variety of hardware components, including processors, memory modules, storage devices, and interconnects. As a result, they may lead to transient errors, unpredictable system behavior, or data corruption.
Their impact on system reliability can be significant. For instance, an intermittent fault in a processor’s control logic may disrupt the normal execution path, causing irregular program flow or unexpected system hangs. In memory modules, such faults can alter stored values inconsistently, leading to errors that are difficult to trace. Storage devices affected by intermittent faults may suffer from sporadic read/write errors or data loss, while intermittent faults in communication channels can cause data corruption, packet loss, or unstable connectivity. Over time, these failures can accumulate, degrading system performance and reliability (Rashid, Pattabiraman, and Gopalakrishnan 2015).
Causes
The causes of intermittent faults are diverse, ranging from physical degradation to environmental influences. One common cause is the aging and wear-out of electronic components. As hardware endures prolonged operation, thermal cycling, and mechanical stress, it may develop cracks, fractures, or fatigue that introduce intermittent faults. For instance, solder joints in ball grid arrays (BGAs) or flip-chip packages can degrade over time, leading to intermittent open circuits or short circuits.
Manufacturing defects and process variations can also introduce marginal components that behave reliably under most circumstances but fail intermittently under stress or extreme conditions. For example, Figure 11 shows a residue-induced intermittent fault in a DRAM chip that leads to sporadic failures.

Environmental factors such as thermal cycling, humidity, mechanical vibrations, or electrostatic discharge can exacerbate these weaknesses and trigger faults that would not otherwise appear. Loose or degrading physical connections, including those found in connectors or printed circuit boards, are also common sources of intermittent failures, particularly in systems exposed to movement or temperature variation.
Mechanisms
Intermittent faults can manifest through various physical and logical mechanisms depending on their root causes. One such mechanism is the intermittent open or short circuit, where physical discontinuities or partial connections cause signal paths to behave unpredictably. These faults may momentarily disrupt signal integrity, leading to glitches or unexpected logic transitions.
Another common mechanism is the intermittent delay fault (Zhang, Rangineni, et al. 2018), where signal propagation times fluctuate due to marginal timing conditions, resulting in synchronization issues and incorrect computations. In memory cells or registers, intermittent faults can appear as transient bit flips or soft errors, corrupting data in ways that are difficult to detect or reproduce. Because these faults are often condition-dependent, they may only emerge under specific thermal, voltage, or workload conditions, adding further complexity to their diagnosis.
Impact on ML
Intermittent faults pose significant challenges for ML systems by undermining computational consistency and model reliability. During the training phase, such faults in processing units or memory can cause sporadic errors in the computation of gradients, weight updates, or loss values. These errors may not be persistent but can accumulate across iterations, degrading convergence and leading to unstable or suboptimal models. Intermittent faults in storage may corrupt input data or saved model checkpoints, further affecting the training pipeline (He et al. 2023).
In the inference phase, intermittent faults may result in inconsistent or erroneous predictions. Processing errors or memory corruption can distort activations, outputs, or intermediate representations of the model, particularly when faults affect model parameters or input data. Intermittent faults in data pipelines, such as unreliable sensors or storage systems, can introduce subtle input errors that degrade model robustness and output accuracy. In high-stakes applications like autonomous driving or medical diagnosis, these inconsistencies can result in dangerous decisions or failed operations.
Mitigating the effects of intermittent faults in ML systems requires a multi-layered approach (Rashid, Pattabiraman, and Gopalakrishnan 2012). At the hardware level, robust design practices, environmental controls, and the use of higher-quality or more reliable components can reduce susceptibility to fault conditions. Redundancy and error detection mechanisms can help identify and recover from transient manifestations of intermittent faults.
At the software level, techniques such as runtime monitoring, anomaly detection, and adaptive control strategies can provide resilience. Data validation checks, outlier detection, model ensembling, and runtime model adaptation are examples of fault-tolerant methods that can be integrated into ML pipelines to improve reliability in the presence of sporadic errors.
Ultimately, designing ML systems that can gracefully handle intermittent faults is essential to maintaining their accuracy, consistency, and dependability. This involves proactive fault detection, regular system monitoring, and ongoing maintenance to ensure early identification and remediation of issues. By embedding resilience into both the architecture and operational workflow, ML systems can remain robust even in environments prone to sporadic hardware failures.
Detection and Mitigation
Various fault detection techniques, including hardware-level and software-level approaches, and effective mitigation strategies can enhance the resilience of ML systems. Additionally, resilient ML system design considerations, case studies and examples, and future research directions in fault-tolerant ML systems provide insights into building robust systems.
Detection Techniques
Fault detection techniques are important for identifying and localizing hardware faults in ML systems. These techniques can be broadly categorized into hardware-level and software-level approaches, each offering unique capabilities and advantages.
Hardware-Level Detection
Hardware-level fault detection techniques are implemented at the physical level of the system and aim to identify faults in the underlying hardware components. There are several hardware techniques, but broadly, we can bucket these different mechanisms into the following categories.
Built-in self-test (BIST) Mechanisms
BIST is a powerful technique for detecting faults in hardware components (Bushnell and Agrawal 2002). It involves incorporating additional hardware circuitry into the system for self-testing and fault detection. BIST can be applied to various components, such as processors, memory modules, or application-specific integrated circuits (ASICs). For example, BIST can be implemented in a processor using scan chains12, which are dedicated paths that allow access to internal registers and logic for testing purposes.
12 Scan Chains: Dedicated paths incorporated within a processor that grant access to internal registers and logic for testing.
During the BIST process, predefined test patterns are applied to the processor’s internal circuitry, and the responses are compared against expected values. Any discrepancies indicate the presence of faults. Intel’s Xeon processors, for instance, include BIST mechanisms to test the CPU cores, cache memory, and other critical components during system startup.

Error Detection Codes
Error detection codes are widely used to detect data storage and transmission errors (Hamming 1950)13. These codes add redundant bits to the original data, allowing the detection of bit errors. Example: Parity checks are a simple form of error detection code shown in Figure 1214. In a single-bit parity scheme, an extra bit is appended to each data word, making the number of 1s in the word even (even parity) or odd (odd parity).
13 R. W. Hamming’s seminal paper introduced error detection and correction codes, significantly advancing digital communication reliability.
14 In parity checks, an extra bit accounts for the total number of 1s in a data word, enabling fundamental error detection.
When reading the data, the parity is checked, and if it doesn’t match the expected value, an error is detected. More advanced error detection codes, such as cyclic redundancy checks (CRC), calculate a checksum based on the data and append it to the message. The checksum is recalculated at the receiving end and compared with the transmitted checksum to detect errors. Error-correcting code (ECC) memory modules, commonly used in servers and critical systems, employ advanced error detection and correction codes to detect and correct single-bit or multi-bit errors in memory.
Hardware redundancy and voting mechanisms
Hardware redundancy involves duplicating critical components and comparing their outputs to detect and mask faults (Sheaffer, Luebke, and Skadron 2007). Voting mechanisms, such as double modular redundancy (DMR)15 or triple modular redundancy (TMR)16, employ multiple instances of a component and compare their outputs to identify and mask faulty behavior (Arifeen, Hassan, and Lee 2020).
15 Double Modular Redundancy (DMR): A fault-tolerance process in which computations are duplicated to identify and correct errors.
16 Triple Modular Redundancy (TMR): A fault-tolerance process where three instances of a computation are performed to identify and correct errors.
In a DMR or TMR system, two or three identical instances of a hardware component, such as a processor or a sensor, perform the same computation in parallel. The outputs of these instances are fed into a voting circuit, which compares the results and selects the majority value as the final output. If one of the instances produces an incorrect result due to a fault, the voting mechanism masks the error and maintains the correct output. TMR is commonly used in aerospace and aviation systems, where high reliability is critical. For instance, the Boeing 777 aircraft employs TMR in its primary flight computer system to ensure the availability and correctness of flight control functions (Yeh 1996).
Tesla’s self-driving computers, on the other hand, employ a DMR architecture to ensure the safety and reliability of critical functions such as perception, decision-making, and vehicle control, as shown in Figure 13. In Tesla’s implementation, two identical hardware units, often called “redundant computers” or “redundant control units,” perform the same computations in parallel. Each unit independently processes sensor data, executes algorithms, and generates control commands for the vehicle’s actuators, such as steering, acceleration, and braking (Bannon et al. 2019).

The outputs of these two redundant units are continuously compared to detect any discrepancies or faults. If the outputs match, the system assumes that both units function correctly, and the control commands are sent to the vehicle’s actuators. However, if there is a mismatch between the outputs, the system identifies a potential fault in one of the units and takes appropriate action to ensure safe operation.
DMR in Tesla’s self-driving computer provides an extra safety and fault tolerance layer. By having two independent units performing the same computations, the system can detect and mitigate faults that may occur in one of the units. This redundancy helps prevent single points of failure and ensures that critical functions remain operational despite hardware faults.
The system may employ additional mechanisms to determine which unit is faulty in a mismatch. This can involve using diagnostic algorithms, comparing the outputs with data from other sensors or subsystems, or analyzing the consistency of the outputs over time. Once the faulty unit is identified, the system can isolate it and continue operating using the output from the non-faulty unit.
Tesla also incorporates redundancy mechanisms beyond DMR. For example, they use redundant power supplies, steering and braking systems, and diverse sensor suites (e.g., cameras, radar, and ultrasonic sensors) to provide multiple layers of fault tolerance. These redundancies collectively contribute to the overall safety and reliability of the self-driving system.
It’s important to note that while DMR provides fault detection and some level of fault tolerance, TMR may provide a different level of fault masking. In DMR, if both units experience simultaneous faults or the fault affects the comparison mechanism, the system may be unable to identify the fault. Therefore, Tesla’s SDCs rely on a combination of DMR and other redundancy mechanisms to achieve a high level of fault tolerance.
The use of DMR in Tesla’s self-driving computer highlights the importance of hardware redundancy in safety-critical applications. By employing redundant computing units and comparing their outputs, the system can detect and mitigate faults, enhancing the overall safety and reliability of the self-driving functionality.
Another approach to hardware redundancy is the use of hot spares17, as employed by Google in its data centers to address SDC during ML training. Unlike DMR and TMR, which rely on parallel processing and voting mechanisms to detect and mask faults, hot spares provide fault tolerance by maintaining backup hardware units that can seamlessly take over computations when a fault is detected. As illustrated in Figure 14, during normal ML training, multiple synchronous training workers process data in parallel. However, if a worker becomes defective and causes SDC, an SDC checker automatically identifies the issues. Upon detecting the SDC, the SDC checker moves the training to a hot spare and sends the defective machine for repair. This redundancy safeguards the continuity and reliability of ML training, effectively minimizing downtime and preserving data integrity.
17 Hot Spares: In a system redundancy design, these are the backup components kept ready to instantaneously replace failing components without disrupting the operation.

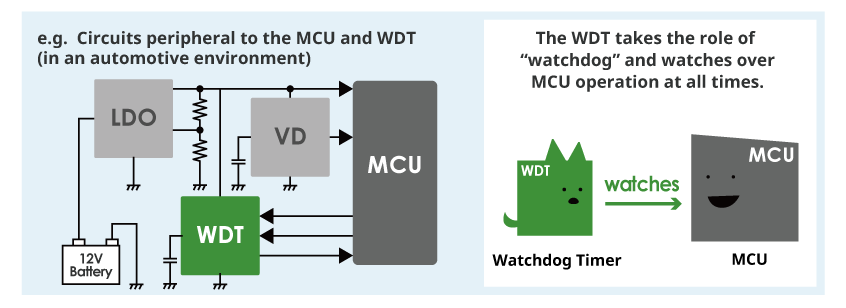
Watchdog timers
Watchdog timers are hardware components that monitor the execution of critical tasks or processes (Pont and Ong 2002). They are commonly used to detect and recover from software or hardware faults that cause a system to become unresponsive or stuck in an infinite loop. In an embedded system, a watchdog timer can be configured to monitor the execution of the main control loop, as illustrated in Figure 15. The software periodically resets the watchdog timer to indicate that it functions correctly. Suppose the software fails to reset the timer within a specified time limit (timeout period). In that case, the watchdog timer assumes that the system has encountered a fault and triggers a predefined recovery action, such as resetting the system or switching to a backup component. Watchdog timers are widely used in automotive electronics, industrial control systems, and other safety-critical applications to ensure the timely detection and recovery from faults.
Software-Level Detection
Software-level fault detection techniques rely on software algorithms and monitoring mechanisms to identify system faults. These techniques can be implemented at various levels of the software stack, including the operating system, middleware, or application level.
Runtime monitoring and anomaly detection
Runtime monitoring involves continuously observing the behavior of the system and its components during execution (Francalanza et al. 2017). It helps detect anomalies, errors, or unexpected behavior that may indicate the presence of faults. For example, consider an ML-based image classification system deployed in a self-driving car. Runtime monitoring can be implemented to track the classification model’s performance and behavior (Mahmoud et al. 2021).
Anomaly detection algorithms can be applied to the model’s predictions or intermediate layer activations, such as statistical outlier detection or machine learning-based approaches (e.g., One-Class SVM or Autoencoders) (Chandola, Banerjee, and Kumar 2009). Figure 16 shows example of anomaly detection. Suppose the monitoring system detects a significant deviation from the expected patterns, such as a sudden drop in classification accuracy or out-of-distribution samples. In that case, it can raise an alert indicating a potential fault in the model or the input data pipeline. This early detection allows for timely intervention and fault mitigation strategies to be applied.

Consistency checks and data validation
Consistency checks and data validation techniques ensure data integrity and correctness at different processing stages in an ML system (Lindholm et al. 2019). These checks help detect data corruption, inconsistencies, or errors that may propagate and affect the system’s behavior. Example: In a distributed ML system where multiple nodes collaborate to train a model, consistency checks can be implemented to validate the integrity of the shared model parameters. Each node can compute a checksum or hash of the model parameters before and after the training iteration, as shown in Figure 16. Any inconsistencies or data corruption can be detected by comparing the checksums across nodes. Additionally, range checks can be applied to the input data and model outputs to ensure they fall within expected bounds. For instance, if an autonomous vehicle’s perception system detects an object with unrealistic dimensions or velocities, it can indicate a fault in the sensor data or the perception algorithms (Wan et al. 2023).
Heartbeat and timeout mechanisms
Heartbeat mechanisms and timeouts are commonly used to detect faults in distributed systems and ensure the liveness and responsiveness of components (Kawazoe Aguilera, Chen, and Toueg 1997). These are quite similar to the watchdog timers found in hardware. For example, in a distributed ML system, where multiple nodes collaborate to perform tasks such as data preprocessing, model training, or inference, heartbeat mechanisms can be implemented to monitor the health and availability of each node. Each node periodically sends a heartbeat message to a central coordinator or its peer nodes, indicating its status and availability. Suppose a node fails to send a heartbeat within a specified timeout period, as shown in Figure 17. In that case, it is considered faulty, and appropriate actions can be taken, such as redistributing the workload or initiating a failover mechanism. Timeouts can also be used to detect and handle hanging or unresponsive components. For example, if a data loading process exceeds a predefined timeout threshold, it may indicate a fault in the data pipeline, and the system can take corrective measures.

Software-implemented fault tolerance (SIFT) techniques
SIFT techniques introduce redundancy and fault detection mechanisms at the software level to improve the reliability and fault tolerance of the system (Reis et al. 2005). Example: N-version programming is a SIFT technique where multiple functionally equivalent software component versions are developed independently by different teams. This can be applied to critical components such as the model inference engine in an ML system. Multiple versions of the inference engine can be executed in parallel, and their outputs can be compared for consistency. It is considered the correct result if most versions produce the same output. If there is a discrepancy, it indicates a potential fault in one or more versions, and appropriate error-handling mechanisms can be triggered. Another example is using software-based error correction codes, such as Reed-Solomon codes (Plank 1997), to detect and correct errors in data storage or transmission, as shown in Figure 18. These codes add redundancy to the data, enabling detecting and correcting certain errors and enhancing the system’s fault tolerance.

Summary
Table 1 provides a comparative analysis of transient, permanent, and intermittent faults. It outlines the primary characteristics or dimensions that distinguish these fault types. Here, we summarize the relevant dimensions we examined and explore the nuances that differentiate transient, permanent, and intermittent faults in greater detail.
| Dimension | Transient Faults | Permanent Faults | Intermittent Faults |
|---|---|---|---|
| Duration | Short-lived, temporary | Persistent, remains until repair or replacement | Sporadic, appears and disappears intermittently |
| Persistence | Disappears after the fault condition passes | Consistently present until addressed | Recurs irregularly, not always present |
| Causes | External factors (e.g., electromagnetic interference cosmic rays) | Hardware defects, physical damage, wear-out | Unstable hardware conditions, loose connections, aging components |
| Manifestation | Bit flips, glitches, temporary data corruption | Stuck-at faults, broken components, complete device failures | Occasional bit flips, intermittent signal issues, sporadic malfunctions |
| Impact on ML Systems | Introduces temporary errors or noise in computations | Causes consistent errors or failures, affecting reliability | Leads to sporadic and unpredictable errors, challenging to diagnose and mitigate |
| Detection | Error detection codes, comparison with expected values | Built-in self-tests, error detection codes, consistency checks | Monitoring for anomalies, analyzing error patterns and correlations |
| Mitigation | Error correction codes, redundancy, checkpoint and restart | Hardware repair or replacement, component redundancy, failover mechanisms | Robust design, environmental control, runtime monitoring, fault-tolerant techniques |
Model Robustness
Adversarial Attacks
We first introduced adversarial attacks when discussing how slight changes to input data can trick a model into making incorrect predictions. These attacks often involve adding small, carefully designed perturbations to input data, which can cause the model to misclassify it, as shown in Figure 19. In this section, we will look at the different types of adversarial attacks and their impact on machine learning models. Understanding these attacks highlights why it is important to build models that are robust and able to handle these kinds of challenges.
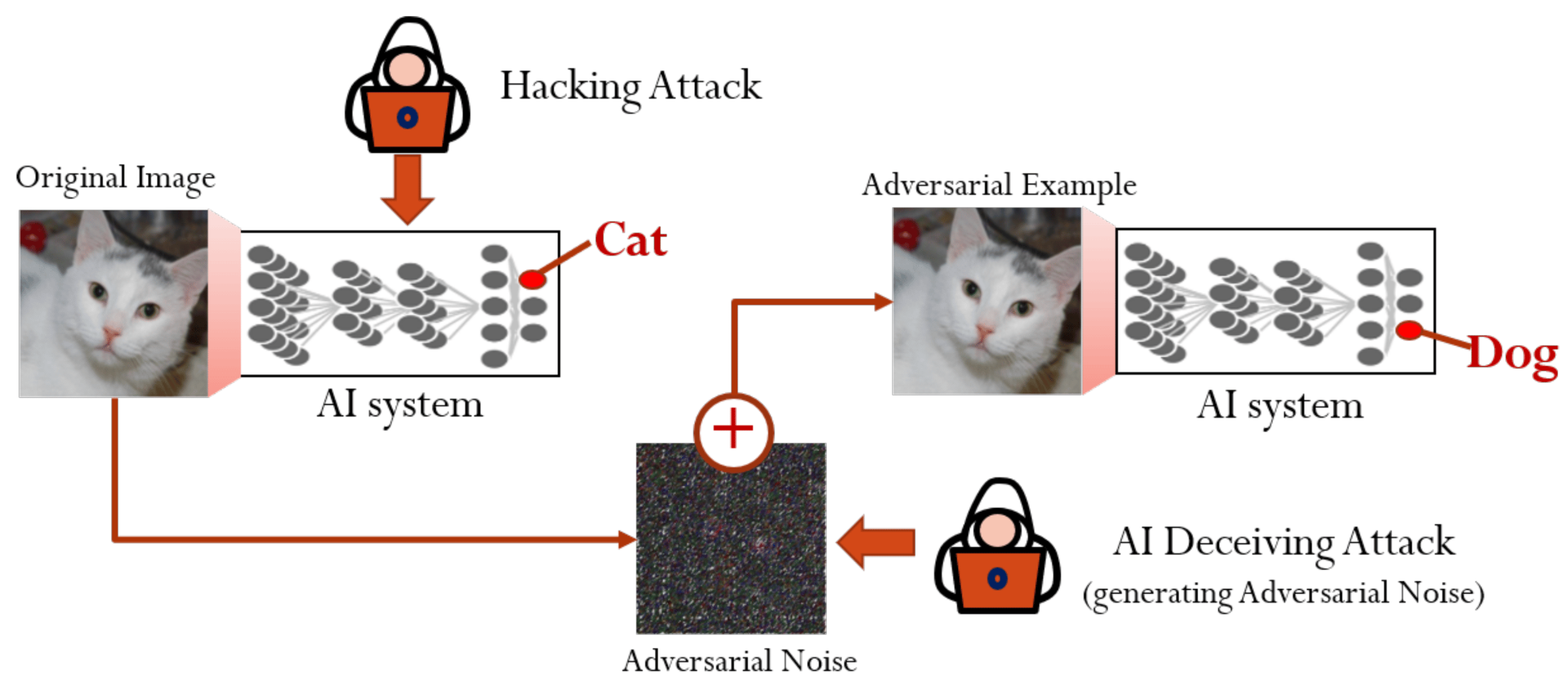
Mechanisms
Gradient-based Attacks
One prominent category of adversarial attacks is gradient-based attacks. These attacks leverage the gradients of the ML model’s loss function to craft adversarial examples. The Fast Gradient Sign Method (FGSM) is a well-known technique in this category. FGSM perturbs the input data by adding small noise in the direction of the gradient of the loss with respect to the input. The goal is to maximize the model’s prediction error with minimal distortion to the original input.
The adversarial example is generated using the following formula: \[ x_{\text{adv}} = x + \epsilon \cdot \text{sign}\big(\nabla_x J(\theta, x, y)\big) \] Where:
- \(x\) is the original input,
- \(y\) is the true label,
- \(\theta\) represents the model parameters,
- \(J(\theta, x, y)\) is the loss function,
- \(\epsilon\) is a small scalar that controls the magnitude of the perturbation.
This method allows for fast and efficient generation of adversarial examples by taking a single step in the direction that increases the loss most rapidly, as shown in Figure 20.
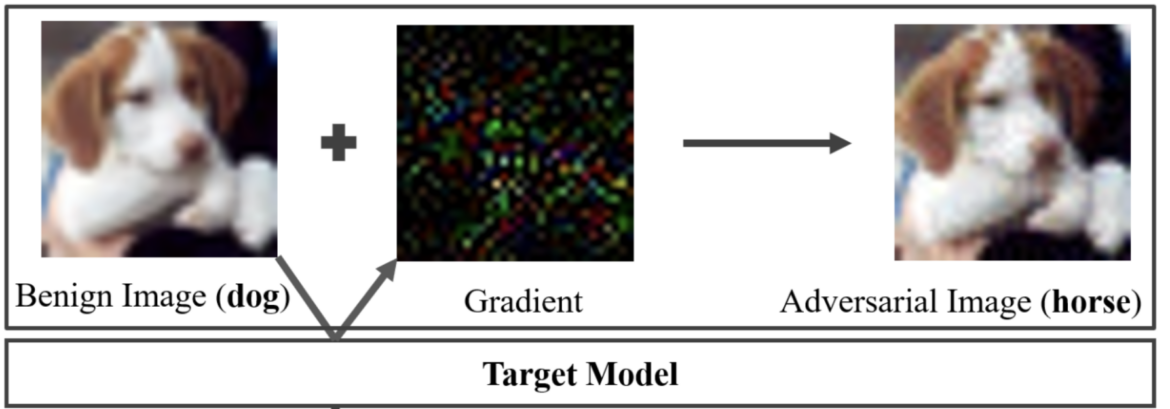
Another variant, the Projected Gradient Descent (PGD) attack, extends FGSM by iteratively applying the gradient update step, allowing for more refined and powerful adversarial examples. PGD projects each perturbation step back into a constrained norm ball around the original input, ensuring that the adversarial example remains within a specified distortion limit. This makes PGD a stronger white-box attack and a benchmark for evaluating model robustness.
The Jacobian-based Saliency Map Attack (JSMA) is another gradient-based approach that identifies the most influential input features and perturbs them to create adversarial examples. By constructing a saliency map based on the Jacobian of the model’s outputs with respect to inputs, JSMA selectively alters a small number of input dimensions that are most likely to influence the target class. This makes JSMA more precise and targeted than FGSM or PGD, often requiring fewer perturbations to fool the model.
Gradient-based attacks are particularly effective in white-box settings, where the attacker has access to the model’s architecture and gradients. Their efficiency and relative simplicity have made them popular tools for both attacking and evaluating model robustness in research.
Optimization-based Attacks
These attacks formulate the generation of adversarial examples as an optimization problem. The Carlini and Wagner (C&W) attack is a prominent example in this category. It finds the smallest perturbation that can cause misclassification while maintaining the perceptual similarity to the original input. The C&W attack employs an iterative optimization process to minimize the perturbation while maximizing the model’s prediction error. It uses a customized loss function with a confidence term to generate more confident misclassifications.
C&W attacks are especially difficult to detect because the perturbations are typically imperceptible to humans, and they often bypass many existing defenses. The attack can be formulated under various norm constraints (e.g., L2, L∞) depending on the desired properties of the adversarial perturbation.
Another optimization-based approach is the Elastic Net Attack to DNNs (EAD), which incorporates elastic net regularization (a combination of L1 and L2 penalties) to generate adversarial examples with sparse perturbations. This can lead to minimal and localized changes in the input, which are harder to identify and filter. EAD is particularly useful in settings where perturbations need to be constrained in both magnitude and spatial extent.
These attacks are more computationally intensive than gradient-based methods but offer finer control over the adversarial example’s properties. They are often used in high-stakes domains where stealth and precision are critical.
Transfer-based Attacks
Transfer-based attacks exploit the transferability property of adversarial examples. Transferability refers to the phenomenon where adversarial examples crafted for one ML model can often fool other models, even if they have different architectures or were trained on different datasets. This enables attackers to generate adversarial examples using a surrogate model and then transfer them to the target model without requiring direct access to its parameters or gradients.
This property underlies the feasibility of black-box attacks, where the adversary cannot query gradients but can still fool a model by crafting attacks on a publicly available or similar substitute model. Transfer-based attacks are particularly relevant in practical threat scenarios, such as attacking commercial ML APIs, where the attacker can observe inputs and outputs but not internal computations.
Attack success often depends on factors like similarity between models, alignment in training data, and the regularization techniques used. Techniques like input diversity (random resizing, cropping) and momentum during optimization can be used to increase transferability.
Physical-world Attacks
Physical-world attacks bring adversarial examples into the realm of real-world scenarios. These attacks involve creating physical objects or manipulations that can deceive ML models when captured by sensors or cameras. Adversarial patches, for example, are small, carefully designed patterns that can be placed on objects to fool object detection or classification models. These patches are designed to work under varying lighting conditions, viewing angles, and distances, making them robust in real-world environments.
When attached to real-world objects, such as a stop sign or a piece of clothing, these patches can cause models to misclassify or fail to detect the objects accurately. Notably, the effectiveness of these attacks persists even after being printed out and viewed through a camera lens, bridging the digital and physical divide in adversarial ML.
Adversarial objects, such as 3D-printed sculptures or modified road signs, can also be crafted to deceive ML systems in physical environments. For example, a 3D turtle object was shown to be consistently classified as a rifle by an image classifier, even when viewed from different angles. These attacks underscore the risks facing AI systems deployed in physical spaces, such as autonomous vehicles, drones, and surveillance systems.
Research into physical-world attacks also includes efforts to develop universal adversarial perturbations—perturbations that can fool a wide range of inputs and models. These threats raise serious questions about safety, robustness, and generalization in AI systems.
Summary
Table 2 provides a concise overview of the different categories of adversarial attacks, including gradient-based attacks (FGSM, PGD, JSMA), optimization-based attacks (C&W, EAD), transfer-based attacks, and physical-world attacks (adversarial patches and objects). Each attack is briefly described, highlighting its key characteristics and mechanisms.
The mechanisms of adversarial attacks reveal the intricate interplay between the ML model’s decision boundaries, the input data, and the attacker’s objectives. By carefully manipulating the input data, attackers can exploit the model’s sensitivities and blind spots, leading to incorrect predictions. The success of adversarial attacks highlights the need for a deeper understanding of ML models’ robustness and generalization properties.
| Attack Category | Attack Name | Description |
|---|---|---|
| Gradient-based | Fast Gradient Sign Method (FGSM) Projected Gradient Descent (PGD) Jacobian-based Saliency Map Attack (JSMA) | Perturbs input data by adding small noise in the gradient direction to maximize prediction error. Extends FGSM by iteratively applying the gradient update step for more refined adversarial examples. Identifies influential input features and perturbs them to create adversarial examples. |
| Optimization-based | Carlini and Wagner (C&W) Attack Elastic Net Attack to DNNs (EAD) | Finds the smallest perturbation that causes misclassification while maintaining perceptual similarity. Incorporates elastic net regularization to generate adversarial examples with sparse perturbations. |
| Transfer-based | Transferability-based Attacks | Exploits the transferability of adversarial examples across different models, enabling black-box attacks. |
| Physical-world | Adversarial Patches Adversarial Objects | Small, carefully designed patches placed on objects to fool object detection or classification models. Physical objects (e.g., 3D-printed sculptures, modified road signs) crafted to deceive ML systems in real-world scenarios. |
Defending against adversarial attacks requires a multifaceted approach. Adversarial training is one common defense strategy in which models are trained on adversarial examples to improve robustness. Exposing the model to adversarial examples during training teaches it to classify them correctly and become more resilient to attacks. Defensive distillation, input preprocessing, and ensemble methods are other techniques that can help mitigate the impact of adversarial attacks.
As adversarial machine learning evolves, researchers explore new attack mechanisms and develop more sophisticated defenses. The arms race between attackers and defenders drives the need for constant innovation and vigilance in securing ML systems against adversarial threats. Understanding the mechanisms of adversarial attacks is crucial for developing robust and reliable ML models that can withstand the ever-evolving landscape of adversarial examples.
Impact on ML
Adversarial attacks on machine learning systems have emerged as a significant concern in recent years, highlighting the potential vulnerabilities and risks associated with the widespread adoption of ML technologies. These attacks involve carefully crafted perturbations to input data that can deceive or mislead ML models, leading to incorrect predictions or misclassifications, as shown in Figure 21. The impact of adversarial attacks on ML systems is far-reaching and can have serious consequences in various domains.

One striking example of the impact of adversarial attacks was demonstrated by researchers in 2017. They experimented with small black and white stickers on stop signs (Eykholt et al. 2017). To the human eye, these stickers did not obscure the sign or prevent its interpretability. However, when images of the sticker-modified stop signs were fed into standard traffic sign classification ML models, a shocking result emerged. The models misclassified the stop signs as speed limit signs over 85% of the time.
This demonstration shed light on the alarming potential of simple adversarial stickers to trick ML systems into misreading critical road signs. The implications of such attacks in the real world are significant, particularly in the context of autonomous vehicles. If deployed on actual roads, these adversarial stickers could cause self-driving cars to misinterpret stop signs as speed limits, leading to dangerous situations, as shown in Figure 22. Researchers warned that this could result in rolling stops or unintended acceleration into intersections, endangering public safety.

The case study of the adversarial stickers on stop signs provides a concrete illustration of how adversarial examples exploit how ML models recognize patterns. By subtly manipulating the input data in ways that are invisible to humans, attackers can induce incorrect predictions and create serious risks, especially in safety-critical applications like autonomous vehicles. The attack’s simplicity highlights the vulnerability of ML models to even minor changes in the input, emphasizing the need for robust defenses against such threats.
The impact of adversarial attacks extends beyond the degradation of model performance. These attacks raise significant security and safety concerns, particularly in domains where ML models are relied upon for critical decision-making. In healthcare applications, adversarial attacks on medical imaging models could lead to misdiagnosis or incorrect treatment recommendations, jeopardizing patient well-being (M.-J. Tsai, Lin, and Lee 2023). In financial systems, adversarial attacks could enable fraud or manipulation of trading algorithms, resulting in substantial economic losses.
Moreover, adversarial vulnerabilities undermine the trustworthiness and interpretability of ML models. If carefully crafted perturbations can easily fool models, confidence in their predictions and decisions erodes. Adversarial examples expose the models’ reliance on superficial patterns and the inability to capture the true underlying concepts, challenging the reliability of ML systems (Fursov et al. 2021).
Defending against adversarial attacks often requires additional computational resources and can impact the overall system performance. Techniques like adversarial training, where models are trained on adversarial examples to improve robustness, can significantly increase training time and computational requirements (Bai et al. 2021). Runtime detection and mitigation mechanisms, such as input preprocessing (Addepalli et al. 2020) or prediction consistency checks, introduce latency and affect the real-time performance of ML systems.
The presence of adversarial vulnerabilities also complicates the deployment and maintenance of ML systems. System designers and operators must consider the potential for adversarial attacks and incorporate appropriate defenses and monitoring mechanisms. Regular updates and retraining of models become necessary to adapt to new adversarial techniques and maintain system security and performance over time.
The impact of adversarial attacks on ML systems is significant and multifaceted. These attacks expose ML models’ vulnerabilities, from degrading model performance and raising security and safety concerns to challenging model trustworthiness and interpretability. Developers and researchers must prioritize the development of robust defenses and countermeasures to mitigate the risks posed by adversarial attacks. By addressing these challenges, we can build more secure, reliable, and trustworthy ML systems that can withstand the ever-evolving landscape of adversarial threats.
Data Poisoning
Data poisoning presents a critical challenge to the integrity and reliability of machine learning systems. By introducing carefully crafted malicious data into the training pipeline, adversaries can subtly manipulate model behavior in ways that are difficult to detect through standard validation procedures. Unlike adversarial examples, which target models at inference time, poisoning attacks exploit upstream components of the system—such as data collection, labeling, or ingestion. As ML systems are increasingly deployed in automated and high-stakes environments, understanding how poisoning occurs and how it propagates through the system is essential for developing effective defenses.
Characteristics
Data poisoning is an attack in which the training data is deliberately manipulated to compromise the performance or behavior of a machine learning model, as described in (Biggio, Nelson, and Laskov 2012) and illustrated in Figure 23. Attackers may alter existing training samples, introduce malicious examples, or interfere with the data collection pipeline. The result is a model that learns biased, inaccurate, or exploitable patterns.

In most cases, data poisoning unfolds in three stages.
In the injection stage, the attacker introduces poisoned samples into the training dataset. These samples may be altered versions of existing data or entirely new instances designed to blend in with clean examples. While they appear benign on the surface, these inputs are engineered to influence model behavior in subtle but deliberate ways. The attacker may target specific classes, insert malicious triggers, or craft outliers intended to distort the decision boundary.
During the training phase, the machine learning model incorporates the poisoned data and learns spurious or misleading patterns. These learned associations may bias the model toward incorrect classifications, introduce vulnerabilities, or embed backdoors. Because the poisoned data is often statistically similar to clean data, the corruption process typically goes unnoticed during standard model training and evaluation.
Finally, in the deployment stage, the attacker leverages the compromised model for malicious purposes. This could involve triggering specific behaviors, including the misclassification of an input that contains a hidden pattern, or simply exploiting the model’s degraded accuracy in production. In real-world systems, such attacks can be difficult to trace back to training data, especially if the system’s behavior appears erratic only in edge cases or under adversarial conditions.
The consequences of such manipulation are especially severe in high-stakes domains like healthcare, where even small disruptions to training data can lead to dangerous misdiagnoses or loss of trust in AI-based systems (Marulli, Marrone, and Verde 2022).
Four main categories of poisoning attacks have been identified in the literature (Oprea, Singhal, and Vassilev 2022). In availability attacks, a substantial portion of the training data is poisoned with the aim of degrading overall model performance. A classic example involves flipping labels—for instance, systematically changing instances with true label \(y = 1\) to \(y = 0\) in a binary classification task. These attacks render the model unreliable across a wide range of inputs, effectively making it unusable.
In contrast, targeted poisoning attacks aim to compromise only specific classes or instances. Here, the attacker modifies just enough data to cause a small set of inputs to be misclassified, while overall accuracy remains relatively stable. This subtlety makes targeted attacks especially hard to detect.
Backdoor poisoning introduces hidden triggers into training data—subtle patterns or features that the model learns to associate with a particular output. When the trigger appears at inference time, the model is manipulated into producing a predetermined response. These attacks are often effective even if the trigger pattern is imperceptible to human observers.
Subpopulation poisoning focuses on compromising a specific subset of the data population. While similar in intent to targeted attacks, subpopulation poisoning applies availability-style degradation to a localized group, for example, a particular demographic or feature cluster, while leaving the rest of the model’s performance intact. This distinction makes such attacks both highly effective and especially dangerous in fairness-sensitive applications.
A common thread across these poisoning strategies is their subtlety. Manipulated samples are typically indistinguishable from clean data, making them difficult to identify through casual inspection or standard data validation. These manipulations might involve small changes to numeric values, slight label inconsistencies, or embedded visual patterns—each designed to blend into the data distribution while still affecting model behavior.
Such attacks may be carried out by internal actors, like data engineers or annotators with privileged access, or by external adversaries who exploit weak points in the data collection pipeline. In crowdsourced environments or open data collection scenarios, poisoning can be as simple as injecting malicious samples into a shared dataset or influencing user-generated content.
Crucially, poisoning attacks often target the early stages of the ML pipeline, such as collection and preprocessing, where there may be limited oversight. If data is pulled from unverified sources or lacks strong validation protocols, attackers can slip in poisoned data that appears statistically normal. The absence of integrity checks, robust outlier detection, or lineage tracking only heightens the risk.
Ultimately, the goal of these attacks is to corrupt the learning process itself. A model trained on poisoned data may learn spurious correlations, overfit to false signals, or become vulnerable to highly specific exploit conditions. Whether the result is a degraded model or one with a hidden exploit path, the trustworthiness and safety of the system are fundamentally compromised.
Mechanisms
Data poisoning can be implemented through a variety of mechanisms, depending on the attacker’s access to the system and understanding of the data pipeline. These mechanisms reflect different strategies for how the training data can be corrupted to achieve malicious outcomes.
One of the most direct approaches involves modifying the labels of training data. In this method, an attacker selects a subset of training samples and alters their labels—flipping \(y = 1\) to \(y = 0\), or reassigning categories in multi-class settings. As shown in Figure 24, even small-scale label inconsistencies can lead to significant distributional shifts and learning disruptions.

Another mechanism involves modifying the input features of training examples without changing the labels. This might include imperceptible pixel-level changes in images, subtle perturbations in structured data, or embedding fixed patterns that act as triggers for backdoor attacks. These alterations are often designed using optimization techniques that maximize their influence on the model while minimizing detectability.
More sophisticated attacks generate entirely new, malicious training examples. These synthetic samples may be created using adversarial methods, generative models, or even data synthesis tools. The aim is to carefully craft inputs that will distort the decision boundary of the model when incorporated into the training set. Such inputs may appear natural and legitimate but are engineered to introduce vulnerabilities.
Other attackers focus on weaknesses in data collection and preprocessing. If the training data is sourced from web scraping, social media, or untrusted user submissions, poisoned samples can be introduced upstream. These samples may pass through insufficient cleaning or validation checks, reaching the model in a “trusted” form. This is particularly dangerous in automated pipelines where human review is limited or absent.
In physically deployed systems, attackers may manipulate data at the source—for example, altering the environment captured by a sensor. A self-driving car might encounter poisoned data if visual markers on a road sign are subtly altered, causing the model to misclassify it during training. This kind of environmental poisoning blurs the line between adversarial attacks and data poisoning, but the mechanism, which involves compromising the training data, is the same.
Online learning systems represent another unique attack surface. These systems continuously adapt to new data streams, making them particularly susceptible to gradual poisoning. An attacker may introduce malicious samples incrementally, causing slow but steady shifts in model behavior. This form of attack is illustrated in Figure 25.

Insider collaboration adds a final layer of complexity. Malicious actors with legitimate access to training data, including annotators, researchers, or data vendors, can craft poisoning strategies that are more targeted and subtle than external attacks. These insiders may have knowledge of the model architecture or training procedures, giving them an advantage in designing effective poisoning schemes.
Defending against these diverse mechanisms requires a multi-pronged approach: secure data collection protocols, anomaly detection, robust preprocessing pipelines, and strong access control. Validation mechanisms must be sophisticated enough to detect not only outliers but also cleverly disguised poisoned samples that sit within the statistical norm.
Impact on ML
The effects of data poisoning extend far beyond simple accuracy degradation. In the most general sense, a poisoned dataset leads to a corrupted model. But the specific consequences depend on the attack vector and the adversary’s objective.
One common outcome is the degradation of overall model performance. When large portions of the training set are poisoned, often through label flipping or the introduction of noisy features, the model struggles to identify valid patterns, leading to lower accuracy, recall, or precision. In mission-critical applications like medical diagnosis or fraud detection, even small performance losses can result in significant real-world harm.
Targeted poisoning presents a different kind of danger. Rather than undermining the model’s general performance, these attacks cause specific misclassifications. A malware detector, for instance, may be engineered to ignore one particular signature, allowing a single attack to bypass security. Similarly, a facial recognition model might be manipulated to misidentify a specific individual, while functioning normally for others.
Some poisoning attacks introduce hidden vulnerabilities in the form of backdoors or trojans. These poisoned models behave as expected during evaluation but respond in a malicious way when presented with specific triggers. In such cases, attackers can “activate” the exploit on demand, bypassing system protections without triggering alerts.
Bias is another insidious impact of data poisoning. If an attacker poisons samples tied to a specific demographic or feature group, they can skew the model’s outputs in biased or discriminatory ways. Such attacks threaten fairness, amplify existing societal inequities, and are difficult to diagnose if the overall model metrics remain high.
Ultimately, data poisoning undermines the trustworthiness of the system itself. A model trained on poisoned data cannot be considered reliable, even if it performs well in benchmark evaluations. This erosion of trust has profound implications, particularly in fields like autonomous systems, financial modeling, and public policy.
Case Study: Art Protection via Poisoning
Interestingly, not all data poisoning is malicious. Researchers have begun to explore its use as a defensive tool, particularly in the context of protecting creative work from unauthorized use by generative AI models.
A compelling example is Nightshade, developed by researchers at the University of Chicago to help artists prevent their work from being scraped and used to train image generation models without consent (Shan et al. 2023). Nightshade allows artists to apply subtle perturbations to their images before publishing them online. These changes are invisible to human viewers but cause serious degradation in generative models that incorporate them into training.
When Stable Diffusion was trained on just 300 poisoned images, the model began producing bizarre outputs—such as cows when prompted with “car,” or cat-like creatures in response to “dog.” These results, visualized in Figure 26, show how effectively poisoned samples can distort a model’s conceptual associations.

What makes Nightshade especially potent is the cascading effect of poisoned concepts. Because generative models rely on semantic relationships between categories, a poisoned “car” can bleed into related concepts like “truck,” “bus,” or “train,” leading to widespread hallucinations.
However, like any powerful tool, Nightshade also introduces risks. The same technique used to protect artistic content could be repurposed to sabotage legitimate training pipelines, highlighting the dual-use dilemma18 at the heart of modern machine learning security.
18 Dual-use Dilemma: In AI, the challenge of mitigating misuse of technology that has both positive and negative potential uses.
Distribution Shifts
Characteristics
Distribution shift refers to the phenomenon where the data distribution encountered by a machine learning model during deployment differs from the distribution it was trained on, as shown in Figure 27. This change in distribution is not necessarily the result of a malicious attack. Rather, it often reflects the natural evolution of real-world environments over time. In essence, the statistical properties, patterns, or assumptions in the data may change between training and inference phases, which can lead to unexpected or degraded model performance.

A distribution shift typically takes one of several forms:
- Covariate shift, where the input distribution \(P(x)\) changes while the conditional label distribution \(P(y \mid x)\) remains stable.
- Label shift, where the label distribution \(P(y)\) changes while \(P(x \mid y)\) stays the same.
- Concept drift, where the relationship between inputs and outputs—\(P(y \mid x)\)—evolves over time.
- Concept drift, where the relationship between inputs and outputs, \(P(y \mid x)\), evolves over time.
These formal definitions help frame more intuitive examples of shift that are commonly encountered in practice.
One of the most common causes is domain mismatch, where the model is deployed on data from a different domain than it was trained on. For example, a sentiment analysis model trained on movie reviews may perform poorly when applied to tweets, due to differences in language, tone, and structure. In this case, the model has learned domain-specific features that do not generalize well to new contexts.
Another major source is temporal drift, where the input distribution evolves gradually or suddenly over time. In production settings, data changes due to new trends, seasonal effects, or shifts in user behavior. For instance, in a fraud detection system, fraud patterns may evolve as adversaries adapt. Without ongoing monitoring or retraining, models become stale and ineffective. This form of shift is visualized in Figure 28.
Contextual changes arise when deployment environments differ from training conditions due to external factors such as lighting, sensor variation, or user behavior. For example, a vision model trained in a lab under controlled lighting may underperform when deployed in outdoor or dynamic environments.
Another subtle but critical factor is unrepresentative training data. If the training dataset fails to capture the full variability of the production environment, the model may generalize poorly. For example, a facial recognition model trained predominantly on one demographic group may produce biased or inaccurate predictions when deployed more broadly. In this case, the shift reflects missing diversity or structure in the training data.

Distribution shifts like these can dramatically reduce the performance and reliability of ML models in production. Building robust systems requires not only understanding these shifts, but actively detecting and responding to them as they emerge.
Mechanisms
Distribution shifts arise from a variety of underlying mechanisms—both natural and system-driven. Understanding these mechanisms helps practitioners detect, diagnose, and design mitigation strategies.
One common mechanism is a change in data sources. When data collected at inference time comes from different sensors, APIs, platforms, or hardware than the training data, even subtle differences in resolution, formatting, or noise can introduce significant shifts. For example, a speech recognition model trained on audio from one microphone type may struggle with data from a different device.
Temporal evolution refers to changes in the underlying data over time. In recommendation systems, user preferences shift. In finance, market conditions change. These shifts may be slow and continuous or abrupt and disruptive. Without temporal awareness or continuous evaluation, models can become obsolete, frequently without prior indication. To illustrate this, Figure 29 shows how selective breeding over generations has significantly changed the physical characteristics of a dog breed. The earlier version of the breed exhibits a lean, athletic build, while the modern version is stockier, with a distinctively different head shape and musculature. This transformation is analogous to how data distributions can shift in real-world systems—initial data used to train a model may differ substantially from the data encountered over time. Just as evolutionary pressures shape biological traits, dynamic user behavior, market forces, or changing environments can shift the distribution of data in machine learning applications. Without periodic retraining or adaptation, models exposed to these evolving distributions may underperform or become unreliable.

Domain-specific variation arises when a model trained on one setting is applied to another. A medical diagnosis model trained on data from one hospital may underperform in another due to differences in equipment, demographics, or clinical workflows. These variations often require explicit adaptation strategies, such as domain generalization or fine-tuning.
Selection bias occurs when the training data does not accurately reflect the target population. This may result from sampling strategies, data access constraints, or labeling choices. The result is a model that overfits to specific segments and fails to generalize. Addressing this requires thoughtful data collection and continuous validation.
Feedback loops are a particularly subtle mechanism. In some systems, model predictions influence user behavior, which in turn affects future inputs. For instance, a dynamic pricing model might set prices that change buying patterns, which then distort the distribution of future training data. These loops can reinforce narrow patterns and make model behavior difficult to predict.
Lastly, adversarial manipulation can induce distribution shifts deliberately. Attackers may introduce out-of-distribution samples or craft inputs that exploit weak spots in the model’s decision boundary. These inputs may lie far from the training distribution and can cause unexpected or unsafe predictions.
These mechanisms often interact, making real-world distribution shift detection and mitigation complex. From a systems perspective, this complexity necessitates ongoing monitoring, logging, and feedback pipelines—features often absent in early-stage or static ML deployments.
Impact on ML
Distribution shift can affect nearly every dimension of ML system performance, from prediction accuracy and latency to user trust and system maintainability.
A common and immediate consequence is degraded predictive performance. When the data at inference time differs from training data, the model may produce systematically inaccurate or inconsistent predictions. This erosion of accuracy is particularly dangerous in high-stakes applications like fraud detection, autonomous vehicles, or clinical decision support.
Another serious effect is loss of reliability and trustworthiness. As distribution shifts, users may notice inconsistent or erratic behavior. For example, a recommendation system might begin suggesting irrelevant or offensive content. Even if overall accuracy metrics remain acceptable, loss of user trust can undermine the system’s value.
Distribution shift also amplifies model bias. If certain groups or data segments are underrepresented in the training data, the model may fail more frequently on those groups. Under shifting conditions, these failures can become more pronounced, resulting in discriminatory outcomes or fairness violations.
There is also a rise in uncertainty and operational risk. In many production settings, model decisions feed directly into business operations or automated actions. Under shift, these decisions become less predictable and harder to validate, increasing the risk of cascading failures or poor decisions downstream.
From a system maintenance perspective, distribution shifts complicate retraining and deployment workflows. Without robust mechanisms for drift detection and performance monitoring, shifts may go unnoticed until performance degrades significantly. Once detected, retraining may be required—raising challenges related to data collection, labeling, model rollback, and validation. This creates friction in continuous integration and deployment (CI/CD) workflows and can significantly slow down iteration cycles.
Moreover, distribution shift increases vulnerability to adversarial attacks. Attackers can exploit the model’s poor calibration on unfamiliar data, using slight perturbations to push inputs outside the training distribution and cause failures. This is especially concerning when system feedback loops or automated decisioning pipelines are in place.
From a systems perspective, distribution shift is not just a modeling concern—it is a core operational challenge. It requires end-to-end system support: mechanisms for data logging, drift detection, automated alerts, model versioning, and scheduled retraining. ML systems must be designed to detect when performance degrades in production, diagnose whether a distribution shift is the cause, and trigger appropriate mitigation actions. This might include human-in-the-loop review, fallback strategies, model retraining pipelines, or staged deployment rollouts.
In mature ML systems, handling distribution shift becomes a matter of infrastructure, observability, and automation, not just modeling technique. Failing to account for it risks silent model failure in dynamic, real-world environments—precisely where ML systems are expected to deliver the most value.
A summary of common types of distribution shifts, their effects on model performance, and potential system-level responses is shown in Table 3.
| Type of Shift | Cause or Example | Consequence for Model | System-Level Response |
|---|---|---|---|
| Covariate Shift | Change in input features (e.g., sensor calibration drift) | Model misclassifies new inputs despite consistent labels | Monitor input distributions; retrain with updated features |
| Label Shift | Change in label distribution (e.g., new class frequencies in usage) | Prediction probabilities become skewed | Track label priors; reweight or adapt output calibration |
| Concept Drift | Evolving relationship between inputs and outputs (e.g. fraud tactics) | Model performance degrades over time | Retrain frequently; use continual or online learning |
| Domain Mismatch | Train on reviews, deploy on tweets | Poor generalization due to different vocabularies or styles | Use domain adaptation or fine-tuning |
| Contextual Change | New deployment environment (e.g., lighting, user behavior) | Performance varies by context | Collect contextual data; monitor conditional accuracy |
| Selection Bias | Underrepresentation during training | Biased predictions for unseen groups | Validate dataset balance; augment training data |
| Feedback Loops | Model outputs affect future inputs (e.g., recommender systems) | Reinforced drift, unpredictable patterns | Monitor feedback effects; consider counterfactual logging |
| Adversarial Shift | Attackers introduce OOD inputs or perturbations | Model becomes vulnerable to targeted failures | Use robust training; detect out-of-distribution inputs |
Summary of Distribution Shifts and System Implications
Detection and Mitigation
The detection and mitigation of threats to ML systems requires combining defensive strategies across multiple layers. These include techniques to identify and counter adversarial attacks, data poisoning attempts, and distribution shifts that can degrade model performance and reliability. Through systematic application of these protections, ML systems can maintain robustness when deployed in dynamic real-world environments.
Adversarial Attacks
As discussed earlier, adversarial attacks pose a significant threat to the robustness and reliability of ML systems. These attacks involve crafting carefully designed inputs, known as adversarial examples, to deceive ML models and cause them to make incorrect predictions. To safeguard ML systems against such attacks, it is crucial to develop effective techniques for detecting and mitigating these threats.
Detection Techniques
Detecting adversarial examples is the first line of defense against adversarial attacks. Several techniques have been proposed to identify and flag suspicious inputs that may be adversarial.
Statistical methods represent one approach to detecting adversarial examples by analyzing the distributional properties of input data. These methods compare the input data distribution to a reference distribution, such as the training data distribution or a known benign distribution. Techniques like the Kolmogorov-Smirnov (Berger and Zhou 2014) test or the Anderson-Darling test can measure the discrepancy between distributions and flag inputs that deviate significantly from the expected distribution. A related approach, kernel density estimation (KDE), estimates the probability density function of benign examples in the input space. Since adversarial examples often lie in low-density regions, inputs with estimated density below a threshold can be flagged as potentially adversarial.
Beyond distributional analysis, input transformation methods offer an alternative detection strategy. Feature squeezing (Panda, Chakraborty, and Roy 2019) reduces input space complexity through dimensionality reduction or discretization, eliminating the small, imperceptible perturbations that adversarial examples typically rely on. Inconsistencies between model predictions on original and squeezed inputs indicate potential adversarial manipulation.
Model uncertainty estimation provides yet another detection paradigm by quantifying the confidence associated with predictions. Since adversarial examples often exploit regions of high uncertainty in the model’s decision boundary, inputs with elevated uncertainty can be flagged as suspicious. Several approaches exist for uncertainty estimation, each with distinct trade-offs between accuracy and computational cost.
Bayesian neural networks provide the most principled uncertainty estimates by treating model weights as probability distributions, capturing both aleatoric (data inherent) and epistemic (model) uncertainty through approximate inference methods. Ensemble methods achieve uncertainty estimation by combining predictions from multiple independently trained models, using prediction variance as an uncertainty measure. While both approaches offer robust uncertainty quantification, they incur significant computational overhead.
Dropout, originally designed as a regularization technique to prevent overfitting during training (Hinton et al. 2012), works by randomly deactivating a fraction of neurons during each training iteration, forcing the network to avoid over-reliance on specific neurons and improving generalization. This mechanism can be repurposed for uncertainty estimation through Monte Carlo dropout at inference time, where multiple forward passes with different dropout masks approximate the uncertainty distribution. However, this approach provides less precise uncertainty estimates since dropout was not specifically designed for uncertainty quantification but rather for preventing overfitting through enforced redundancy. Hybrid approaches that combine dropout with lightweight ensemble methods or Bayesian approximations can balance computational efficiency with estimation quality, making uncertainty-based detection more practical for real-world deployment.
Defense Strategies
Once adversarial examples are detected, various defense strategies can be employed to mitigate their impact and improve the robustness of ML models.
Adversarial training is a technique that involves augmenting the training data with adversarial examples and retraining the model on this augmented dataset. Exposing the model to adversarial examples during training teaches it to classify them correctly and becomes more robust to adversarial attacks. Adversarial training can be performed using various attack methods, such as the Fast Gradient Sign Method or Projected Gradient Descent (Madry et al. 2017).
Defensive distillation (Papernot et al. 2016) is a technique that trains a second model (the student model) to mimic the behavior of the original model (the teacher model). The student model is trained on the soft labels produced by the teacher model, which are less sensitive to small perturbations. Using the student model for inference can reduce the impact of adversarial perturbations, as the student model learns to generalize better and is less sensitive to adversarial noise.
Input preprocessing and transformation techniques try to remove or mitigate the effect of adversarial perturbations before feeding the input to the ML model. These techniques include image denoising, JPEG compression, random resizing, padding, or applying random transformations to the input data. By reducing the impact of adversarial perturbations, these preprocessing steps can help improve the model’s robustness to adversarial attacks.
Ensemble methods combine multiple models to make more robust predictions. The ensemble can reduce the impact of adversarial attacks by using a diverse set of models with different architectures, training data, or hyperparameters. Adversarial examples that fool one model may not fool others in the ensemble, leading to more reliable and robust predictions. Model diversification techniques, such as using different preprocessing techniques or feature representations for each model in the ensemble, can further enhance the robustness.
Evaluation and Testing
Conduct thorough evaluation and testing to assess the effectiveness of adversarial defense techniques and measure the robustness of ML models.
Adversarial robustness metrics quantify the model’s resilience to adversarial attacks. These metrics can include the model’s accuracy on adversarial examples, the average distortion required to fool the model, or the model’s performance under different attack strengths. By comparing these metrics across different models or defense techniques, practitioners can assess and compare their robustness levels.
Standardized adversarial attack benchmarks and datasets provide a common ground for evaluating and comparing the robustness of ML models. These benchmarks include datasets with pre-generated adversarial examples and tools and frameworks for generating adversarial attacks. Examples of popular adversarial attack benchmarks include the MNIST-C, CIFAR-10-C, and ImageNet-C (Hendrycks and Dietterich 2019) datasets, which contain corrupted or perturbed versions of the original datasets.
Practitioners can develop more robust and resilient ML systems by leveraging these adversarial example detection techniques, defense strategies, and robustness evaluation methods. However, it is important to note that adversarial robustness is an ongoing research area, and no single technique provides complete protection against all types of adversarial attacks. A comprehensive approach that combines multiple defense mechanisms and regular testing is essential to maintain the security and reliability of ML systems in the face of evolving adversarial threats.
Data Poisoning
Data poisoning attacks aim to corrupt training data used to build ML models, undermining their integrity. As illustrated in Figure 30, these attacks can manipulate or pollute the training data in ways that cause models to learn incorrect patterns, leading to erroneous predictions or undesirable behaviors when deployed. Given the foundational role of training data in ML system performance, detecting and mitigating data poisoning is critical for maintaining model trustworthiness and reliability.

Anomaly Detection Techniques
Statistical outlier detection methods identify data points that deviate significantly from most data. These methods assume that poisoned data instances are likely to be statistical outliers. Techniques such as the Z-score method, Tukey’s method, or the Mahalanobis distance can be used to measure the deviation of each data point from the central tendency of the dataset. Data points that exceed a predefined threshold are flagged as potential outliers and considered suspicious for data poisoning.
Clustering-based methods group similar data points together based on their features or attributes. The assumption is that poisoned data instances may form distinct clusters or lie far away from the normal data clusters. By applying clustering algorithms like K-means, DBSCAN, or hierarchical clustering, anomalous clusters or data points that do not belong to any cluster can be identified. These anomalous instances are then treated as potentially poisoned data.
Autoencoders are neural networks trained to reconstruct the input data from a compressed representation, as shown in Figure 31. They can be used for anomaly detection by learning the normal patterns in the data and identifying instances that deviate from them. During training, the autoencoder is trained on clean, unpoisoned data. At inference time, the reconstruction error for each data point is computed. Data points with high reconstruction errors are considered abnormal and potentially poisoned, as they do not conform to the learned normal patterns.

Sanitization and Preprocessing
Data poisoning can be avoided by cleaning data, which involves identifying and removing or correcting noisy, incomplete, or inconsistent data points. Techniques such as data deduplication, missing value imputation, and outlier removal can be applied to improve the quality of the training data. By eliminating or filtering out suspicious or anomalous data points, the impact of poisoned instances can be reduced.
Data validation involves verifying the integrity and consistency of the training data. This can include checking for data type consistency, range validation, and cross-field dependencies. By defining and enforcing data validation rules, anomalous or inconsistent data points indicative of data poisoning can be identified and flagged for further investigation.
Data provenance and lineage tracking involve maintaining a record of data’s origin, transformations, and movements throughout the ML pipeline. By documenting the data sources, preprocessing steps, and any modifications made to the data, practitioners can trace anomalies or suspicious patterns back to their origin. This helps identify potential points of data poisoning and facilitates the investigation and mitigation process.
Robust Training
Robust optimization techniques can be used to modify the training objective to minimize the impact of outliers or poisoned instances. This can be achieved by using robust loss functions less sensitive to extreme values, such as the Huber loss or the modified Huber loss19. Regularization techniques20, such as L1 or L2 regularization, can also help in reducing the model’s sensitivity to poisoned data by constraining the model’s complexity and preventing overfitting.
19 Huber Loss: A loss function used in robust regression that is less sensitive to outliers in data than squared error loss.
20 Regularization: A method used in neural networks to prevent overfitting in models by adding a cost term to the loss function.
21 Minimax: A decision-making strategy, used in game theory and decision theory, which tries to minimize the maximum possible loss.
Robust loss functions are designed to be less sensitive to outliers or noisy data points. Examples include the modified Huber loss, the Tukey loss (Beaton and Tukey 1974), and the trimmed mean loss. These loss functions down-weight or ignore the contribution of abnormal instances during training, reducing their impact on the model’s learning process. Robust objective functions, such as the minimax21 or distributionally robust objective, aim to optimize the model’s performance under worst-case scenarios or in the presence of adversarial perturbations.
Data augmentation techniques involve generating additional training examples by applying random transformations or perturbations to the existing data Figure 32. This helps in increasing the diversity and robustness of the training dataset. By introducing controlled variations in the data, the model becomes less sensitive to specific patterns or artifacts that may be present in poisoned instances. Randomization techniques, such as random subsampling or bootstrap aggregating, can also help reduce the impact of poisoned data by training multiple models on different subsets of the data and combining their predictions.

Secure Data Sourcing
Implementing the best data collection and curation practices can help mitigate the risk of data poisoning. This includes establishing clear data collection protocols, verifying the authenticity and reliability of data sources, and conducting regular data quality assessments. Sourcing data from trusted and reputable providers and following secure data handling practices can reduce the likelihood of introducing poisoned data into the training pipeline.
Strong data governance and access control mechanisms are essential to prevent unauthorized modifications or tampering with the training data. This involves defining clear roles and responsibilities for data access, implementing access control policies based on the principle of least privilege,22 and monitoring and logging data access activities. By restricting access to the training data and maintaining an audit trail, potential data poisoning attempts can be detected and investigated.
22 Principle of Least Privilege: A security concept in which a user is given the minimum levels of access necessary to complete his/her job functions.
23 Data Sanitization: The process of deliberately, permanently, and irreversibly removing or destroying the data stored on a memory device to make it unrecoverable.
Detecting and mitigating data poisoning attacks requires a multifaceted approach that combines anomaly detection, data sanitization,23 robust training techniques, and secure data sourcing practices. By implementing these measures, ML practitioners can improve the resilience of their models against data poisoning and ensure the integrity and trustworthiness of the training data. However, it is important to note that data poisoning is an active area of research, and new attack vectors and defense mechanisms continue to emerge. Staying informed about the latest developments and adopting a proactive and adaptive approach to data security is crucial for maintaining the robustness of ML systems.
Distribution Shifts
Detection and Mitigation
Recall that distribution shifts occur when the data distribution encountered by a machine learning (ML) model during deployment differs from the distribution it was trained on. These shifts can significantly impact the model’s performance and generalization ability, leading to suboptimal or incorrect predictions. Detecting and mitigating distribution shifts is crucial to ensure the robustness and reliability of ML systems in real-world scenarios.
Detection Techniques
Statistical tests can be used to compare the distributions of the training and test data to identify significant differences. Techniques such as the Kolmogorov-Smirnov test or the Anderson-Darling test measure the discrepancy between two distributions and provide a quantitative assessment of the presence of distribution shift. By applying these tests to the input features or the model’s predictions, practitioners can detect if there is a statistically significant difference between the training and test distributions.
Divergence metrics quantify the dissimilarity between two probability distributions. Commonly used divergence metrics include the Kullback-Leibler (KL) divergence and the Jensen-Shannon (JS) divergence. By calculating the divergence between the training and test data distributions, practitioners can assess the extent of the distribution shift. High divergence values indicate a significant difference between the distributions, suggesting the presence of a distribution shift.
Uncertainty quantification techniques, such as Bayesian neural networks24 or ensemble methods25, can estimate the uncertainty associated with the model’s predictions. When a model is applied to data from a different distribution, its predictions may have higher uncertainty. By monitoring the uncertainty levels, practitioners can detect distribution shifts. If the uncertainty consistently exceeds a predetermined threshold for test samples, it suggests that the model is operating outside its trained distribution.
24 Bayesian Neural Networks: Neural networks that incorporate probability distributions over their weights, enabling uncertainty quantification in predictions and more robust decision making.
25 Ensemble Methods: An ML approach that combines several models to improve prediction accuracy.
In addition, domain classifiers are trained to distinguish between different domains or distributions. Practitioners can detect distribution shifts by training a classifier to differentiate between the training and test domains. If the domain classifier achieves high accuracy in distinguishing between the two domains, it indicates a significant difference in the underlying distributions. The performance of the domain classifier serves as a measure of the distribution shift.
Mitigation Techniques
Transfer learning leverages knowledge gained from one domain to improve performance in another, as shown in Figure 33. By using pre-trained models or transferring learned features from a source domain to a target domain, transfer learning can help mitigate the impact of distribution shifts. The pre-trained model can be fine-tuned on a small amount of labeled data from the target domain, allowing it to adapt to the new distribution. Transfer learning is particularly effective when the source and target domains share similar characteristics or when labeled data in the target domain is scarce.

Continual learning, also known as lifelong learning, enables ML models to learn continuously from new data distributions while retaining knowledge from previous distributions. Techniques such as elastic weight consolidation (EWC) (Kirkpatrick et al. 2017) or gradient episodic memory (GEM) (Lopez-Paz and Ranzato 2017) allow models to adapt to evolving data distributions over time. These techniques aim to balance the plasticity of the model (ability to learn from new data) with the stability of the model (retaining previously learned knowledge). By incrementally updating the model with new data and mitigating catastrophic forgetting, continual learning helps models stay robust to distribution shifts.
Data augmentation techniques, such as those we have seen previously, involve applying transformations or perturbations to the existing training data to increase its diversity and improve the model’s robustness to distribution shifts. By introducing variations in the data, such as rotations, translations, scaling, or adding noise, data augmentation helps the model learn invariant features and generalize better to unseen distributions. Data augmentation can be performed during training and inference to improve the model’s ability to handle distribution shifts.
Ensemble methods combine multiple models to make predictions more robust to distribution shifts. By training models on different subsets of the data, using different algorithms, or with different hyperparameters, ensemble methods can capture diverse aspects of the data distribution. When presented with a shifted distribution, the ensemble can leverage the strengths of individual models to make more accurate and stable predictions. Techniques like bagging, boosting, or stacking can create effective ensembles.
Regularly updating models with new data from the target distribution is crucial to mitigate the impact of distribution shifts. As the data distribution evolves, models should be retrained or fine-tuned on the latest available data to adapt to the changing patterns. Monitoring model performance and data characteristics can help detect when an update is necessary. By keeping the models up to date, practitioners can ensure they remain relevant and accurate in the face of distribution shifts.
Evaluating models using robust metrics less sensitive to distribution shifts can provide a more reliable assessment of model performance. Metrics such as the area under the precision-recall curve (AUPRC) or the F1 score26 are more robust to class imbalance and can better capture the model’s performance across different distributions. Additionally, using domain-specific evaluation metrics that align with the desired outcomes in the target domain can provide a more meaningful measure of the model’s effectiveness.
26 F1 Score: A measure of a model’s accuracy that combines precision (correct positive predictions) and recall (proportion of actual positives identified) into a single metric. Calculated as the harmonic mean of precision and recall.
Detecting and mitigating distribution shifts is an ongoing process that requires continuous monitoring, adaptation, and improvement. By employing a combination of detection techniques and mitigation strategies, ML practitioners can proactively identify and address distribution shifts, ensuring the robustness and reliability of their models in real-world deployments. It is important to note that distribution shifts can take various forms and may require domain-specific approaches depending on the nature of the data and the application. Staying informed about the latest research and best practices in handling distribution shifts is essential for building resilient ML systems.
Software Faults
Machine learning systems rely on complex software infrastructures that extend far beyond the models themselves. These systems are built on top of frameworks, libraries, and runtime environments that facilitate model training, evaluation, and deployment. As with any large-scale software system, the components that support ML workflows are susceptible to faults—unintended behaviors resulting from defects, bugs, or design oversights in the software. These faults can manifest across all stages of an ML pipeline and, if not identified and addressed, may impair performance, compromise security, or even invalidate results. This section examines the nature, causes, and consequences of software faults in ML systems, as well as strategies for their detection and mitigation.
Characteristics
Software faults in ML frameworks originate from various sources, including programming errors, architectural misalignments, and version incompatibilities. These faults exhibit several important characteristics that influence how they arise and propagate in practice.
One defining feature of software faults is their diversity. Faults can range from syntactic and logical errors to more complex manifestations such as memory leaks, concurrency bugs, or failures in integration logic. The broad variety of potential fault types complicates both their identification and resolution, as they often surface in non-obvious ways.
A second key characteristic is their tendency to propagate across system boundaries. An error introduced in a low-level module, such as a tensor allocation routine or a preprocessing function, can produce cascading effects that disrupt model training, inference, or evaluation. Because ML frameworks are often composed of interconnected components, a fault in one part of the pipeline can introduce failures in seemingly unrelated modules.
Some faults are intermittent, manifesting only under specific conditions such as high system load, particular hardware configurations, or rare data inputs. These transient faults are notoriously difficult to reproduce and diagnose, as they may not consistently appear during standard testing procedures.
Furthermore, software faults may subtly interact with ML models themselves. For example, a bug in a data transformation script might introduce systematic noise or shift the distribution of inputs, leading to biased or inaccurate predictions. Similarly, faults in the serving infrastructure may result in discrepancies between training-time and inference-time behaviors, undermining deployment consistency.
The consequences of software faults extend to a range of system properties. Faults may impair performance by introducing latency or inefficient memory usage; they may reduce scalability by limiting parallelism; or they may compromise reliability and security by exposing the system to unexpected behaviors or malicious exploitation.
Finally, the manifestation of software faults is often shaped by external dependencies, such as hardware platforms, operating systems, or third-party libraries. Incompatibilities arising from version mismatches or hardware-specific behavior may result in subtle, hard-to-trace bugs that only appear under certain runtime conditions.
A thorough understanding of these characteristics is essential for developing robust software engineering practices in ML. It also provides the foundation for the detection and mitigation strategies described later in this section.
Mechanisms
Software faults in ML frameworks arise through a variety of mechanisms, reflecting the complexity of modern ML pipelines and the layered architecture of supporting tools. These mechanisms correspond to specific classes of software failures that commonly occur in practice.
One prominent class involves resource mismanagement, particularly with respect to memory. Improper memory allocation, including the failure to release buffers or file handles, can lead to memory leaks and, eventually, to resource exhaustion. This is especially detrimental in deep learning applications, where large tensors and GPU memory allocations are common. As shown in Figure 34, inefficient memory usage or the failure to release GPU resources can cause training procedures to halt or significantly degrade runtime performance.

Another recurring fault mechanism stems from concurrency and synchronization errors. In distributed or multi-threaded environments, incorrect coordination among parallel processes can lead to race conditions, deadlocks, or inconsistent states. These issues are often tied to the improper use of asynchronous operations, such as non-blocking I/O or parallel data ingestion. Synchronization bugs can corrupt the consistency of training states or produce unreliable model checkpoints.
Compatibility problems frequently arise from changes to the software environment. For example, upgrading a third-party library without validating downstream effects may introduce subtle behavioral changes or break existing functionality. These issues are exacerbated when the training and inference environments differ in hardware, operating system, or dependency versions. Reproducibility in ML experiments often hinges on managing these environmental inconsistencies.
Faults related to numerical instability are also common in ML systems, particularly in optimization routines. Improper handling of floating-point precision, division by zero, or underflow/overflow conditions can introduce instability into gradient computations and convergence procedures. As described in this resource, the accumulation of rounding errors across many layers of computation can distort learned parameters or delay convergence.
Exception handling, though often overlooked, plays a crucial role in the stability of ML pipelines. Inadequate or overly generic exception management can cause systems to fail silently or crash under non-critical errors. Moreover, ambiguous error messages and poor logging practices impede diagnosis and prolong resolution times.
These fault mechanisms, while diverse in origin, share the potential to significantly impair ML systems. Understanding how they arise provides the basis for effective system-level safeguards.
Impact on ML
The consequences of software faults can be profound, affecting not only the correctness of model outputs but also the broader usability and reliability of an ML system in production.
Performance degradation is a common symptom, often resulting from memory leaks, inefficient resource scheduling, or contention between concurrent threads. These issues tend to accumulate over time, leading to increased latency, reduced throughput, or even system crashes. As noted by (Maas et al. 2024), the accumulation of performance regressions across components can severely restrict the operational capacity of ML systems deployed at scale.
In addition to slowing system performance, faults can lead to inaccurate predictions. For example, preprocessing errors or inconsistencies in feature encoding can subtly alter the input distribution seen by the model, producing biased or unreliable outputs. These kinds of faults are particularly insidious, as they may not trigger any obvious failure but still compromise downstream decisions. Over time, rounding errors and precision loss can amplify inaccuracies, particularly in deep architectures with many layers or long training durations.
Reliability is also undermined by software faults. Systems may crash unexpectedly, fail to recover from errors, or behave inconsistently across repeated executions. Intermittent faults are especially problematic in this context, as they erode user trust while eluding conventional debugging efforts. In distributed settings, faults in checkpointing or model serialization can cause training interruptions or data loss, reducing the resilience of long-running training pipelines.
Security vulnerabilities frequently arise from overlooked software faults. Buffer overflows, improper validation, or unguarded inputs can open the system to manipulation or unauthorized access. Attackers may exploit these weaknesses to alter the behavior of models, extract private data, or induce denial-of-service conditions. As described by (Q. Li et al. 2023), such vulnerabilities pose serious risks, particularly when ML systems are integrated into critical infrastructure or handle sensitive user data.
Moreover, the presence of faults complicates development and maintenance. Debugging becomes more time-consuming, especially when fault behavior is non-deterministic or dependent on external configurations. Frequent software updates or library patches may introduce regressions that require repeated testing. This increased engineering overhead can slow iteration, inhibit experimentation, and divert resources from model development.
Taken together, these impacts underscore the importance of systematic software engineering practices in ML—practices that anticipate, detect, and mitigate the diverse failure modes introduced by software faults.
Detection and Mitigation
Addressing software faults in ML systems requires an integrated strategy that spans development, testing, deployment, and monitoring. A comprehensive mitigation framework should combine proactive detection methods with robust design patterns and operational safeguards.
To help summarize these techniques and clarify where each strategy fits in the ML lifecycle, Table 4 below categorizes detection and mitigation approaches by phase and objective. This table provides a high-level overview that complements the detailed explanations that follow.
| Category | Technique | Purpose | When to Apply |
|---|---|---|---|
| Testing and Validation | Unit testing, integration testing, regression testing | Verify correctness and identify regressions | During development |
| Static Analysis and Linting | Static analyzers, linters, code reviews | Detect syntax errors, unsafe operations, enforce best practices | Before integration |
| Runtime Monitoring & Logging | Metric collection, error logging, profiling | Observe system behavior, detect anomalies | During training and deployment | | ||
| Fault-Tolerant Design | Exception handling, modular architecture, checkpointing | Minimize impact of failures, support recovery | Design and implementation phase |
| Update Management | Dependency auditing, test staging, version tracking | Prevent regressions and compatibility issues | Before system upgrades or deployment |
| Environment Isolation | Containerization (e.g., Docker, Kubernetes), virtual environments | Ensure reproducibility, avoid environment-specific bugs | Development, testing, deployment |
| CI/CD and Automation | Automated test pipelines, monitoring hooks, deployment gates | Enforce quality assurance and catch faults early | Continuously throughout development |
The first line of defense involves systematic testing. Unit testing verifies that individual components behave as expected under normal and edge-case conditions. Integration testing ensures that modules interact correctly across boundaries, while regression testing detects errors introduced by code changes. Continuous testing is essential in fast-moving ML environments, where pipelines evolve rapidly and small modifications may have system-wide consequences. As shown in Figure 35, automated regression tests help preserve functional correctness over time.
Static code analysis tools complement dynamic tests by identifying potential issues at compile time. These tools catch common errors such as variable misuse, unsafe operations, or violation of language-specific best practices. Combined with code reviews and consistent style enforcement, static analysis reduces the incidence of avoidable programming faults.
Runtime monitoring is critical for observing system behavior under real-world conditions. Logging frameworks should capture key signals such as memory usage, input/output traces, and exception events. Monitoring tools can track model throughput, latency, and failure rates, providing early warnings of software faults. Profiling, as illustrated in this Microsoft resource, helps identify performance bottlenecks and inefficiencies indicative of deeper architectural issues.
Robust system design further improves fault tolerance. Structured exception handling and assertion checks prevent small errors from cascading into system-wide failures. Redundant computations, fallback models, and failover mechanisms improve availability in the presence of component failures. Modular architectures that encapsulate state and isolate side effects make it easier to diagnose and contain faults. Checkpointing techniques, such as those discussed in (Eisenman et al. 2022), enable recovery from mid-training interruptions without data loss.
Keeping ML software up to date is another key strategy. Applying regular updates and security patches helps address known bugs and vulnerabilities. However, updates must be validated through test staging environments to avoid regressions. Reviewing release notes and change logs ensures teams are aware of any behavioral changes introduced in new versions.
Containerization technologies like Docker and Kubernetes allow teams to define reproducible runtime environments that mitigate compatibility issues. By isolating system dependencies, containers prevent faults introduced by system-level discrepancies across development, testing, and production.
Finally, automated pipelines built around continuous integration and continuous deployment (CI/CD) provide an infrastructure for enforcing fault-aware development. Testing, validation, and monitoring can be embedded directly into the CI/CD flow. As shown in Figure 36, such pipelines reduce the risk of unnoticed regressions and ensure only tested code reaches deployment environments.

Together, these practices form a holistic approach to software fault management in ML systems. When adopted comprehensively, they reduce the likelihood of system failures, improve long-term maintainability, and foster trust in model performance and reproducibility.
Tools and Frameworks
Given the importance of developing robust AI systems, in recent years, researchers and practitioners have developed a wide range of tools and frameworks to understand how hardware faults manifest and propagate to impact ML systems. These tools and frameworks play a crucial role in evaluating the resilience of ML systems to hardware faults by simulating various fault scenarios and analyzing their impact on the system’s performance. This enables designers to identify potential vulnerabilities and develop effective mitigation strategies, ultimately creating more robust and reliable ML systems that can operate safely despite hardware faults. This section provides an overview of widely used fault models in the literature and the tools and frameworks developed to evaluate the impact of such faults on ML systems.
Fault and Error Models
As discussed previously, hardware faults can manifest in various ways, including transient, permanent, and intermittent faults. In addition to the type of fault under study, how the fault manifests is also important. For example, does the fault happen in a memory cell or during the computation of a functional unit? Is the impact on a single bit, or does it impact multiple bits? Does the fault propagate all the way and impact the application (causing an error), or does it get masked quickly and is considered benign? All these details impact what is known as the fault model, which plays a major role in simulating and measuring what happens to a system when a fault occurs.
To effectively study and understand the impact of hardware faults on ML systems, it is essential to understand the concepts of fault models and error models. A fault model describes how a hardware fault manifests itself in the system, while an error model represents how the fault propagates and affects the system’s behavior.
Fault models are often classified by several key properties. First, they can be defined by their duration: transient faults are temporary and vanish quickly; permanent faults persist indefinitely; and intermittent faults occur sporadically, making them particularly difficult to identify or predict. Another dimension is fault location, with faults arising in hardware components such as memory cells, functional units, or interconnects. Faults can also be characterized by their granularity—some faults affect only a single bit (e.g., a bitflip), while others impact multiple bits simultaneously, as in burst errors.
Error models, in contrast, describe the behavioral effects of faults as they propagate through the system. These models help researchers understand how initial hardware-level disturbances might manifest in the system’s behavior, such as through corrupted weights or miscomputed activations in an ML model. These models may operate at various abstraction levels, from low-level hardware errors to higher-level logical errors in ML frameworks.
The choice of fault or error model is central to robustness evaluation. For example, a system built to study single-bit transient faults (Sangchoolie, Pattabiraman, and Karlsson 2017) will not offer meaningful insight into the effects of permanent multi-bit faults (Wilkening et al. 2014), since its design and assumptions are grounded in a different fault model entirely.
It’s also important to consider how and where an error model is implemented. A single-bit flip at the architectural register level, modeled using simulators like gem5 (Binkert et al. 2011), differs meaningfully from a similar bit flip in a PyTorch model’s weight tensor. While both simulate value-level perturbations, the lower-level model captures microarchitectural effects that are often abstracted away in software frameworks.
Interestingly, certain fault behavior patterns remain consistent regardless of abstraction level. For example, research has consistently demonstrated that single-bit faults cause more disruption than multi-bit faults, whether examining hardware-level effects or software-visible impacts (Sangchoolie, Pattabiraman, and Karlsson 2017; Papadimitriou and Gizopoulos 2021). However, other important behaviors like error masking (Mohanram and Touba 2003) may only be observable at lower abstraction levels. As illustrated in Figure 37, this masking phenomenon can cause faults to be filtered out before they propagate to higher levels, meaning software-based tools may miss these effects entirely.

To address these discrepancies, tools like Fidelity (He, Balaprakash, and Li 2020) have been developed to align fault models across abstraction layers. By mapping software-observed fault behaviors to corresponding hardware-level patterns (Cheng et al. 2016), Fidelity offers a more accurate means of simulating hardware faults at the software level. While lower-level tools capture the true propagation of errors through a hardware system, they are generally slower and more complex. Software-level tools, such as those implemented in PyTorch or TensorFlow, are faster and easier to use for large-scale robustness testing, albeit with less precision.
Hardware-Based Fault Injection
Hardware-based fault injection methods allow researchers to directly introduce faults into physical systems and observe their effects on machine learning (ML) models. These approaches are essential for validating assumptions made in software-level fault injection tools and for studying how real-world hardware faults influence system behavior. While most error injection tools used in ML robustness research are software-based, because of their speed and scalability, hardware-based approaches remain critical for grounding higher-level error models. They are considered the most accurate means of studying the impact of faults on ML systems by manipulating the hardware directly to introduce errors.
As illustrated in Figure 38, hardware faults can arise at various points within a deep neural network (DNN) processing pipeline. These faults may affect the control unit, on-chip memory (SRAM), off-chip memory (DRAM), processing elements, and accumulators, leading to erroneous results. In the depicted example, a DNN tasked with recognizing traffic signals correctly identifies a red light under normal conditions. However, hardware-induced faults, caused by phenomena such as aging, electromigration, soft errors, process variations, and manufacturing defects, can introduce errors that cause the DNN to misclassify the signal as a green light, potentially leading to catastrophic consequences in real-world applications.
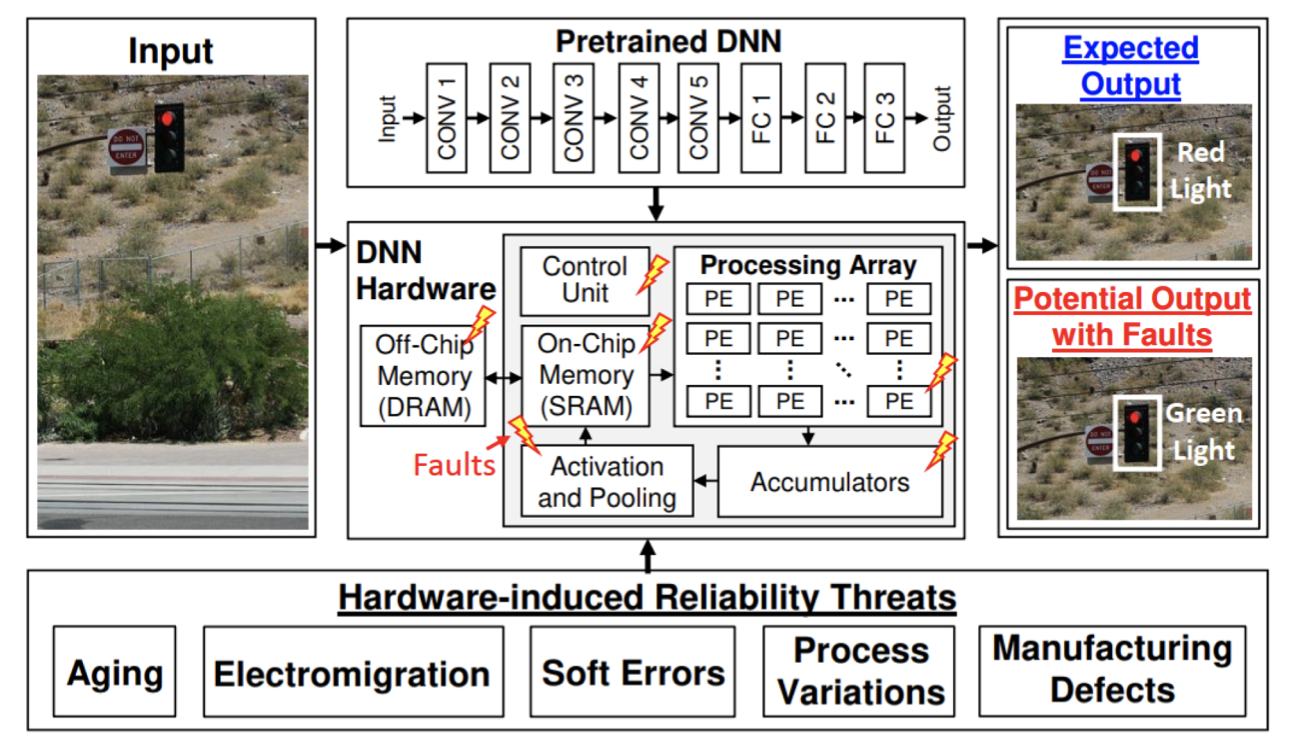
These methods enable researchers to observe the system’s behavior under real-world fault conditions. Both software-based and hardware-based error injection tools are described in this section in more detail.
Methods
Two of the most common hardware-based fault injection methods are FPGA-based fault injection and radiation or beam testing.
FPGA-based Fault Injection. Field-Programmable Gate Arrays (FPGAs) are reconfigurable integrated circuits that can be programmed to implement various hardware designs. In the context of fault injection, FPGAs offer high precision and accuracy, as researchers can target specific bits or sets of bits within the hardware. By modifying the FPGA configuration, faults can be introduced at specific locations and times during the execution of an ML model. FPGA-based fault injection allows for fine-grained control over the fault model, enabling researchers to study the impact of different types of faults, such as single-bit flips or multi-bit errors. This level of control makes FPGA-based fault injection a valuable tool for understanding the resilience of ML systems to hardware faults.
While FPGA-based methods allow precise, controlled fault injection, other approaches aim to replicate fault conditions found in natural environments.
Radiation or Beam Testing. Radiation or beam testing (Velazco, Foucard, and Peronnard 2010) exposes hardware running ML models to high-energy particles like protons or neutrons. As shown in Figure 39, specialized test facilities enable controlled radiation exposure to induce bitflips and other hardware-level faults. This approach is widely regarded as one of the most accurate methods for measuring error rates from particle strikes during application execution. Beam testing provides highly realistic fault scenarios that mirror conditions in radiation-rich environments, making it particularly valuable for validating systems destined for space missions or particle physics experiments. However, while beam testing offers exceptional realism, it lacks the precise targeting capabilities of FPGA-based injection - particle beams cannot be aimed at specific hardware bits or components with high precision. Despite this limitation and its significant operational complexity and cost, beam testing remains a trusted industry practice for rigorously evaluating hardware reliability under real-world radiation effects.

Limitations
Despite their high accuracy, hardware-based fault injection methods have several limitations that can hinder their widespread adoption.
First, cost is a major barrier. Both FPGA-based and beam testing27 approaches require specialized hardware and facilities, which can be expensive to set up and maintain. This makes them less accessible to research groups with limited funding or infrastructure.
27 Beam Testing: A testing method that exposes hardware to controlled particle radiation to evaluate its resilience to soft errors. Common in aerospace, medical devices, and high-reliability computing.
Second, these methods face challenges in scalability. Injecting faults and collecting data directly on hardware is time-consuming, which limits the number of experiments that can be run in a reasonable timeframe. This is especially restrictive when analyzing large ML systems or performing statistical evaluations across many fault scenarios.
Third, there are flexibility limitations. Hardware-based methods may not be as adaptable as software-based alternatives when modeling a wide variety of fault and error types. Changing the experimental setup to accommodate a new fault model often requires time-intensive hardware reconfiguration.
Despite these limitations, hardware-based fault injection remains essential for validating the accuracy of software-based tools and for studying system behavior under real-world fault conditions. By combining the high fidelity of hardware-based methods with the scalability and flexibility of software-based tools, researchers can develop a more complete understanding of ML systems’ resilience to hardware faults and craft effective mitigation strategies.
Software-Based Fault Injection
As machine learning frameworks like TensorFlow, PyTorch, and Keras have become the dominant platforms for developing and deploying ML models, software-based fault injection tools have emerged as a flexible and scalable way to evaluate the robustness of these systems to hardware faults. Unlike hardware-based approaches, which operate directly on physical systems, software-based methods simulate the effects of hardware faults by modifying a model’s underlying computational graph, tensor values, or intermediate computations.
These tools have become increasingly popular in recent years because they integrate directly with ML development pipelines, require no specialized hardware, and allow researchers to conduct large-scale fault injection experiments quickly and cost-effectively. By simulating hardware-level faults, including bit flips in weights, activations, or gradients, at the software level, these tools enable efficient testing of fault tolerance mechanisms and provide valuable insight into model vulnerabilities.
In the remainder of this section, we will examine the advantages and limitations of software-based fault injection methods, introduce major classes of tools (both general-purpose and domain-specific), and discuss how they contribute to building resilient ML systems.
Advantages and Trade-offs
Software-based fault injection tools offer several advantages that make them attractive for studying the resilience of ML systems.
One of the primary benefits is speed. Since these tools operate entirely within the software stack, they avoid the overhead associated with modifying physical hardware or configuring specialized test environments. This efficiency enables researchers to perform a large number of fault injection experiments in significantly less time. The ability to simulate a wide range of faults quickly makes these tools particularly useful for stress-testing large-scale ML models or conducting statistical analyses that require thousands of injections.
Another major advantage is flexibility. Software-based fault injectors can be easily adapted to model various types of faults. Researchers can simulate single-bit flips, multi-bit corruptions, or even more complex behaviors such as burst errors or partial tensor corruption. Additionally, software tools allow faults to be injected at different stages of the ML pipeline, at the stages of training, inference, or gradient computation, enabling precise targeting of different system components or layers.
These tools are also highly accessible, as they require only standard ML development environments. Unlike hardware-based methods, there is no need for costly experimental setups, custom circuitry, or radiation testing facilities. This accessibility opens up fault injection research to a broader range of institutions and developers, including those working in academia, startups, or resource-constrained environments.
However, these advantages come with certain trade-offs. Chief among them is accuracy. Because software-based tools model faults at a higher level of abstraction, they may not fully capture the low-level hardware interactions that influence how faults actually propagate. For example, a simulated bit flip in an ML framework may not account for how data is buffered, cached, or manipulated at the hardware level, potentially leading to oversimplified conclusions.
Closely related is the issue of fidelity. While it is possible to approximate real-world fault behaviors, software-based tools may diverge from true hardware behavior, particularly when it comes to subtle interactions like masking, timing, or data movement. The results of such simulations depend heavily on the underlying assumptions of the error model and may require validation against real hardware measurements to be reliable.
Despite these limitations, software-based fault injection tools play an indispensable role in the study of ML robustness. Their speed, flexibility, and accessibility allow researchers to perform wide-ranging evaluations and inform the development of fault-tolerant ML architectures. In subsequent sections, we explore the major tools in this space, highlighting their capabilities and use cases.
Limitations
While software-based fault injection tools offer significant advantages in terms of speed, flexibility, and accessibility, they are not without limitations. These constraints can impact the accuracy and realism of fault injection experiments, particularly when assessing the robustness of ML systems to real-world hardware faults.
One major concern is accuracy. Because software-based tools operate at higher levels of abstraction, they may not always capture the full spectrum of effects that hardware faults can produce. Low-level hardware interactions, including subtle timing errors, voltage fluctuations, and architectural side effects, can be missed entirely in high-level simulations. As a result, fault injection studies that rely solely on software models may under- or overestimate a system’s true vulnerability to certain classes of faults.
Closely related is the issue of fidelity. While software-based methods are often designed to emulate specific fault behaviors, the extent to which they reflect real-world hardware conditions can vary. For example, simulating a single-bit flip in the value of a neural network weight may not fully replicate how that same bit error would propagate through memory hierarchies or affect computation units on an actual chip. The more abstract the tool, the greater the risk that the simulated behavior will diverge from physical behavior under fault conditions.
Moreover, because software-based tools are easier to modify, there is a risk of unintentionally deviating from realistic fault assumptions. This can occur if the chosen fault model is overly simplified or not grounded in empirical data from actual hardware behavior. As discussed later in the section on bridging the hardware-software gap, tools like Fidelity (He, Balaprakash, and Li 2020) attempt to address these concerns by aligning software-level models with known hardware-level fault characteristics.
Despite these limitations, software-based fault injection remains a critical part of the ML robustness research toolkit. When used appropriately, particularly when used in conjunction with hardware-based validation, these tools provide a scalable and efficient way to explore large design spaces, identify vulnerable components, and develop mitigation strategies. As fault modeling techniques continue to evolve, the integration of hardware-aware insights into software-based tools will be key to improving their realism and impact.
Tool Types
Over the past several years, software-based fault injection tools have been developed for a wide range of ML frameworks and use cases. These tools vary in their level of abstraction, target platforms, and the types of faults they can simulate. Many are built to integrate with popular machine learning libraries such as PyTorch and TensorFlow, making them accessible to researchers and practitioners already working within those ecosystems.
One of the earliest and most influential tools is Ares (Reagen et al. 2018), initially designed for the Keras framework. Developed at a time when deep neural networks (DNNs) were growing in popularity, Ares was one of the first tools to systematically explore the effects of hardware faults on DNNs. It provided support for injecting single-bit flips and evaluating bit-error rates (BER) across weights and activation values. Importantly, Ares was validated against a physical DNN accelerator implemented in silicon, demonstrating its relevance for hardware-level fault modeling. As the field matured, Ares was extended to support PyTorch, allowing researchers to analyze fault behavior in more modern ML settings.
Building on this foundation, PyTorchFI (Mahmoud et al. 2020) was introduced as a dedicated fault injection library for PyTorch. Developed in collaboration with Nvidia Research, PyTorchFI allows fault injection into key components of ML models, including weights, activations, and gradients. Its native support for GPU acceleration makes it especially well-suited for evaluating large models efficiently. As shown in Figure 40, even simple bit-level faults can cause severe visual and classification errors, including the appearance of ‘phantom’ objects in images, which could have downstream safety implications in domains like autonomous driving.

The modular and accessible design of PyTorchFI has led to its adoption in several follow-on projects. For example, PyTorchALFI (developed by Intel xColabs) extends PyTorchFI’s capabilities to evaluate system-level safety in automotive applications. Similarly, Dr. DNA (Ma et al. 2024) from Meta introduces a more streamlined, Pythonic API to simplify fault injection workflows. Another notable extension is GoldenEye (Mahmoud et al. 2022), which incorporates alternative numeric datatypes, including AdaptivFloat (Tambe et al. 2020) and BlockFloat, with bfloat16 as a specific example, to study the fault tolerance of non-traditional number formats under hardware-induced bit errors.
For researchers working within the TensorFlow ecosystem, TensorFI (Chen et al. 2020) provides a parallel solution. Like PyTorchFI, TensorFI enables fault injection into the TensorFlow computational graph and supports a variety of fault models. One of TensorFI’s strengths is its broad applicability—it can be used to evaluate many types of ML models beyond DNNs. Additional extensions such as BinFi (Chen et al. 2019) aim to accelerate the fault injection process by focusing on the most critical bits in a model. This prioritization can help reduce simulation time while still capturing the most meaningful error patterns.
At a lower level of the software stack, NVBitFI (T. Tsai et al. 2021) offers a platform-independent tool for injecting faults directly into GPU assembly code. Developed by Nvidia, NVBitFI is capable of performing fault injection on any GPU-accelerated application, not just ML workloads. This makes it an especially powerful tool for studying resilience at the instruction level, where errors can propagate in subtle and complex ways. NVBitFI represents an important complement to higher-level tools like PyTorchFI and TensorFI, offering fine-grained control over GPU-level behavior and supporting a broader class of applications beyond machine learning.
Together, these tools offer a wide spectrum of fault injection capabilities. While some are tightly integrated with high-level ML frameworks for ease of use, others enable lower-level fault modeling with higher fidelity. By choosing the appropriate tool based on the level of abstraction, performance needs, and target application, researchers can tailor their studies to gain more actionable insights into the robustness of ML systems. The next section focuses on how these tools are being applied in domain-specific contexts, particularly in safety-critical systems such as autonomous vehicles and robotics.
Domain-Specific Examples
To address the unique challenges posed by specific application domains, researchers have developed specialized fault injection tools tailored to different machine learning (ML) systems. In high-stakes environments such as autonomous vehicles and robotics, domain-specific tools play a crucial role in evaluating system safety and reliability under hardware fault conditions. This section highlights three such tools: DriveFI and PyTorchALFI, which focus on autonomous vehicles, and MAVFI, which targets uncrewed aerial vehicles (UAVs). Each tool enables the injection of faults into mission-critical components, including perception, control, and sensor systems, providing researchers with insights into how hardware errors may propagate through real-world ML pipelines.
DriveFI (Jha et al. 2019) is a fault injection tool developed for autonomous vehicle systems. It facilitates the injection of hardware faults into the perception and control pipelines, enabling researchers to study how such faults affect system behavior and safety. Notably, DriveFI integrates with industry-standard platforms like Nvidia DriveAV and Baidu Apollo, offering a realistic environment for testing. Through this integration, DriveFI enables practitioners to evaluate the end-to-end resilience of autonomous vehicle architectures in the presence of fault conditions.
28 Multimodal Sensor Data: Information collected simultaneously from multiple types of sensors (e.g., cameras, LiDAR, radar) to provide complementary perspectives of the environment. Critical for robust perception in autonomous systems.
PyTorchALFI (Gräfe et al. 2023) extends the capabilities of PyTorchFI for use in the autonomous vehicle domain. Developed by Intel xColabs, PyTorchALFI enhances the underlying fault injection framework with domain-specific features. These include the ability to inject faults into multimodal sensor data28, such as inputs from cameras and LiDAR systems. This allows for a deeper examination of how perception systems in autonomous vehicles respond to underlying hardware faults, further refining our understanding of system vulnerabilities and potential failure modes.
MAVFI (Hsiao et al. 2023) is a domain-specific fault injection framework tailored for robotics applications, particularly uncrewed aerial vehicles. Built atop the Robot Operating System (ROS), MAVFI provides a modular and extensible platform for injecting faults into various UAV subsystems, including sensors, actuators, and flight control algorithms. By assessing how injected faults impact flight stability and mission success, MAVFI offers a practical means for developing and validating fault-tolerant UAV architectures.
Together, these tools demonstrate the growing sophistication of fault injection research across application domains. By enabling fine-grained control over where and how faults are introduced, domain-specific tools provide actionable insights that general-purpose frameworks may overlook. Their development has greatly expanded the ML community’s capacity to design and evaluate resilient systems—particularly in contexts where reliability, safety, and real-time performance are critical.
Bridging Hardware-Software Gap
While software-based fault injection tools offer many advantages in speed, flexibility, and accessibility, they do not always capture the full range of effects that hardware faults can impose on a system. This is largely due to the abstraction gap: software-based tools operate at a higher level and may overlook low-level hardware interactions or nuanced error propagation mechanisms that influence the behavior of ML systems in critical ways.
As discussed in the work by (Bolchini et al. 2023), hardware faults can exhibit complex spatial distribution patterns that are difficult to replicate using purely software-based fault models. They identify four characteristic fault propagation patterns: single point, where the fault corrupts a single value in a feature map; same row, where a partial or entire row in a feature map is corrupted; bullet wake, where the same location across multiple feature maps is affected; and shatter glass, a more complex combination of both same row and bullet wake behaviors. These diverse patterns, visualized in Figure 41, highlight the limits of simplistic injection strategies and emphasize the need for hardware-aware modeling when evaluating ML system robustness.

To address this abstraction gap, researchers have developed tools that explicitly aim to map low-level hardware error behavior to software-visible effects. One such tool is Fidelity, which bridges this gap by studying how hardware-level faults propagate and become observable at higher software layers. The next section discusses Fidelity in more detail.
Fidelity
Fidelity (He, Balaprakash, and Li 2020) is a tool designed to model hardware faults more accurately within software-based fault injection experiments. Its core goal is to bridge the gap between low-level hardware fault behavior and the higher-level effects observed in machine learning systems by simulating how faults propagate through the compute stack.
The central insight behind Fidelity is that not all faults need to be modeled individually at the hardware level to yield meaningful results. Instead, Fidelity focuses on how faults manifest at the software-visible state and identifies equivalence relationships that allow representative modeling of entire fault classes. To accomplish this, it relies on several key principles:
First, fault propagation is studied to understand how a fault originating in hardware can move through various layers, including architectural registers, memory hierarchies, and numerical operations, eventually altering values in software. Fidelity captures these pathways to ensure that injected faults in software reflect the way faults would actually manifest in a real system.
Second, the tool identifies fault equivalence, which refers to grouping hardware faults that lead to similar observable outcomes in software. By focusing on representative examples rather than modeling every possible hardware bit flip individually, Fidelity allows more efficient simulations without sacrificing accuracy.
Finally, Fidelity uses a layered modeling approach, capturing the system’s behavior at various abstraction levels—from hardware fault origin to its effect in the ML model’s weights, activations, or predictions. This layering ensures that the impact of hardware faults is realistically simulated in the context of the ML system.
By combining these techniques, Fidelity allows researchers to run fault injection experiments that closely mirror the behavior of real hardware systems, but with the efficiency and flexibility of software-based tools. This makes Fidelity especially valuable in safety-critical settings, where the cost of failure is high and an accurate understanding of hardware-induced faults is essential.
Capturing Hardware Behavior
Capturing the true behavior of hardware faults in software-based fault injection tools is critical for advancing the reliability and robustness of ML systems. This fidelity becomes especially important when hardware faults have subtle but significant effects that may not be evident when modeled at a high level of abstraction.
There are several reasons why accurately reflecting hardware behavior is essential. First, accuracy is paramount. Software-based tools that mirror the actual propagation and manifestation of hardware faults provide more dependable insights into how faults influence model behavior. These insights are crucial for designing and validating fault-tolerant architectures and ensuring that mitigation strategies are grounded in realistic system behavior.
Second, reproducibility is improved when hardware effects are faithfully captured. This allows fault injection results to be reliably reproduced across different systems and environments, which is a cornerstone of rigorous scientific research. Researchers can better compare results, validate findings, and ensure consistency across studies.
Third, efficiency is enhanced when fault models focus on the most representative and impactful fault scenarios. Rather than exhaustively simulating every possible bit flip, tools can target a subset of faults that are known, by means of accurate modeling, to affect the system in meaningful ways. This selective approach saves computational resources while still providing comprehensive insights.
Finally, understanding how hardware faults appear at the software level is essential for designing effective mitigation strategies. When researchers know how specific hardware-level issues affect different components of an ML system, they can develop more targeted hardening techniques—such as retraining specific layers, applying redundancy selectively, or improving architectural resilience in bottleneck components.
Tools like Fidelity are central to this effort. By establishing mappings between low-level hardware behavior and higher-level software effects, Fidelity and similar tools empower researchers to conduct fault injection experiments that are not only faster and more scalable, but also grounded in real-world system behavior.
As ML systems continue to increase in scale and are deployed in increasingly safety-critical environments, this kind of hardware-aware modeling will become even more important. Ongoing research in this space aims to further refine the translation between hardware and software fault models and to develop tools that offer both efficiency and realism in evaluating ML system resilience. These advances will provide the community with more powerful, reliable methods for understanding and defending against the effects of hardware faults.
Summary
The pursuit of robust AI is a multifaceted endeavor that is critical for the reliable deployment of machine learning systems in real-world environments. As ML move from controlled research settings to practical applications, robustness becomes not just a desirable feature but a foundational requirement. Deploying AI in practice means engaging directly with the challenges that can compromise system performance, safety, and reliability.
We examined the broad spectrum of issues that threaten AI robustness, beginning with hardware-level faults. Transient faults may introduce temporary computational errors, while permanent faults, including the well-known Intel FDIV bug, can lead to persistent inaccuracies that affect system behavior over time.
Beyond hardware, machine learning models themselves are susceptible to a variety of threats. Adversarial examples, such as the misclassification of modified stop signs, reveal how subtle input manipulations can cause erroneous outputs. Likewise, data poisoning techniques, exemplified by the Nightshade project, illustrate how malicious training data can degrade model performance or implant hidden backdoors, posing serious security risks in practical deployments.
The chapter also addressed the impact of distribution shifts, which often result from temporal evolution or domain mismatches between training and deployment environments. Such shifts challenge a model’s ability to generalize and perform reliably under changing conditions. Compounding these issues are faults in the software infrastructure, including frameworks, libraries, and runtime components, which can propagate unpredictably and undermine system integrity.
To navigate these risks, the use of robust tools and evaluation frameworks is essential. Tools such as PyTorchFI and Fidelity enable researchers and practitioners to simulate fault scenarios, assess vulnerabilities, and systematically improve system resilience. These resources are critical for translating theoretical robustness principles into operational safeguards.
Ultimately, building robust AI requires a comprehensive and proactive approach. Fault tolerance, security mechanisms, and continuous monitoring must be embedded throughout the AI development lifecycle—from data collection and model training to deployment and maintenance. As this chapter has demonstrated, applying AI in real-world contexts means addressing these robustness challenges head-on to ensure that systems operate safely, reliably, and effectively in complex and evolving environments.