5 Data Engineering
Resources: Slides, Videos, Exercises, Labs

Data is the lifeblood of AI systems. Without good data, even the most advanced machine-learning algorithms will not succeed. However, TinyML models operate on devices with limited processing power and memory. This section explores the intricacies of building high-quality datasets to fuel our AI models. Data engineering involves collecting, storing, processing, and managing data to train machine learning models.
Understand the importance of clearly defining the problem statement and objectives when embarking on an ML project.
Recognize various data sourcing techniques, such as web scraping, crowdsourcing, and synthetic data generation, along with their advantages and limitations.
Appreciate the need for thoughtful data labeling, using manual or AI-assisted approaches, to create high-quality training datasets.
Briefly learn different methods for storing and managing data, such as databases, data warehouses, and data lakes.
Comprehend the role of transparency through metadata and dataset documentation and tracking data provenance to facilitate ethics, auditing, and reproducibility.
Understand how licensing protocols govern legal data access and usage, necessitating careful compliance.
Recognize key challenges in data engineering, including privacy risks, representation gaps, legal restrictions around data access, and balancing competing priorities.
5.1 Introduction
Imagine a world where AI can diagnose diseases with unprecedented accuracy, but only if the data used to train it is unbiased and reliable. This is where data engineering comes in. While over 90% of the world’s data has been created in the past two decades, this vast amount of information is only helpful for building effective AI models with proper processing and preparation. Data engineering bridges this gap by transforming raw data into a high-quality format that fuels AI innovation. In today’s data-driven world, protecting user privacy is paramount. Whether mandated by law or driven by user concerns, anonymization techniques like differential privacy and aggregation are vital in mitigating privacy risks. However, careful implementation is crucial to ensure these methods don’t compromise data utility. Dataset creators face complex privacy and representation challenges when building high-quality training data, especially for sensitive domains like healthcare. Legally, creators may need to remove direct identifiers like names and ages. Even without legal obligations, removing such information can help build user trust. However, excessive anonymization can compromise dataset utility. Techniques like differential privacy\(^{1}\), aggregation, and reducing detail provide alternatives to balance privacy and utility but have downsides. Creators must strike a thoughtful balance based on the use case.
While privacy is paramount, ensuring fair and robust AI models requires addressing representation gaps in the data. It is crucial yet insufficient to ensure diversity across individual variables like gender, race, and accent. These combinations, sometimes called higher-order gaps, can significantly impact model performance. For example, a medical dataset could have balanced gender, age, and diagnosis data individually, but it lacks enough cases to capture older women with a specific condition. Such higher-order gaps are not immediately obvious but can critically impact model performance.
Creating useful, ethical training data requires holistic consideration of privacy risks and representation gaps. Elusive perfect solutions necessitate conscientious data engineering practices like anonymization, aggregation, under-sampling of overrepresented groups, and synthesized data generation to balance competing needs. This facilitates models that are both accurate and socially responsible. Cross-functional collaboration and external audits can also strengthen training data. The challenges are multifaceted but surmountable with thoughtful effort.
We begin by discussing data collection: Where do we source data, and how do we gather it? Options range from scraping the web, accessing APIs, and utilizing sensors and IoT devices to conducting surveys and gathering user input. These methods reflect real-world practices. Next, we dive into data labeling, including considerations for human involvement. We’ll discuss the trade-offs and limitations of human labeling and explore emerging methods for automated labeling. Following that, we’ll address data cleaning and preprocessing, a crucial yet frequently undervalued step in preparing raw data for AI model training. Data augmentation comes next, a strategy for enhancing limited datasets by generating synthetic samples. This is particularly pertinent for embedded systems, as many use cases need extensive data repositories readily available for curation. Synthetic data generation emerges as a viable alternative with advantages and disadvantages. We’ll also touch upon dataset versioning, emphasizing the importance of tracking data modifications over time. Data is ever-evolving; hence, it’s imperative to devise strategies for managing and storing expansive datasets. By the end of this section, you’ll possess a comprehensive understanding of the entire data pipeline, from collection to storage, essential for operationalizing AI systems. Let’s embark on this journey!
5.2 Problem Definition
In many machine learning domains, sophisticated algorithms take center stage, while the fundamental importance of data quality is often overlooked. This neglect gives rise to “Data Cascades” by Sambasivan et al. (2021) (see Figure 5.1)—events where lapses in data quality compound, leading to negative downstream consequences such as flawed predictions, project terminations, and even potential harm to communities. In Figure 5.1, we have an illustration of potential data pitfalls at every stage and how they influence the entire process down the line. The influence of data collection errors is especially pronounced. Any lapses in this stage will become apparent at later stages (in model evaluation and deployment) and might lead to costly consequences, such as abandoning the entire model and restarting anew. Therefore, investing in data engineering techniques from the onset will help us detect errors early.
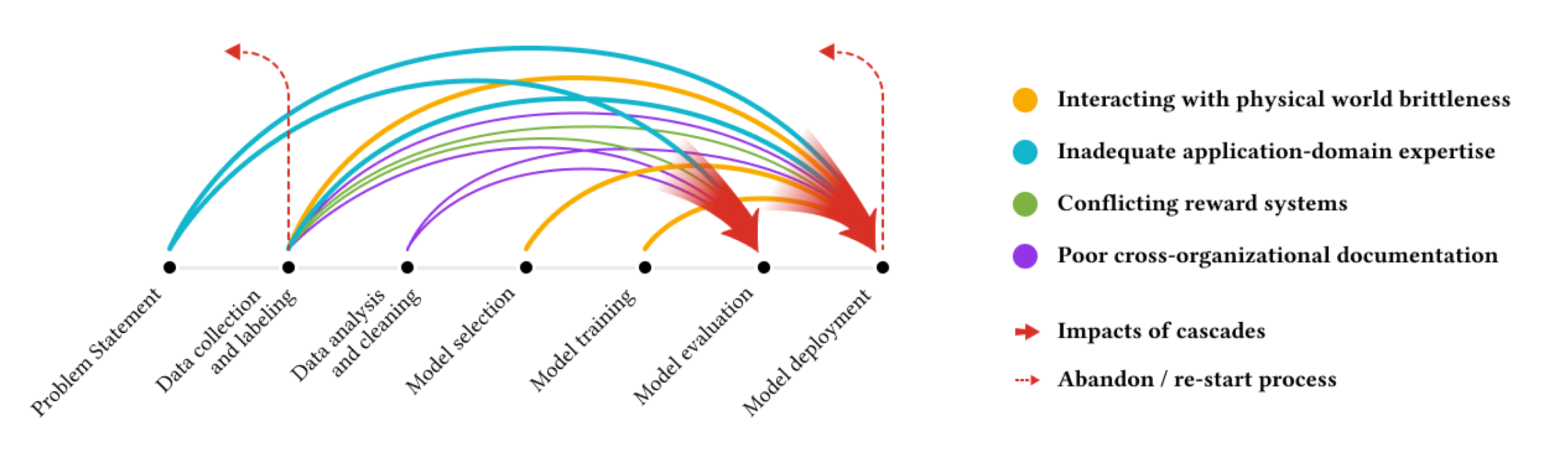
Despite many ML professionals recognizing the importance of data, numerous practitioners report facing these cascades. This highlights a systemic issue: while the allure of developing advanced models remains, data often needs to be more appreciated.
Take, for example, Keyword Spotting (KWS) (see Figure 5.2). KWS is a prime example of TinyML in action and is a critical technology behind voice-enabled interfaces on endpoint devices such as smartphones. Typically functioning as lightweight wake-word engines, these systems are consistently active, listening for a specific phrase to trigger further actions. When we say “OK, Google” or “Alexa,” this initiates a process on a microcontroller embedded within the device. Despite their limited resources, these microcontrollers play an important role in enabling seamless voice interactions with devices, often operating in environments with high ambient noise. The uniqueness of the wake word helps minimize false positives, ensuring that the system is not triggered inadvertently.
It is important to appreciate that these keyword-spotting technologies are not isolated; they integrate seamlessly into larger systems, processing signals continuously while managing low power consumption. These systems extend beyond simple keyword recognition, evolving to facilitate diverse sound detections, such as glass breaking. This evolution is geared towards creating intelligent devices capable of understanding and responding to vocal commands, heralding a future where even household appliances can be controlled through voice interactions.

Building a reliable KWS model is a complex task. It demands a deep understanding of the deployment scenario, encompassing where and how these devices will operate. For instance, a KWS model’s effectiveness is not just about recognizing a word; it’s about discerning it among various accents and background noises, whether in a bustling cafe or amid the blaring sound of a television in a living room or a kitchen where these devices are commonly found. It’s about ensuring that a whispered “Alexa” in the dead of night or a shouted “OK Google” in a noisy marketplace are recognized with equal precision.
Moreover, many current KWS voice assistants support a limited number of languages, leaving a substantial portion of the world’s linguistic diversity unrepresented. This limitation is partly due to the difficulty in gathering and monetizing data for languages spoken by smaller populations. The long-tail distribution of languages implies that many languages have limited data, making the development of supportive technologies challenging.
This level of accuracy and robustness hinges on the availability and quality of data, the ability to label the data correctly, and the transparency of the data for the end user before it is used to train the model. However, it all begins with clearly understanding the problem statement or definition.
Generally, in ML, problem definition has a few key steps:
Identifying the problem definition clearly
Setting clear objectives
Establishing success benchmark
Understanding end-user engagement/use
Understanding the constraints and limitations of deployment
Followed by finally doing the data collection.
A solid project foundation is essential for its trajectory and eventual success. Central to this foundation is first identifying a clear problem, such as ensuring that voice commands in voice assistance systems are recognized consistently across varying environments. Clear objectives, like creating representative datasets for diverse scenarios, provide a unified direction. Benchmarks, such as system accuracy in keyword detection, offer measurable outcomes to gauge progress. Engaging with stakeholders, from end-users to investors, provides invaluable insights and ensures alignment with market needs. Additionally, understanding platform constraints is important when exploring areas like voice assistance. Embedded systems, such as microcontrollers, come with inherent processing power, memory, and energy efficiency limitations. Recognizing these limitations ensures that functionalities, like keyword detection, are tailored to operate optimally, balancing performance with resource conservation.
In this context, using KWS as an example, we can break each of the steps out as follows:
Identifying the Problem: At its core, KWS detects specific keywords amidst ambient sounds and other spoken words. The primary problem is to design a system that can recognize these keywords with high accuracy, low latency, and minimal false positives or negatives, especially when deployed on devices with limited computational resources.
Setting Clear Objectives: The objectives for a KWS system might include:
- Achieving a specific accuracy rate (e.g., 98% accuracy in keyword detection).
- Ensuring low latency (e.g., keyword detection and response within 200 milliseconds).
- Minimizing power consumption to extend battery life on embedded devices.
- Ensuring the model’s size is optimized for the available memory on the device.
Benchmarks for Success: Establish clear metrics to measure the success of the KWS system. This could include:
- True Positive Rate: The percentage of correctly identified keywords.
- False Positive Rate: The percentage of non-keywords incorrectly identified as keywords.
- Response Time: The time taken from keyword utterance to system response.
- Power Consumption: Average power used during keyword detection.
Stakeholder Engagement and Understanding: Engage with stakeholders, which include device manufacturers, hardware and software developers, and end-users. Understand their needs, capabilities, and constraints. For instance:
- Device manufacturers might prioritize low power consumption.
- Software developers might emphasize ease of integration.
- End-users would prioritize accuracy and responsiveness.
Understanding the Constraints and Limitations of Embedded Systems: Embedded devices come with their own set of challenges:
- Memory Limitations: KWS models must be lightweight to fit within the memory constraints of embedded devices. Typically, KWS models need to be as small as 16KB to fit in the always-on island of the SoC. Moreover, this is just the model size. Additional application code for preprocessing may also need to fit within the memory constraints.
- Processing Power: The computational capabilities of embedded devices are limited (a few hundred MHz of clock speed), so the KWS model must be optimized for efficiency.
- Power Consumption: Since many embedded devices are battery-powered, the KWS system must be power-efficient.
- Environmental Challenges: Devices might be deployed in various environments, from quiet bedrooms to noisy industrial settings. The KWS system must be robust enough to function effectively across these scenarios.
Data Collection and Analysis: For a KWS system, the quality and diversity of data are paramount. Considerations might include:
- Variety of Accents: Collect data from speakers with various accents to ensure wide-ranging recognition.
- Background Noises: Include data samples with different ambient noises to train the model for real-world scenarios.
- Keyword Variations: People might either pronounce keywords differently or have slight variations in the wake word itself. Ensure the dataset captures these nuances.
Iterative Feedback and Refinement: Once a prototype KWS system is developed, it’s crucial to test it in real-world scenarios, gather feedback, and iteratively refine the model. This ensures that the system remains aligned with the defined problem and objectives. This is important because the deployment scenarios change over time as things evolve.
Explore a hands-on guide for building and deploying Keyword Spotting (KWS) systems using TensorFlow Lite Micro. Follow steps from data collection to model training and deployment to microcontrollers. Learn to create efficient KWS models that recognize specific keywords amidst background noise. Perfect for those interested in machine learning on embedded systems. Unlock the potential of voice-enabled devices with TensorFlow Lite Micro!
![]()
The current chapter underscores the essential role of data quality in ML, using Keyword Spotting (KWS) systems as an example. It outlines key steps, from problem definition to stakeholder engagement, emphasizing iterative feedback. The forthcoming chapter will dig deeper into data quality management, discussing its consequences and future trends, focusing on the importance of high-quality, diverse data in AI system development, addressing ethical considerations and data sourcing methods.
5.3 Data Sourcing
The quality and diversity of data gathered are important for developing accurate and robust AI systems. Sourcing high-quality training data requires careful consideration of the objectives, resources, and ethical implications. Data can be obtained from various sources depending on the needs of the project:
5.3.1 Pre-existing datasets
Platforms like Kaggle and UCI Machine Learning Repository provide a convenient starting point. Pre-existing datasets are valuable for researchers, developers, and businesses. One of their primary advantages is cost efficiency. Creating a dataset from scratch can be time-consuming and expensive, so accessing ready-made data can save significant resources. Moreover, many datasets, like ImageNet, have become standard benchmarks in the machine learning community, allowing for consistent performance comparisons across different models and algorithms. This data availability means that experiments can be started immediately without any data collection and preprocessing delays. In a fast-moving field like ML, this practicality is important.
The quality assurance that comes with popular pre-existing datasets is important to consider because several datasets have errors in them. For instance, the ImageNet dataset was found to have over 6.4% errors. Given their widespread use, the community often identifies and rectifies any errors or biases in these datasets. This assurance is especially beneficial for students and newcomers to the field, as they can focus on learning and experimentation without worrying about data integrity. Supporting documentation often accompanying existing datasets is invaluable, though this generally applies only to widely used datasets. Good documentation provides insights into the data collection process and variable definitions and sometimes even offers baseline model performances. This information not only aids understanding but also promotes reproducibility in research, a cornerstone of scientific integrity; currently, there is a crisis around improving reproducibility in machine learning systems. When other researchers have access to the same data, they can validate findings, test new hypotheses, or apply different methodologies, thus allowing us to build on each other’s work more rapidly.
While platforms like Kaggle and UCI Machine Learning Repository are invaluable resources, it’s essential to understand the context in which the data was collected. Researchers should be wary of potential overfitting when using popular datasets, as multiple models might have been trained on them, leading to inflated performance metrics. Sometimes, these datasets do not reflect the real-world data.
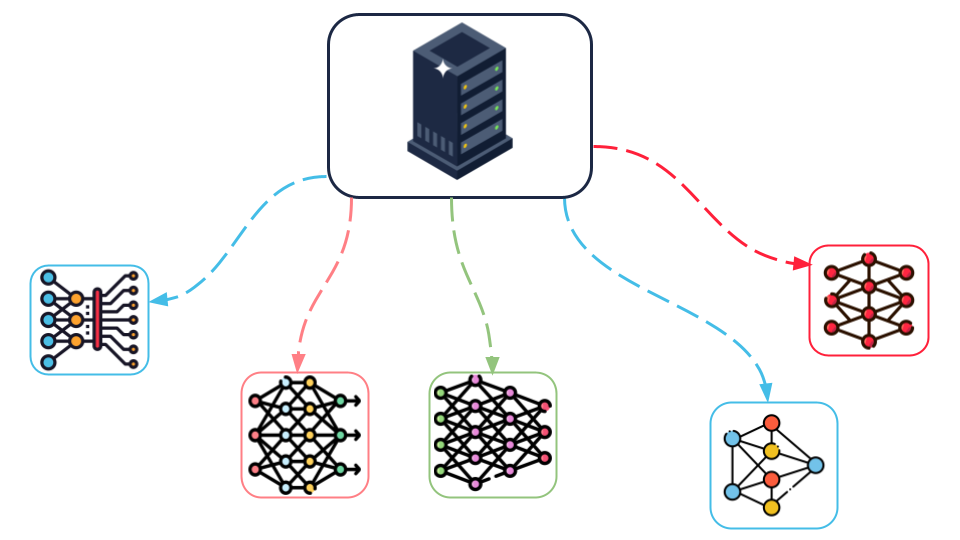
In addition, bias, validity, and reproducibility issues may exist in these datasets, and there has been a growing awareness of these issues in recent years. Furthermore, using the same dataset to train different models as shown in Figure 5.3 can sometimes create misalignment: training multiple models using the same dataset results in a ‘misalignment’ between the models and the world, in which an entire ecosystem of models reflects only a narrow subset of the real-world data.
5.3.2 Web Scraping
Web scraping refers to automated techniques for extracting data from websites. It typically involves sending HTTP requests to web servers, retrieving HTML content, and parsing that content to extract relevant information. Popular tools and frameworks for web scraping include Beautiful Soup, Scrapy, and Selenium. These tools offer different functionalities, from parsing HTML content to automating web browser interactions, especially for websites that load content dynamically using JavaScript.
Web scraping can effectively gather large datasets for training machine learning models, particularly when human-labeled data is scarce. For computer vision research, web scraping enables the collection of massive volumes of images and videos. Researchers have used this technique to build influential datasets like ImageNet and OpenImages. For example, one could scrape e-commerce sites to amass product photos for object recognition or social media platforms to collect user uploads for facial analysis. Even before ImageNet, Stanford’s LabelMe project scraped Flickr for over 63,000 annotated images covering hundreds of object categories.
Beyond computer vision, web scraping supports gathering textual data for natural language tasks. Researchers can scrape news sites for sentiment analysis data, forums and review sites for dialogue systems research, or social media for topic modeling. For example, the training data for chatbot ChatGPT was obtained by scraping much of the public Internet. GitHub repositories were scraped to train GitHub’s Copilot AI coding assistant.
Web scraping can also collect structured data, such as stock prices, weather data, or product information, for analytical applications. Once data is scraped, it is essential to store it in a structured manner, often using databases or data warehouses. Proper data management ensures the usability of the scraped data for future analysis and applications.
However, while web scraping offers numerous advantages, there are significant limitations and ethical considerations to bear. Not all websites permit scraping, and violating these restrictions can lead to legal repercussions. Scraping copyrighted material or private communications is also unethical and potentially illegal. Ethical web scraping mandates adherence to a website’s ‘robots.txt’ file, which outlines the sections of the site that can be accessed and scraped by automated bots.
To deter automated scraping, many websites implement rate limits. If a bot sends too many requests in a short period, it might be temporarily blocked, restricting the speed of data access. Additionally, the dynamic nature of web content means that data scraped at different intervals might need more consistency, posing challenges for longitudinal studies. However, there are emerging trends like Web Navigation where machine learning algorithms can automatically navigate the website to access the dynamic content.
The volume of pertinent data available for scraping might be limited for niche subjects. For example, while scraping for common topics like images of cats and dogs might yield abundant data, searching for rare medical conditions might be less fruitful. Moreover, the data obtained through scraping is often unstructured and noisy, necessitating thorough preprocessing and cleaning. It is crucial to understand that not all scraped data will be of high quality or accuracy. Employing verification methods, such as cross-referencing with alternate data sources, can improve data reliability.
Privacy concerns arise when scraping personal data, emphasizing the need for anonymization. Therefore, it is paramount to adhere to a website’s Terms of Service, confine data collection to public domains, and ensure the anonymity of any personal data acquired.
While web scraping can be a scalable method to amass large training datasets for AI systems, its applicability is confined to specific data types. For example, web scraping makes sourcing data for Inertial Measurement Units (IMU) for gesture recognition more complex. At most, one can scrape an existing dataset.
Web scraping can yield inconsistent or inaccurate data. For example, the photo in Figure 5.4 shows up when you search for ‘traffic light’ on Google Images. It is an image from 1914 that shows outdated traffic lights, which are also barely discernible because of the image’s poor quality. This can be problematic for web-scraped datasets, as it pollutes the dataset with inapplicable (old) data samples.

Discover the power of web scraping with Python using libraries like Beautiful Soup and Pandas. This exercise will scrape Python documentation for function names and descriptions and explore NBA player stats. By the end, you’ll have the skills to extract and analyze data from real-world websites. Ready to dive in? Access the Google Colab notebook below and start practicing!
![]()
5.3.3 Crowdsourcing
Crowdsourcing for datasets is the practice of obtaining data using the services of many people, either from a specific community or the general public, typically via the Internet. Instead of relying on a small team or specific organization to collect or label data, crowdsourcing leverages the collective effort of a vast, distributed group of participants. Services like Amazon Mechanical Turk enable the distribution of annotation tasks to a large, diverse workforce. This facilitates the collection of labels for complex tasks like sentiment analysis or image recognition requiring human judgment.
Crowdsourcing has emerged as an effective approach for data collection and problem-solving. One major advantage of crowdsourcing is scalability—by distributing tasks to a large, global pool of contributors on digital platforms, projects can process huge volumes of data quickly. This makes crowdsourcing ideal for large-scale data labeling, collection, and analysis.
In addition, crowdsourcing taps into a diverse group of participants, bringing a wide range of perspectives, cultural insights, and language abilities that can enrich data and enhance creative problem-solving in ways that a more homogenous group may not. Because crowdsourcing draws from a large audience beyond traditional channels, it is more cost-effective than conventional methods, especially for simpler microtasks.
Crowdsourcing platforms also allow for great flexibility, as task parameters can be adjusted in real time based on initial results. This creates a feedback loop for iterative improvements to the data collection process. Complex jobs can be broken down into microtasks and distributed to multiple people, with results cross-validated by assigning redundant versions of the same task. When thoughtfully managed, crowdsourcing enables community engagement around a collaborative project, where participants find reward in contributing.
However, while crowdsourcing offers numerous advantages, it’s essential to approach it with a clear strategy. While it provides access to a diverse set of annotators, it also introduces variability in the quality of annotations. Additionally, platforms like Mechanical Turk might not always capture a complete demographic spectrum; often, tech-savvy individuals are overrepresented, while children and older people may be underrepresented. Providing clear instructions and training for the annotators is crucial. Periodic checks and validations of the labeled data help maintain quality. This ties back to the topic of clear Problem Definition that we discussed earlier. Crowdsourcing for datasets also requires careful attention to ethical considerations. It’s crucial to ensure that participants are informed about how their data will be used and that their privacy is protected. Quality control through detailed protocols, transparency in sourcing, and auditing is essential to ensure reliable outcomes.
For TinyML, crowdsourcing can pose some unique challenges. TinyML devices are highly specialized for particular tasks within tight constraints. As a result, the data they require tends to be very specific. Obtaining such specialized data from a general audience may be difficult through crowdsourcing. For example, TinyML applications often rely on data collected from certain sensors or hardware. Crowdsourcing would require participants to have access to very specific and consistent devices - like microphones, with the same sampling rates. These hardware nuances present obstacles even for simple audio tasks like keyword spotting.
Beyond hardware, the data itself needs high granularity and quality, given the limitations of TinyML. It can be hard to ensure this when crowdsourcing from those unfamiliar with the application’s context and requirements. There are also potential issues around privacy, real-time collection, standardization, and technical expertise. Moreover, the narrow nature of many TinyML tasks makes accurate data labeling easier with the proper understanding. Participants may need full context to provide reliable annotations.
Thus, while crowdsourcing can work well in many cases, the specialized needs of TinyML introduce unique data challenges. Careful planning is required for guidelines, targeting, and quality control. For some applications, crowdsourcing may be feasible, but others may require more focused data collection efforts to obtain relevant, high-quality training data.
5.3.4 Synthetic Data
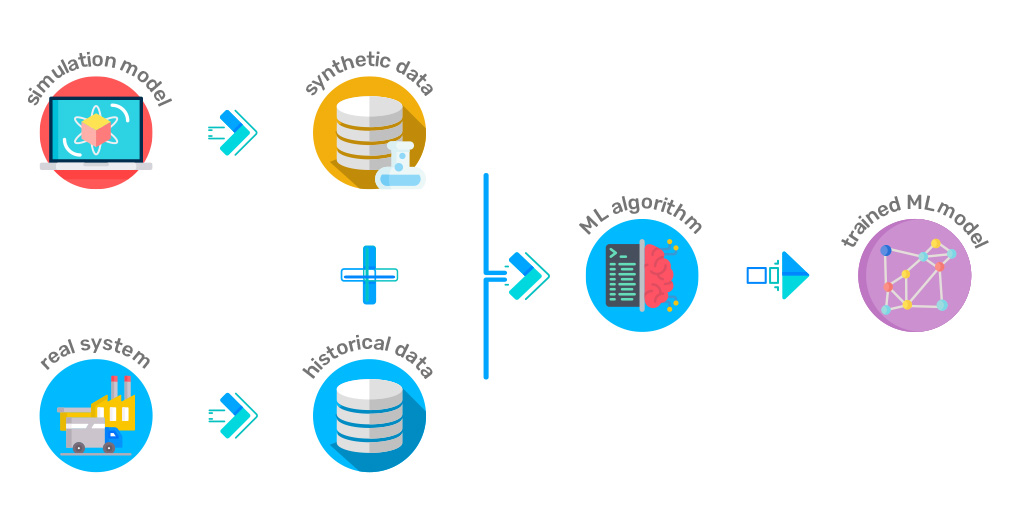
Synthetic data generation can be useful for addressing some of the data collection limitations. It involves creating data that wasn’t originally captured or observed but is generated using algorithms, simulations, or other techniques to resemble real-world data. As shown in Figure 5.5, synthetic data is merged with historical data and then used as input for model training. It has become a valuable tool in various fields, particularly when real-world data is scarce, expensive, or ethically challenging (e.g., TinyML). Various techniques, such as Generative Adversarial Networks (GANs), can produce high-quality synthetic data almost indistinguishable from real data. These techniques have advanced significantly, making synthetic data generation increasingly realistic and reliable.
More real-world data may need to be available for analysis or training machine learning models in many domains, especially emerging ones. Synthetic data can fill this gap by producing large volumes of data that mimic real-world scenarios. For instance, detecting the sound of breaking glass might be challenging in security applications where a TinyML device is trying to identify break-ins. Collecting real-world data would require breaking numerous windows, which is impractical and costly.
Moreover, having a diverse dataset is crucial in machine learning, especially in deep learning. Synthetic data can augment existing datasets by introducing variations, thereby enhancing the robustness of models. For example, SpecAugment is an excellent data augmentation technique for Automatic Speech Recognition (ASR) systems.
Privacy and confidentiality are also big issues. Datasets containing sensitive or personal information pose privacy concerns when shared or used. Synthetic data, being artificially generated, doesn’t have these direct ties to real individuals, allowing for safer use while preserving essential statistical properties.
Generating synthetic data, especially once the generation mechanisms have been established, can be a more cost-effective alternative. Synthetic data eliminates the need to break multiple windows to gather relevant data in the security above application scenario.
Many embedded use cases deal with unique situations, such as manufacturing plants, that are difficult to simulate. Synthetic data allows researchers complete control over the data generation process, enabling the creation of specific scenarios or conditions that are challenging to capture in real life.
While synthetic data offers numerous advantages, it is essential to use it judiciously. Care must be taken to ensure that the generated data accurately represents the underlying real-world distributions and does not introduce unintended biases.
Let us learn about synthetic data generation using Generative Adversarial Networks (GANs) on tabular data. We’ll take a hands-on approach, diving into the workings of the CTGAN model and applying it to the Synthea dataset from the healthcare domain. From data preprocessing to model training and evaluation, we’ll go step-by-step, learning how to create synthetic data, assess its quality, and unlock the potential of GANs for data augmentation and real-world applications.
![]()
5.4 Data Storage
Data sourcing and data storage go hand in hand, and data must be stored in a format that facilitates easy access and processing. Depending on the use case, various kinds of data storage systems can be used to store your datasets. Some examples are shown in Table 5.1.
| Database | Data Warehouse | Data Lake |
|---|---|---|
| Purpose | Operational and transactional | Analytical |
| Data type | Structured | Structured, semi-structured, and/or unstructured |
| Scale | Small to large volumes of data | Large volumes of integrated data Large volumes of diverse data |
| Examples | MySQL | Google BigQuery, Amazon Redshift, Microsoft Azure Synapse, Google Cloud Storage, AWS S3, Azure Data Lake Storage |
The stored data is often accompanied by metadata, defined as ’data about data .’It provides detailed contextual information about the data, such as means of data creation, time of creation, attached data use license, etc. For example, Hugging Face has Dataset Cards. To promote responsible data use, dataset creators should disclose potential biases through the dataset cards. These cards can educate users about a dataset’s contents and limitations. The cards also give vital context on appropriate dataset usage by highlighting biases and other important details. Having this type of metadata can also allow fast retrieval if structured properly. Once the model is developed and deployed to edge devices, the storage systems can continue to store incoming data, model updates, or analytical results.
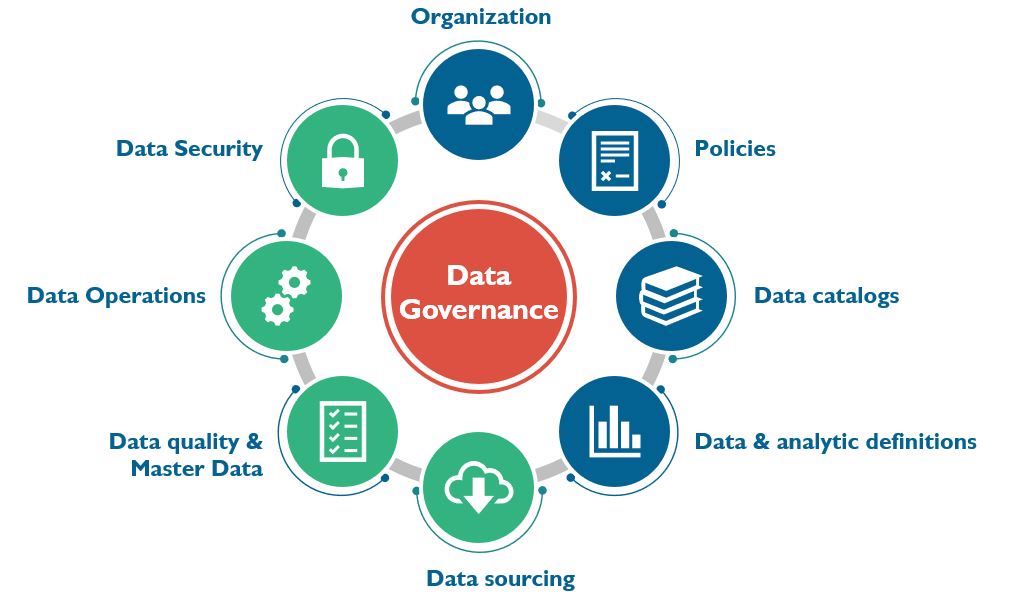
Data Governance: With a large amount of data storage, it is also imperative to have policies and practices (i.e., data governance) that help manage data during its life cycle, from acquisition to disposal. Data governance outlines how data is managed and includes making key decisions about data access and control. Figure 5.6 illustrates the different domains involved in data governance. It involves exercising authority and making decisions concerning data to uphold its quality, ensure compliance, maintain security, and derive value. Data governance is operationalized by developing policies, incentives, and penalties, cultivating a culture that perceives data as a valuable asset. Specific procedures and assigned authorities are implemented to safeguard data quality and monitor its utilization and related risks.
Data governance utilizes three integrative approaches: planning and control, organizational, and risk-based.
The planning and control approach, common in IT, aligns business and technology through annual cycles and continuous adjustments, focusing on policy-driven, auditable governance.
The organizational approach emphasizes structure, establishing authoritative roles like Chief Data Officers and ensuring responsibility and accountability in governance.
The risk-based approach, intensified by AI advancements, focuses on identifying and managing inherent risks in data and algorithms. It especially addresses AI-specific issues through regular assessments and proactive risk management strategies, allowing for incidental and preventive actions to mitigate undesired algorithm impacts.
Some examples of data governance across different sectors include:
Medicine: Health Information Exchanges(HIEs) enable the sharing of health information across different healthcare providers to improve patient care. They implement strict data governance practices to maintain data accuracy, integrity, privacy, and security, complying with regulations such as the Health Insurance Portability and Accountability Act (HIPAA). Governance policies ensure that patient data is only shared with authorized entities and that patients can control access to their information.
Finance: Basel III Framework is an international regulatory framework for banks. It ensures that banks establish clear policies, practices, and responsibilities for data management, ensuring data accuracy, completeness, and timeliness. Not only does it enable banks to meet regulatory compliance, but it also prevents financial crises by more effectively managing risks.
Government: Government agencies managing citizen data, public records, and administrative information implement data governance to manage data transparently and securely. The Social Security System in the US and the Aadhar system in India are good examples of such governance systems.
Special data storage considerations for TinyML
Efficient Audio Storage Formats: Keyword spotting systems need specialized audio storage formats to enable quick keyword searching in audio data. Traditional formats like WAV and MP3 store full audio waveforms, which require extensive processing to search through. Keyword spotting uses compressed storage optimized for snippet-based search. One approach is to store compact acoustic features instead of raw audio. Such a workflow would involve:
Extracting acoustic features: Mel-frequency cepstral coefficients (MFCCs) commonly represent important audio characteristics.
Creating Embeddings: Embeddings transform extracted acoustic features into continuous vector spaces, enabling more compact and representative data storage. This representation is essential in converting high-dimensional data, like audio, into a more manageable and efficient format for computation and storage.
Vector quantization: This technique represents high-dimensional data, like embeddings, with lower-dimensional vectors, reducing storage needs. Initially, a codebook is generated from the training data to define a set of code vectors representing the original data vectors. Subsequently, each data vector is matched to the nearest codeword according to the codebook, ensuring minimal information loss.
Sequential storage: The audio is fragmented into short frames, and the quantized features (or embeddings) for each frame are stored sequentially to maintain the temporal order, preserving the coherence and context of the audio data.
This format enables decoding the features frame-by-frame for keyword matching. Searching the features is faster than decompressing the full audio.
Selective Network Output Storage: Another technique for reducing storage is to discard the intermediate audio features stored during training but not required during inference. The network is run on full audio during training. However, only the final outputs are stored during inference.
5.5 Data Processing
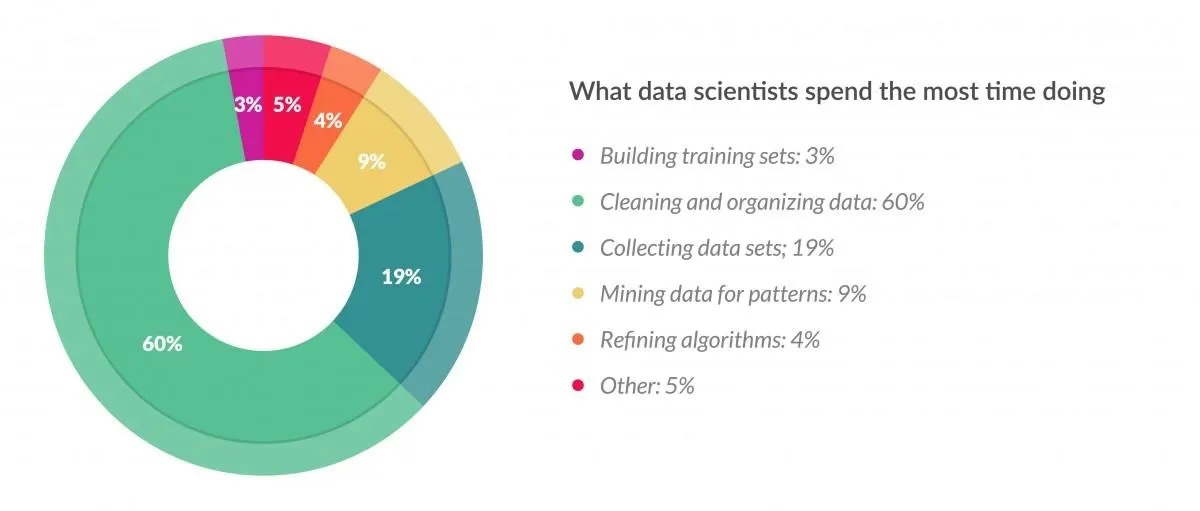
Data processing refers to the steps involved in transforming raw data into a format suitable for feeding into machine learning algorithms. It is a crucial stage in any ML workflow, yet often overlooked. With proper data processing, ML models are likely to achieve optimal performance. Figure 5.7 shows a breakdown of a data scientist’s time allocation, highlighting the significant portion spent on data cleaning and organizing (%60).
Proper data cleaning is a crucial step that directly impacts model performance. Real-world data is often dirty, containing errors, missing values, noise, anomalies, and inconsistencies. Data cleaning involves detecting and fixing these issues to prepare high-quality data for modeling. By carefully selecting appropriate techniques, data scientists can improve model accuracy, reduce overfitting, and train algorithms to learn more robust patterns. Overall, thoughtful data processing allows machine learning systems to uncover insights better and make predictions from real-world data.
Data often comes from diverse sources and can be unstructured or semi-structured. Thus, processing and standardizing it is essential, ensuring it adheres to a uniform format. Such transformations may include:
- Normalizing numerical variables
- Encoding categorical variables
- Using techniques like dimensionality reduction
Data validation serves a broader role than ensuring adherence to certain standards, like preventing temperature values from falling below absolute zero. These issues arise in TinyML because sensors may malfunction or temporarily produce incorrect readings; such transients are not uncommon. Therefore, it is imperative to catch data errors early before propagating through the data pipeline. Rigorous validation processes, including verifying the initial annotation practices, detecting outliers, and handling missing values through techniques like mean imputation, contribute directly to the quality of datasets. This, in turn, impacts the performance, fairness, and safety of the models trained on them. Let’s take a look at Figure 5.8 for an example of a data processing pipeline. In the context of TinyML, the Multilingual Spoken Words Corpus (MSWC) is an example of data processing pipelines—systematic and automated workflows for data transformation, storage, and processing. The input data (which’s a collection of short recordings) goes through several phases of processing, such as audio-word alignement and keyword extraction. By streamlining the data flow, from raw data to usable datasets, data pipelines improve productivity and facilitate the rapid development of machine learning models. The MSWC is an expansive and expanding collection of audio recordings of spoken words in 50 different languages, which are collectively used by over 5 billion people. This dataset is intended for academic study and business uses in areas like keyword identification and speech-based search. It is openly licensed under Creative Commons Attribution 4.0 for broad usage.
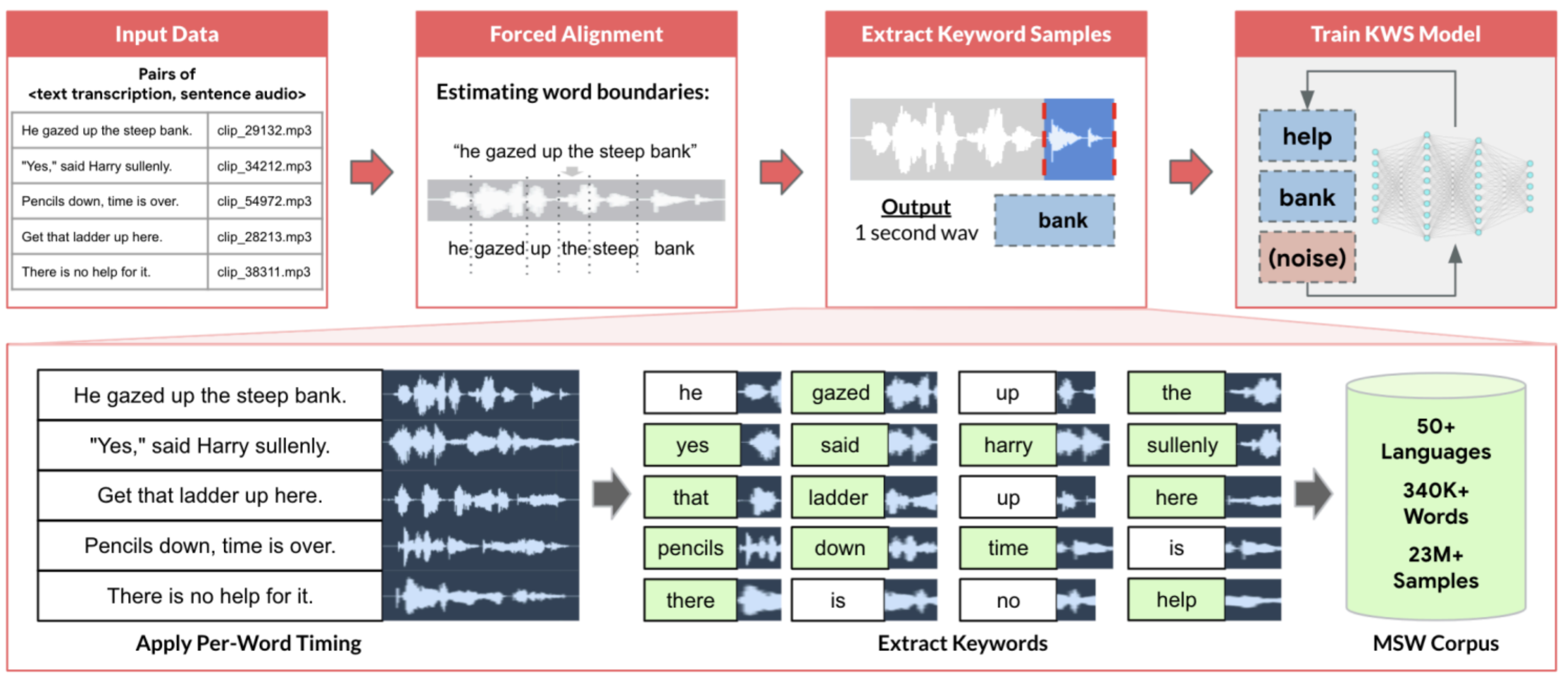
The MSWC used a forced alignment method to automatically extract individual word recordings to train keyword-spotting models from the Common Voice project, which features crowdsourced sentence-level recordings. Forced alignment refers to long-standing methods in speech processing that predict when speech phenomena like syllables, words, or sentences start and end within an audio recording. In the MSWC data, crowdsourced recordings often feature background noises, such as static and wind. Depending on the model’s requirements, these noises can be removed or intentionally retained.
Maintaining the integrity of the data infrastructure is a continuous endeavor. This encompasses data storage, security, error handling, and stringent version control. Periodic updates are crucial, especially in dynamic realms like keyword spotting, to adjust to evolving linguistic trends and device integrations.
There is a boom in data processing pipelines, commonly found in ML operations toolchains, which we will discuss in the MLOps chapter. Briefly, these include frameworks like MLOps by Google Cloud. It provides methods for automation and monitoring at all steps of ML system construction, including integration, testing, releasing, deployment, and infrastructure management. Several mechanisms focus on data processing, an integral part of these systems.
Let us explore two significant projects in speech data processing and machine learning. The MSWC is a vast audio dataset with over 340,000 keywords and 23.4 million 1-second spoken examples. It’s used in various applications like voice-enabled devices and call center automation. The Few-Shot Keyword Spotting project introduces a new approach for keyword spotting across different languages, achieving impressive results with minimal training data. We’ll look into the MSWC dataset, learn how to structure it effectively, and then train a few-shot keyword-spotting model. Let’s get started!
![]()
5.6 Data Labeling
Data labeling is important in creating high-quality training datasets for machine learning models. Labels provide ground truth information, allowing models to learn relationships between inputs and desired outputs. This section covers key considerations for selecting label types, formats, and content to capture the necessary information for tasks. It discusses common annotation approaches, from manual labeling to crowdsourcing to AI-assisted methods, and best practices for ensuring label quality through training, guidelines, and quality checks. We also emphasize the ethical treatment of human annotators. The integration of AI to accelerate and augment human annotation is also explored. Understanding labeling needs, challenges, and strategies are essential for constructing reliable, useful datasets to train performant, trustworthy machine learning systems.
5.6.1 Label Types
Labels capture information about key tasks or concepts. Figure 5.9 includes some common label types: a “classification label” is used for categorizing images with labels (labeling an image with “dog” if it features a dog); a “bounding box” identifies object location (drawing a box around the dog); a “segmentation map” classifies objects at the pixel level (highlighting the dog in a distinct color); a “caption” provides descriptive annotations (describing the dog’s actions, position, color, etc.); and a “transcript” denotes audio content. The choice of label format depends on the use case and resource constraints, as more detailed labels require greater effort to collect (Johnson-Roberson et al. 2017).

Unless focused on self-supervised learning, a dataset will likely provide labels addressing one or more tasks of interest. Given their unique resource constraints, dataset creators must consider what information labels should capture and how they can practically obtain the necessary labels. Creators must first decide what type(s) of content labels should capture. For example, a creator interested in car detection would want to label cars in their dataset. Still, they might also consider whether to simultaneously collect labels for other tasks that the dataset could potentially be used for, such as pedestrian detection.
Additionally, annotators can provide metadata that provides insight into how the dataset represents different characteristics of interest (see Section 5.9). The Common Voice dataset, for example, includes various types of metadata that provide information about the speakers, recordings, and dataset quality for each language represented (Ardila et al. 2020). They include demographic splits showing the number of recordings by speaker age range and gender. This allows us to see who contributed recordings for each language. They also include statistics like average recording duration and total hours of validated recordings. These give insights into the nature and size of the datasets for each language. Additionally, quality control metrics like the percentage of recordings that have been validated are useful to know how complete and clean the datasets are. The metadata also includes normalized demographic splits scaled to 100% for comparison across languages. This highlights representation differences between higher and lower resource languages.
Next, creators must determine the format of those labels. For example, a creator interested in car detection might choose between binary classification labels that say whether a car is present, bounding boxes that show the general locations of any cars, or pixel-wise segmentation labels that show the exact location of each car. Their choice of label format may depend on their use case and resource constraints, as finer-grained labels are typically more expensive and time-consuming to acquire.
5.6.2 Annotation Methods
Common annotation approaches include manual labeling, crowdsourcing, and semi-automated techniques. Manual labeling by experts yields high quality but needs more scalability. Crowdsourcing enables non-experts to distribute annotation, often through dedicated platforms (Sheng and Zhang 2019). Weakly supervised and programmatic methods can reduce manual effort by heuristically or automatically generating labels (Ratner et al. 2018).
After deciding on their labels’ desired content and format, creators begin the annotation process. To collect large numbers of labels from human annotators, creators frequently rely on dedicated annotation platforms, which can connect them to teams of human annotators. When using these platforms, creators may need more insight into annotators’ backgrounds and experience levels with topics of interest. However, some platforms offer access to annotators with specific expertise (e.g., doctors).
Let us explore Wake Vision, a comprehensive dataset designed for TinyML person detection. This dataset is derived from a larger, general-purpose dataset, Open Images (Kuznetsova et al. 2020), and tailored specifically for binary person detection.
The transformation process involves filtering and relabeling the existing labels and bounding boxes in Open Images using an automated pipeline. This method not only conserves time and resources but also ensures the dataset meets the specific requirements of TinyML applications.
Additionally, we generate metadata to benchmark the fairness and robustness of models in challenging scenarios.
Let’s get started!
![]()
5.6.3 Ensuring Label Quality
There is no guarantee that the data labels are actually correct. Figure 5.10 shows some examples of hard labeling cases: some errors arise from blurred pictures that make them hard to identify (the frog image), and others stem from a lack of domain knowledge (the black stork case). It is possible that despite the best instructions being given to labelers, they still mislabel some images (Northcutt, Athalye, and Mueller 2021). Strategies like quality checks, training annotators, and collecting multiple labels per datapoint can help ensure label quality. For ambiguous tasks, multiple annotators can help identify controversial datapoints and quantify disagreement levels.

When working with human annotators, offering fair compensation and otherwise prioritizing ethical treatment is important, as annotators can be exploited or otherwise harmed during the labeling process (Perrigo, 2023). For example, if a dataset is likely to contain disturbing content, annotators may benefit from having the option to view images in grayscale (Google, n.d.).
5.6.4 AI-Assisted Annotation
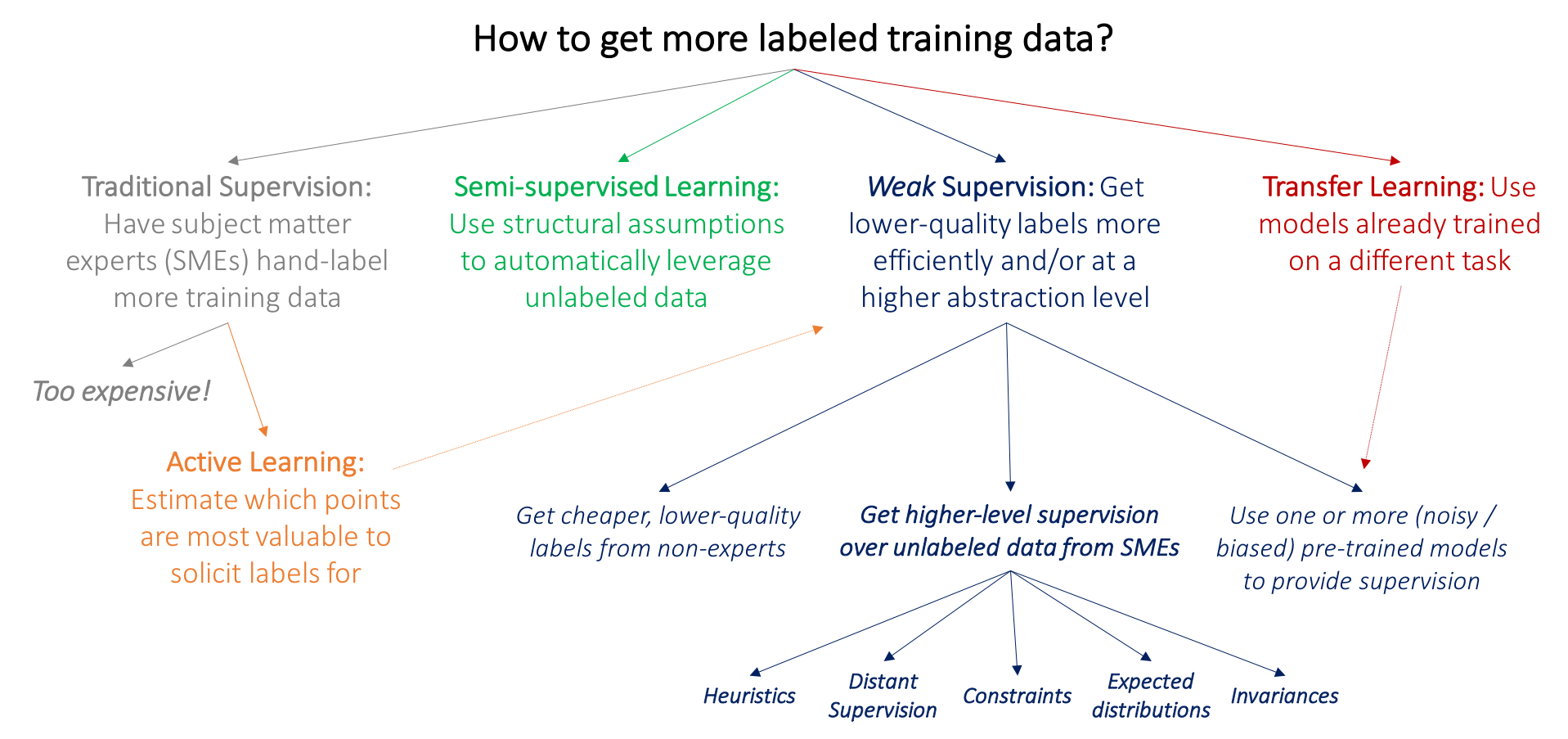
ML has an insatiable demand for data. Therefore, more data is needed. This raises the question of how we can get more labeled data. Rather than always generating and curating data manually, we can rely on existing AI models to help label datasets more quickly and cheaply, though often with lower quality than human annotation. This can be done in various ways as shown in Figure 5.11, including the following:
- Pre-annotation: AI models can generate preliminary labels for a dataset using methods such as semi-supervised learning (Chapelle, Scholkopf, and Zien 2009), which humans can then review and correct. This can save a significant amount of time, especially for large datasets.
- Active learning: AI models can identify the most informative data points in a dataset, which can then be prioritized for human annotation. This can help improve the labeled dataset’s quality while reducing the overall annotation time.
- Quality control: AI models can identify and flag potential errors in human annotations, helping to ensure the accuracy and consistency of the labeled dataset.
Here are some examples of how AI-assisted annotation has been proposed to be useful:
- Medical imaging: AI-assisted annotation labels medical images, such as MRI scans and X-rays (Krishnan, Rajpurkar, and Topol 2022). Carefully annotating medical datasets is extremely challenging, especially at scale, since domain experts are scarce and become costly. This can help to train AI models to diagnose diseases and other medical conditions more accurately and efficiently.
- Self-driving cars: AI-assisted annotation is being used to label images and videos from self-driving cars. This can help to train AI models to identify objects on the road, such as other vehicles, pedestrians, and traffic signs.
- Social media: AI-assisted annotation labels social media posts like images and videos. This can help to train AI models to identify and classify different types of content, such as news, advertising, and personal posts.
5.7 Data Version Control
Production systems are perpetually inundated with fluctuating and escalating volumes of data, prompting the rapid emergence of numerous data replicas. This increasing data serves as the foundation for training machine learning models. For instance, a global sales company engaged in sales forecasting continuously receives consumer behavior data. Similarly, healthcare systems formulating predictive models for disease diagnosis are consistently acquiring new patient data. TinyML applications, such as keyword spotting, are highly data-hungry regarding the amount of data generated. Consequently, meticulous tracking of data versions and the corresponding model performance is imperative.
Data Version Control offers a structured methodology to handle alterations and versions of datasets efficiently. It facilitates monitoring modifications, preserves multiple versions, and guarantees reproducibility and traceability in data-centric projects. Furthermore, data version control provides the versatility to review and use specific versions as needed, ensuring that each stage of the data processing and model development can be revisited and audited precisely and easily. It has a variety of practical uses -
Risk Management: Data version control allows transparency and accountability by tracking dataset versions.
Collaboration and Efficiency: Easy access to different dataset versions in one place can improve data sharing of specific checkpoints and enable efficient collaboration.
Reproducibility: Data version control allows for tracking the performance of models concerning different versions of the data, and therefore enabling reproducibility.
Key Concepts
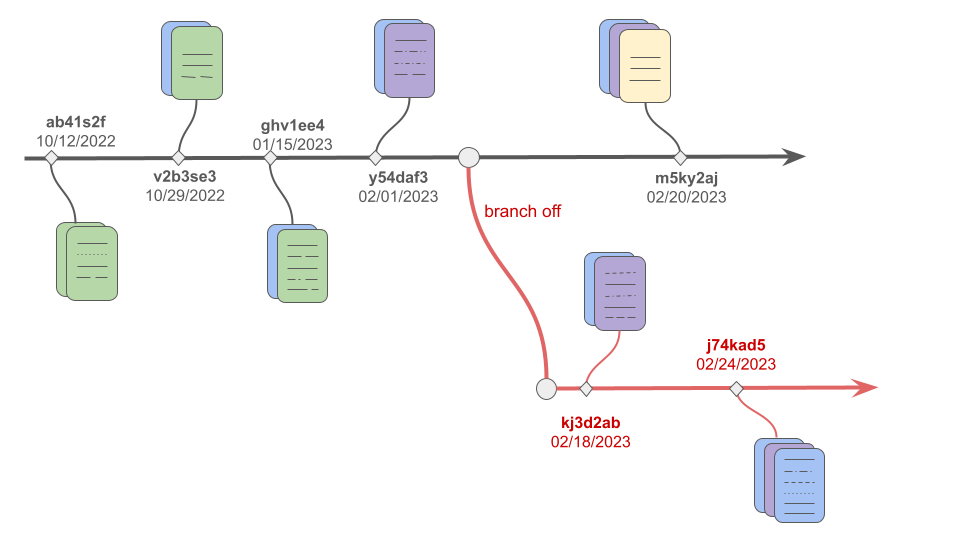
Commits: It is an immutable snapshot of the data at a specific point in time, representing a unique version. Every commit is associated with a unique identifier to allow
Branches: Branching allows developers and data scientists to diverge from the main development line and continue to work independently without affecting other branches. This is especially useful when experimenting with new features or models, enabling parallel development and experimentation without the risk of corrupting the stable main branch.
Merges: Merges help to integrate changes from different branches while maintaining the integrity of the data.
With data version control in place, we can track the changes shown in Figure 5.12, reproduce previous results by reverting to older versions, and collaborate safely by branching off and isolating the changes.
Popular Data Version Control Systems
DVC: It stands for Data Version Control in short and is an open-source, lightweight tool that works on top of Git Hub and supports all kinds of data formats. It can seamlessly integrate into the workflow if Git is used to manage code. It captures the versions of data and models in the Git commits while storing them on-premises or on the cloud (e.g., AWS, Google Cloud, Azure). These data and models (e.g., ML artifacts) are defined in the metadata files, which get updated in every commit. It can allow metrics tracking of models on different versions of the data.
lakeFS: It is an open-source tool that supports the data version control on data lakes. It supports many git-like operations, such as branching and merging of data, as well as reverting to previous versions of the data. It also has a unique UI feature, making exploring and managing data much easier.
Git LFS: It is useful for data version control on smaller-sized datasets. It uses Git’s inbuilt branching and merging features but is limited in tracking metrics, reverting to previous versions, or integrating with data lakes.
5.8 Optimizing Data for Embedded AI
Creators working on embedded systems may have unusual priorities when cleaning their datasets. On the one hand, models may be developed for unusually specific use cases, requiring heavy filtering of datasets. While other natural language models may be capable of turning any speech into text, a model for an embedded system may be focused on a single limited task, such as detecting a keyword. As a result, creators may aggressively filter out large amounts of data because they need to address the task of interest. An embedded AI system may also be tied to specific hardware devices or environments. For example, a video model may need to process images from a single type of camera, which will only be mounted on doorbells in residential neighborhoods. In this scenario, creators may discard images if they came from a different kind of camera, show the wrong type of scenery, or were taken from the wrong height or angle.
On the other hand, embedded AI systems are often expected to provide especially accurate performance in unpredictable real-world settings. This may lead creators to design datasets to represent variations in potential inputs and promote model robustness. As a result, they may define a narrow scope for their project but then aim for deep coverage within those bounds. For example, creators of the doorbell model mentioned above might try to cover variations in data arising from:
- Geographically, socially, and architecturally diverse neighborhoods
- Different types of artificial and natural lighting
- Different seasons and weather conditions
- Obstructions (e.g., raindrops or delivery boxes obscuring the camera’s view)
As described above, creators may consider crowdsourcing or synthetically generating data to include these variations.
5.9 Data Transparency
By providing clear, detailed documentation, creators can help developers understand how best to use their datasets. Several groups have suggested standardized documentation formats for datasets, such as Data Cards (Pushkarna, Zaldivar, and Kjartansson 2022), datasheets (Gebru et al. 2021), data statements (Bender and Friedman 2018), or Data Nutrition Labels (Holland et al. 2020). When releasing a dataset, creators may describe what kinds of data they collected, how they collected and labeled it, and what kinds of use cases may be a good or poor fit for the dataset. Quantitatively, it may be appropriate to show how well the dataset represents different groups (e.g., different gender groups, different cameras).
Figure 5.13 shows an example of a data card for a computer vision (CV) dataset. It includes some basic information about the dataset and instructions on how to use it, including known biases.

Keeping track of data provenance- essentially the origins and the journey of each data point through the data pipeline- is not merely a good practice but an essential requirement for data quality. Data provenance contributes significantly to the transparency of machine learning systems. Transparent systems make it easier to scrutinize data points, enabling better identification and rectification of errors, biases, or inconsistencies. For instance, if an ML model trained on medical data is underperforming in particular areas, tracing the provenance can help identify whether the issue is with the data collection methods, the demographic groups represented in the data or other factors. This level of transparency doesn’t just help debug the system but also plays a crucial role in enhancing the overall data quality. By improving the reliability and credibility of the dataset, data provenance also enhances the model’s performance and its acceptability among end-users.
When producing documentation, creators should also specify how users can access the dataset and how the dataset will be maintained over time. For example, users may need to undergo training or receive special permission from the creators before accessing a protected information dataset, as with many medical datasets. In some cases, users may not access the data directly. Instead, they must submit their model to be trained on the dataset creators’ hardware, following a federated learning setup (Aledhari et al. 2020). Creators may also describe how long the dataset will remain accessible, how the users can submit feedback on any errors they discover, and whether there are plans to update the dataset.
Some laws and regulations also promote data transparency through new requirements for organizations:
- General Data Protection Regulation (GDPR) in the European Union: It establishes strict requirements for processing and protecting the personal data of EU citizens. It mandates plain-language privacy policies that clearly explain what data is collected, why it is used, how long it is stored, and with whom it is shared. GDPR also mandates that privacy notices must include details on the legal basis for processing, data transfers, retention periods, rights to access and deletion, and contact info for data controllers.
- California’s Consumer Privacy Act (CCPA): CCPA requires clear privacy policies and opt-out rights to sell personal data. Significantly, it also establishes rights for consumers to request their specific data be disclosed. Businesses must provide copies of collected personal information and details on what it is used for, what categories are collected, and what third parties receive. Consumers can identify data points they believe need to be more accurate. The law represents a major step forward in empowering personal data access.
Ensured data transparency presents several challenges, especially because it requires significant time and financial resources. Data systems are also quite complex, and full transparency can take time. Full transparency may also overwhelm consumers with too much detail. Finally, it is also important to balance the tradeoff between transparency and privacy.
5.10 Licensing
Many high-quality datasets either come from proprietary sources or contain copyrighted information. This introduces licensing as a challenging legal domain. Companies eager to train ML systems must engage in negotiations to obtain licenses that grant legal access to these datasets. Furthermore, licensing terms can impose restrictions on data applications and sharing methods. Failure to comply with these licenses can have severe consequences.
For instance, ImageNet, one of the most extensively utilized datasets for computer vision research, is a case in point. Most of its images were procured from public online sources without explicit permission, sparking ethical concerns (Prabhu and Birhane, 2020). Accessing the ImageNet dataset for corporations requires registration and adherence to its terms of use, which restricts commercial usage (ImageNet, 2021). Major players like Google and Microsoft invest significantly in licensing datasets to improve their ML vision systems. However, the cost factor restricts accessibility for researchers from smaller companies with constrained budgets.
The legal domain of data licensing has seen major cases that help define fair use parameters. A prominent example is Authors Guild, Inc. v. Google, Inc. This 2005 lawsuit alleged that Google’s book scanning project infringed copyrights by displaying snippets without permission. However, the courts ultimately ruled in Google’s favor, upholding fair use based on the transformative nature of creating a searchable index and showing limited text excerpts. This precedent provides some legal grounds for arguing fair use protections apply to indexing datasets and generating representative samples for machine learning. However, license restrictions remain binding, so a comprehensive analysis of licensing terms is critical. The case demonstrates why negotiations with data providers are important to enable legal usage within acceptable bounds.
New Data Regulations and Their Implications
New data regulations also impact licensing practices. The legislative landscape is evolving with regulations like the EU’s Artificial Intelligence Act, which is poised to regulate AI system development and use within the European Union (EU). This legislation:
Classifies AI systems by risk.
Mandates development and usage prerequisites.
Emphasizes data quality, transparency, human oversight, and accountability.
Additionally, the EU Act addresses the ethical dimensions and operational challenges in sectors such as healthcare and finance. Key elements include the prohibition of AI systems posing “unacceptable” risks, stringent conditions for high-risk systems, and minimal obligations for “limited risk” AI systems. The proposed European AI Board will oversee and ensure the implementation of efficient regulation.
Challenges in Assembling ML Training Datasets
Complex licensing issues around proprietary data, copyright law, and privacy regulations constrain options for assembling ML training datasets. However, expanding accessibility through more open licensing or public-private data collaborations could greatly accelerate industry progress and ethical standards.
Sometimes, certain portions of a dataset may need to be removed or obscured to comply with data usage agreements or protect sensitive information. For example, a dataset of user information may have names, contact details, and other identifying data that may need to be removed from the dataset; this is well after the dataset has already been actively sourced and used for training models. Similarly, a dataset that includes copyrighted content or trade secrets may need to filter out those portions before being distributed. Laws such as the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), and the Amended Act on the Protection of Personal Information (APPI) have been passed to guarantee the right to be forgotten. These regulations legally require model providers to erase user data upon request.
Data collectors and providers need to be able to take appropriate measures to de-identify or filter out any proprietary, licensed, confidential, or regulated information as needed. Sometimes, the users may explicitly request that their data be removed.
The ability to update the dataset by removing data from the dataset will enable the creators to uphold legal and ethical obligations around data usage and privacy. However, the ability to remove data has some important limitations. We must consider that some models may have already been trained on the dataset, and there is no clear or known way to eliminate a particular data sample’s effect from the trained network. There is no erase mechanism. Thus, this begs the question, should the model be retrained from scratch each time a sample is removed? That’s a costly option. Once data has been used to train a model, simply removing it from the original dataset may not fully eliminate its impact on the model’s behavior. New research is needed around the effects of data removal on already-trained models and whether full retraining is necessary to avoid retaining artifacts of deleted data. This presents an important consideration when balancing data licensing obligations with efficiency and practicality in an evolving, deployed ML system.
Dataset licensing is a multifaceted domain that intersects technology, ethics, and law. Understanding these intricacies becomes paramount for anyone building datasets during data engineering as the world evolves.
5.11 Conclusion
Data is the fundamental building block of AI systems. Without quality data, even the most advanced machine learning algorithms will fail. Data engineering encompasses the end-to-end process of collecting, storing, processing, and managing data to fuel the development of machine learning models. It begins with clearly defining the core problem and objectives, which guides effective data collection. Data can be sourced from diverse means, including existing datasets, web scraping, crowdsourcing, and synthetic data generation. Each approach involves tradeoffs between cost, speed, privacy, and specificity. Once data is collected, thoughtful labeling through manual or AI-assisted annotation enables the creation of high-quality training datasets. Proper storage in databases, warehouses, or lakes facilitates easy access and analysis. Metadata provides contextual details about the data. Data processing transforms raw data into a clean, consistent format for machine learning model development. Throughout this pipeline, transparency through documentation and provenance tracking is crucial for ethics, auditability, and reproducibility. Data licensing protocols also govern legal data access and use. Key challenges in data engineering include privacy risks, representation gaps, legal restrictions around proprietary data, and the need to balance competing constraints like speed versus quality. By thoughtfully engineering high-quality training data, machine learning practitioners can develop accurate, robust, and responsible AI systems, including embedded and TinyML applications.
5.12 Resources
Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will add new exercises soon.
These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to improve their understanding and facilitate effective knowledge transfer.
Data Anomaly Detection:
- Coming soon.
To reinforce the concepts covered in this chapter, we have curated a set of exercises that challenge students to apply their knowledge and deepen their understanding.
In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
- Coming soon.