7 AI Training
Resources: Slides, Videos, Exercises, Labs

Training is central to developing accurate and useful AI systems using machine learning techniques. At a high level, training involves feeding data into machine learning algorithms so they can learn patterns and make predictions. However, effectively training models requires tackling various challenges around data, algorithms, optimization of model parameters, and enabling generalization. This chapter will explore the nuances and considerations around training machine learning models.
Understand the fundamental mathematics of neural networks, including linear transformations, activation functions, loss functions, backpropagation, and optimization via gradient descent.
Learn how to effectively leverage data for model training through proper splitting into train, validation, and test sets to enable generalization.
Learn various optimization algorithms like stochastic gradient descent and adaptations like momentum and Adam that accelerate training.
Understand hyperparameter tuning and regularization techniques to improve model generalization by reducing overfitting.
Learn proper weight initialization strategies matched to model architectures and activation choices that accelerate convergence.
Identify the bottlenecks posed by key operations like matrix multiplication during training and deployment.
Learn how hardware improvements like GPUs, TPUs, and specialized accelerators speed up critical math operations to accelerate training.
Understand parallelization techniques, both data and model parallelism, to distribute training across multiple devices and accelerate system throughput.
7.1 Introduction
Training is critical for developing accurate and useful AI systems using machine learning. The training creates a machine learning model that can generalize to new, unseen data rather than memorizing the training examples. This is done by feeding training data into algorithms that learn patterns from these examples by adjusting internal parameters.
The algorithms minimize a loss function, which compares their predictions on the training data to the known labels or solutions, guiding the learning. Effective training often requires high-quality, representative data sets large enough to capture variability in real-world use cases.
It also requires choosing an algorithm suited to the task, whether a neural network for computer vision, a reinforcement learning algorithm for robotic control, or a tree-based method for categorical prediction. Careful tuning is needed for the model structure, such as neural network depth and width, and learning parameters like step size and regularization strength.
Techniques to prevent overfitting like regularization penalties and validation with held-out data, are also important. Overfitting can occur when a model fits the training data too closely, failing to generalize to new data. This can happen if the model is too complex or trained too long.
To avoid overfitting, regularization techniques can help constrain the model. One regularization method is adding a penalty term to the loss function that discourages complexity, like the L2 norm of the weights. This penalizes large parameter values. Another technique is dropout, where a percentage of neurons is randomly set to zero during training. This reduces neuron co-adaptation.
Validation methods also help detect and avoid overfitting. Part of the training data is held out from the training loop as a validation set. The model is evaluated on this data. If validation error increases while training error decreases, overfitting occurs. The training can then be stopped early or regularized more strongly. Regularization and validation enable models to train to maximum capability without overfitting the training data.
Training takes significant computing resources, especially for deep neural networks used in computer vision, natural language processing, and other areas. These networks have millions of adjustable weights that must be tuned through extensive training. Hardware improvements and distributed training techniques have enabled training ever larger neural nets that can achieve human-level performance on some tasks.
In summary, some key points about training:
- Data is crucial: Machine learning models learn from examples in training data. More high-quality, representative data leads to better model performance. Data needs to be processed and formatted for training.
- Algorithms learn from data: Different algorithms (neural networks, decision trees, etc.) have different approaches to finding patterns in data. Choosing the right algorithm for the task is important.
- Training refines model parameters: Model training adjusts internal parameters to find patterns in data. Advanced models like neural networks have many adjustable weights. Training iteratively adjusts weights to minimize a loss function.
- Generalization is the goal: A model that overfits the training data will not generalize well. Regularization techniques (dropout, early stopping, etc.) reduce overfitting. Validation data is used to evaluate generalization.
- Training takes compute resources: Training complex models requires significant processing power and time. Hardware improvements and distributed training across GPUs/TPUs have enabled advances.
We will walk you through these details in the rest of the sections. Understanding how to effectively leverage data, algorithms, parameter optimization, and generalization through thorough training is essential for developing capable, deployable AI systems that work robustly in the real world.
7.2 Mathematics of Neural Networks
Deep learning has revolutionized machine learning and artificial intelligence, enabling computers to learn complex patterns and make intelligent decisions. The neural network is at the heart of the deep learning revolution, and as discussed in section 3, “Deep Learning Primer,” it is a cornerstone in some of these advancements.
Neural networks are made up of simple functions layered on each other. Each layer takes in some data, performs some computation, and passes it to the next layer. These layers learn progressively high-level features useful for the tasks the network is trained to perform. For example, in a network trained for image recognition, the input layer may take in pixel values, while the next layers may detect simple shapes like edges. The layers after that may detect more complex shapes like noses, eyes, etc. The final output layer classifies the image as a whole.
The network in a neural network refers to how these layers are connected. Each layer’s output is considered a set of neurons, which are connected to neurons in the subsequent layers, forming a “network.” The way these neurons interact is determined by the weights between them, which model synaptic strengths similar to that of a brain’s neuron. The neural network is trained by adjusting these weights. Concretely, the weights are initially set randomly, then input is fed in, the output is compared to the desired result, and finally, the weights are tweaked to improve the network. This process is repeated until the network reliably minimizes the loss, indicating it has learned the patterns in the data.
How is this process defined mathematically? Formally, neural networks are mathematical models that consist of alternating linear and nonlinear operations, parameterized by a set of learnable weights that are trained to minimize some loss function. This loss function measures how good our model is concerning fitting our training data, and it produces a numerical value when evaluated on our model against the training data. Training neural networks involves repeatedly evaluating the loss function on many different data points to measure how good our model is, then continuously tweaking the weights of our model using backpropagation so that the loss decreases, ultimately optimizing the model to fit our data.
7.2.1 Neural Network Notation
Diving into the details, the core of a neural network can be viewed as a sequence of alternating linear and nonlinear operations, as show in Figure 7.1:
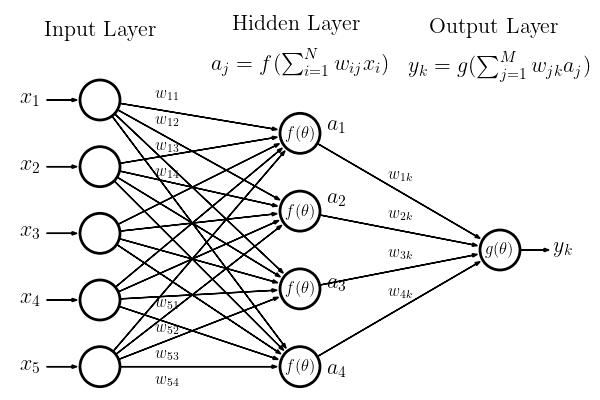
The neural network operates by taking an input vector \(x_i\) and passing it through a series of layers, each of which performs linear and non-linear operations. The output of the network at each layer \(A_j\) can be represented as:
\[ A_j = f\left(\sum_{i=1}^{N} w_{ij} x_i\right) \]
Where:
- \(N\) - The total number of input features.
- \(x_{i}\) - The individual input feature, where \(i\) ranges from \(1\) to \(N\).
- \(w_{ij}\) - The weights connecting neuron \(i\) in one layer to neuron \(j\) in the next layer, which are adjusted during training.
- \(f(\theta)\) - The non-linear activation function applied at each layer (e.g., ReLU, softmax, etc.).
- \(A_{j}\) - The output of the neural network at each layer \(j\), where \(j\) denotes the layer number.
In the context of Figure 7.1, \(x_1, x_2, x_3, x_4,\) and \(x_5\) represent the input features. Each input neuron \(x_i\) corresponds to one feature of the input data. The arrows from the input layer to the hidden layer indicate connections between the input neurons and the hidden neurons, with each connection associated with a weight \(w_{ij}\).
The hidden layer consists of neurons \(a_1, a_2, a_3,\) and \(a_4\), each receiving input from all the neurons in the input layer. The weights \(w_{ij}\) connect the input neurons to the hidden neurons. For example, \(w_{11}\) is the weight connecting input \(x_1\) to hidden neuron \(a_1\).
The number of nodes in each layer and the total number of layers together define the architecture of the neural network. In the first layer (input layer), the number of nodes corresponds to the dimensionality of the input data, while in the last layer (output layer), the number of nodes corresponds to the dimensionality of the output. The number of nodes in the intermediate layers can be set arbitrarily, allowing flexibility in designing the network architecture.
The weights, which determine how each layer of the neural network interacts with the others, are matrices of real numbers. Additionally, each layer typically includes a bias vector, but we are ignoring it here for simplicity. The weight matrix \(W_j\) connecting layer \(j-1\) to layer \(j\) has the dimensions:
\[ W_j \in \mathbb{R}^{d_j \times d_{j-1}} \]
where \(d_j\) is the number of nodes in layer \(j\), and \(d_{j-1}\) is the number of nodes in the previous layer \(j-1\).
The final output \(y_k\) of the network is obtained by applying another activation function \(g(\theta)\) to the weighted sum of the hidden layer outputs:
\[ y = g\left(\sum_{j=1}^{M} w_{jk} A_j\right) \]
Where:
- \(M\) - The number of hidden neurons in the final layer before the output.
- \(w_{jk}\) - The weight between hidden neuron \(a_j\) and output neuron \(y_k\).
- \(g(\theta)\) - The activation function applied to the weighted sum of the hidden layer outputs.
Our neural network, as defined, performs a sequence of linear and nonlinear operations on the input data (\(x_{i}\)) to obtain predictions (\(y_{i}\)), which hopefully is a good answer to what we want the neural network to do on the input (i.e., classify if the input image is a cat or not). Our neural network may then be represented succinctly as a function \(N\) which takes in an input \(x \in \mathbb{R}^{d_0}\) parameterized by \(W_1, ..., W_n\), and produces the final output \(y\):
\[ y = N(x; W_1, ..., W_n) \quad \text{where } A_0 = x \]
This equation indicates that the network starts with the input \(A_0 = x\) and iteratively computes \(A_j\) at each layer using the parameters \(W_j\) until it produces the final output \(y\) at the output layer.
Next, we will see how to evaluate this neural network against training data by introducing a loss function.
Why are the nonlinear operations necessary? If we only had linear layers, the entire network would be equivalent to a single linear layer consisting of the product of the linear operators. Hence, the nonlinear functions play a key role in the power of neural networks as they improve the neural network’s ability to fit functions.
Convolutions are also linear operators and can be cast as a matrix multiplication.
7.2.2 Loss Function as a Measure of Goodness of Fit against Training Data
After defining our neural network, we are given some training data, which is a set of points \({(x_j, y_j)}\) for \(j=1 \rightarrow M\), where \(M\) is the total number of samples in the dataset, and \(j\) indexes each sample. We want to evaluate how good our neural network is at fitting this data. To do this, we introduce a loss function, which is a function that takes the output of the neural network on a particular datapoint \(\hat{y_j} = N(x_j; W_1, ..., W_n)\) and compares it against the “label” of that particular datapoint (the corresponding \(y_j\)), and outputs a single numerical scalar (i.e., one real number) that represents how “good” the neural network fits that particular data point; the final measure of how good the neural network is on the entire dataset is therefore just the average of the losses across all data points.
There are many different types of loss functions; for example, in the case of image classification, we might use the cross-entropy loss function, which tells us how well two vectors representing classification predictions compare (i.e., if our prediction predicts that an image is more likely a dog, but the label says it is a cat, it will return a high “loss,” indicating a bad fit).
Mathematically, a loss function is a function that takes in two real-valued vectors, one representing the predicted outputs of the neural network and the other representing the true labels, and outputs a single numerical scalar representing the error or “loss.”
\[ L: \mathbb{R}^{d_{n}} \times \mathbb{R}^{d_{n}} \longrightarrow \mathbb{R} \]
For a single training example, the loss is given by:
\[ L(N(x_j; W_1, ..., W_n), y_j) \]
where \(\hat{y}_j = N(x_j; W_1, ..., W_n)\) is the predicted output of the neural network for the input \(x_j\), and \(y_j\) is the true label.
The total loss across the entire dataset, \(L_{full}\), is then computed as the average loss across all data points in the training data:
Loss Function for Optimizing Neural Network Model on a Dataset \[ L_{full} = \frac{1}{M} \sum_{j=1}^{M} L(N(x_j; W_1,...W_n), y_j) \]
7.2.3 Training Neural Networks with Gradient Descent
Now that we can measure how well our network fits the training data, we can optimize the neural network weights to minimize this loss. In this context, we are denoting \(W_i\) as the weights for each layer \(i\) in the network. At a high level, we tweak the parameters of the real-valued matrices \(W_i\)s to minimize the loss function \(L_{full}\). Overall, our mathematical objective is
Neural Network Training Objective \[ min_{W_1, ..., W_n} L_{full} \] \[ = min_{W_1, ..., W_n} \frac{1}{M} \sum_{j=1}^{M} L(N(x_j; W_1,...W_n), y_j) \]
So, how do we optimize this objective? Recall from calculus that minimizing a function can be done by taking the function’s derivative concerning the input parameters and tweaking the parameters in the gradient direction. This technique is called gradient descent and concretely involves calculating the derivative of the loss function \(L_{full}\) concerning \(W_1, ..., W_n\) to obtain a gradient for these parameters to take a step in, then updating these parameters in the direction of the gradient. Thus, we can train our neural network using gradient descent, which repeatedly applies the update rule.
Gradient Descent Update Rule \[ W_i := W_i - \lambda \frac{\partial L_{full}}{\partial W_i} \mbox{ for } i=1..n \]
In practice, the gradient is computed over a minibatch of data points to improve computational efficiency. This is called stochastic gradient descent or batch gradient descent.
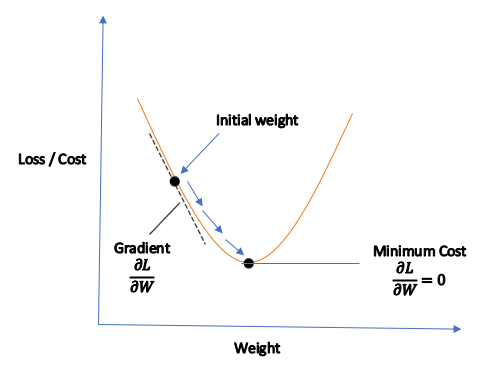
Where \(\lambda\) is the stepsize or learning rate of our tweaks, in training our neural network, we repeatedly perform the step above until convergence, or when the loss no longer decreases. Figure 7.2 illustrates this process: we want to reach the minimum point, which’s done by following the gradient (as illustrated with the blue arrows in the figure). This prior approach is known as full gradient descent since we are computing the derivative concerning the entire training data and only then taking a single gradient step; a more efficient approach is to calculate the gradient concerning just a random batch of data points and then taking a step, a process known as batch gradient descent or stochastic gradient descent (Robbins and Monro 1951), which is more efficient since now we are taking many more steps per pass of the entire training data. Next, we will cover the mathematics behind computing the gradient of the loss function concerning the \(W_i\)s, a process known as backpropagation.
7.2.4 Backpropagation
Training neural networks involve repeated applications of the gradient descent algorithm, which involves computing the derivative of the loss function with respect to the \(W_i\)s. How do we compute the loss derivative concerning the \(W_i\)s, given that the \(W_i\)s are nested functions of each other in a deep neural network? The trick is to leverage the chain rule: we can compute the derivative of the loss concerning the \(W_i\)s by repeatedly applying the chain rule in a complete process known as backpropagation. Specifically, we can calculate the gradients by computing the derivative of the loss concerning the outputs of the last layer, then progressively use this to compute the derivative of the loss concerning each prior layer to the input layer. This process starts from the end of the network (the layer closest to the output) and progresses backwards, and hence gets its name backpropagation.
Let’s break this down. We can compute the derivative of the loss concerning the outputs of each layer of the neural network by using repeated applications of the chain rule.
\[ \frac{\partial L_{full}}{\partial L_{n}} = \frac{\partial A_{n}}{\partial L_{n}} \frac{\partial L_{full}}{\partial A_{n}} \]
\[ \frac{\partial L_{full}}{\partial L_{n-1}} = \frac{\partial A_{n-1}}{\partial L_{n-1}} \frac{\partial L_{n}}{\partial A_{n-1}} \frac{\partial A_{n}}{\partial L_{n}} \frac{\partial L_{full}}{\partial A_{n}} \]
or more generally
\[ \frac{\partial L_{full}}{\partial L_{i}} = \frac{\partial A_{i}}{\partial L_{i}} \frac{\partial L_{i+1}}{\partial A_{i}} ... \frac{\partial A_{n}}{\partial L_{n}} \frac{\partial L_{full}}{\partial A_{n}} \]
In what order should we perform this computation? From a computational perspective, performing the calculations from the end to the front is preferable. (i.e: first compute \(\frac{\partial L_{full}}{\partial A_{n}}\) then the prior terms, rather than start in the middle) since this avoids materializing and computing large jacobians. This is because \(\ \frac {\partial L_{full}}{\partial A_{n}}\) is a vector; hence, any matrix operation that includes this term has an output that is squished to be a vector. Thus, performing the computation from the end avoids large matrix-matrix multiplications by ensuring that the intermediate products are vectors.
In our notation, we assume the intermediate activations \(A_{i}\) are column vectors, rather than row vectors, hence the chain rule is \(\frac{\partial L}{\partial L_{i}} = \frac{\partial L_{i+1}}{\partial L_{i}} ... \frac{\partial L}{\partial L_{n}}\) rather than \(\frac{\partial L}{\partial L_{i}} = \frac{\partial L}{\partial L_{n}} ... \frac{\partial L_{i+1}}{\partial L_{i}}\)
After computing the derivative of the loss concerning the output of each layer, we can easily obtain the derivative of the loss concerning the parameters, again using the chain rule:
\[ \frac{\partial L_{full}}{W_{i}} = \frac{\partial L_{i}}{\partial W_{i}} \frac{\partial L_{full}}{\partial L_{i}} \]
And this is ultimately how the derivatives of the layers’ weights are computed using backpropagation! What does this concretely look like in a specific example? Below, we walk through a specific example of a simple 2-layer neural network on a regression task using an MSE loss function with 100-dimensional inputs and a 30-dimensional hidden layer:
Example of Backpropagation
Suppose we have a two-layer neural network \[ L_1 = W_1 A_{0} \] \[ A_1 = ReLU(L_1) \] \[ L_2 = W_2 A_{1} \] \[ A_2 = ReLU(L_2) \] \[ NN(x) = \mbox{Let } A_{0} = x \mbox{ then output } A_2 \] where \(W_1 \in \mathbb{R}^{30 \times 100}\) and \(W_2 \in \mathbb{R}^{1 \times 30}\). Furthermore, suppose we use the MSE loss function: \[ L(x, y) = (x-y)^2 \] We wish to compute \[ \frac{\partial L(NN(x), y)}{\partial W_i} \mbox{ for } i=1,2 \] Note the following: \[ \frac{\partial L(x, y)}{\partial x} = 2 \times (x-y) \] \[ \frac{\partial ReLU(x)}{\partial x} \delta = \left\{\begin{array}{lr} 0 & \text{for } x \leq 0 \\ 1 & \text{for } x \geq 0 \\ \end{array}\right\} \odot \delta \] \[ \frac{\partial WA}{\partial A} \delta = W^T \delta \] \[ \frac{\partial WA}{\partial W} \delta = \delta A^T \] Then we have \[ \frac{\partial L(NN(x), y)}{\partial W_2} = \frac{\partial L_2}{\partial W_2} \frac{\partial A_2}{\partial L_2} \frac{\partial L(NN(x), y)}{\partial A_2} \] \[ = (2L(NN(x) - y) \odot ReLU'(L_2)) A_1^T \] and \[ \frac{\partial L(NN(x), y)}{\partial W_1} = \frac{\partial L_1}{\partial W_1} \frac{\partial A_1}{\partial L_1} \frac{\partial L_2}{\partial A_1} \frac{\partial A_2}{\partial L_2} \frac{\partial L(NN(x), y)}{\partial A_2} \] \[ = [ReLU'(L_1) \odot (W_2^T [2L(NN(x) - y) \odot ReLU'(L_2)])] A_0^T \]
Double-check your work by making sure that the shapes are correct!
- All Hadamard products (\(\odot\)) should operate on tensors of the same shape
- All matrix multiplications should operate on matrices that share a common dimension (i.e., m by n, n by k)
- All gradients concerning the weights should have the same shape as the weight matrices themselves
The entire backpropagation process can be complex, especially for very deep networks. Fortunately, machine learning frameworks like PyTorch support automatic differentiation, which performs backpropagation for us. In these frameworks, we simply need to specify the forward pass, and the derivatives will be automatically computed for us. Nevertheless, it is beneficial to understand the theoretical process that is happening under the hood in these machine-learning frameworks.
As seen above, intermediate activations \(A_i\) are reused in backpropagation. To improve performance, these activations are cached from the forward pass to avoid being recomputed. However, activations must be kept in memory between the forward and backward passes, leading to higher memory usage. If the network and batch size are large, this may lead to memory issues. Similarly, the derivatives with respect to each layer’s outputs are cached to avoid recomputation.
Unlock the math behind powerful neural networks! Deep learning might seem like magic, but it’s rooted in mathematical principles. In this chapter, you’ve broken down neural network notation, loss functions, and the powerful technique of backpropagation. Now, prepare to implement this theory with these Colab notebooks. Dive into the heart of how neural networks learn. You’ll see the math behind backpropagation and gradient descent, updating those weights step-by-step.
![]()
7.3 Differentiable Computation Graphs
In general, stochastic gradient descent using backpropagation can be performed on any computational graph that a user may define, provided that the operations of the computation are differentiable. As such, generic deep learning libraries like PyTorch and Tensorflow allow users to specify their computational process (i.e., neural networks) as a computational graph. Backpropagation is automatically performed via automatic differentiation when stochastic gradient descent is performed on these computational graphs. Framing AI training as an optimization problem on differentiable computation graphs is a general way to understand what is happening under the hood with deep learning systems.
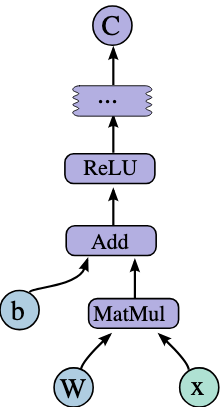
The structure depicted in Figure 7.3 showcases a segment of a differentiable computational graph. In this graph, the input ‘x’ is processed through a series of operations: it is first multiplied by a weight matrix ‘W’ (MatMul), then added to a bias ‘b’ (Add), and finally passed to an activation function, Rectified Linear Unit (ReLU). This sequence of operations gives us the output C. The graph’s differentiable nature means that each operation has a well-defined gradient. Automatic differentiation, as implemented in ML frameworks, leverages this property to efficiently compute the gradients of the loss with respect to each parameter in the network (e.g., ‘W’ and ‘b’).
7.4 Training Data
To enable effective neural network training, the available data must be split into training, validation, and test sets. The training set is used to train the model parameters. The validation set evaluates the model during training to tune hyperparameters and prevent overfitting. The test set provides an unbiased final evaluation of the trained model’s performance.
Maintaining clear splits between train, validation, and test sets with representative data is crucial to properly training, tuning, and evaluating models to achieve the best real-world performance. To this end, we will learn about the common pitfalls or mistakes people make when creating these data splits.
Table 7.1 compares the differences between training, validation, and test data splits:
| Data Split | Purpose | Typical Size |
|---|---|---|
| Training Set | Train the model parameters | 60-80% of total data |
| Validation Set | Evaluate model during training to tune hyperparameters and prevent overfitting | ∼20% of total data |
| Test Set | Provide unbiased evaluation of final trained model | ∼20% of total data |
7.4.1 Dataset Splits
Training Set
The training set is used to train the model. It is the largest subset, typically 60-80% of the total data. The model sees and learns from the training data to make predictions. A sufficiently large and representative training set is required for the model to learn the underlying patterns effectively.
Validation Set
The validation set evaluates the model during training, usually after each epoch. Typically, 20% of the data is allocated for the validation set. The model does not learn or update its parameters based on the validation data. It is used to tune hyperparameters and make other tweaks to improve training. Monitoring metrics like loss and accuracy on the validation set prevents overfitting on just the training data.
Test Set
The test set acts as a completely unseen dataset that the model did not see during training. It is used to provide an unbiased evaluation of the final trained model. Typically, 20% of the data is reserved for testing. Maintaining a hold-out test set is vital for obtaining an accurate estimate of how the trained model would perform on real-world unseen data. Data leakage from the test set must be avoided at all costs.
The relative proportions of the training, validation, and test sets can vary based on data size and application. However, following the general guidelines for a 60/20/20 split is a good starting point. Careful data splitting ensures models are properly trained, tuned, and evaluated to achieve the best performance.
Video 7.1 explains how to properly split the dataset into training, validation, and testing sets, ensuring an optimal training process.
7.4.2 Common Pitfalls and Mistakes
Insufficient Training Data
Allocating too little data to the training set is a common mistake when splitting data that can severely impact model performance. If the training set is too small, the model will not have enough samples to effectively learn the true underlying patterns in the data. This leads to high variance and causes the model to fail to generalize well to new data.
For example, if you train an image classification model to recognize handwritten digits, providing only 10 or 20 images per digit class would be completely inadequate. The model would need more examples to capture the wide variances in writing styles, rotations, stroke widths, and other variations.
As a rule of thumb, the training set size should be at least hundreds or thousands of examples for most machine learning algorithms to work effectively. Due to the large number of parameters, the training set often needs to be in the tens or hundreds of thousands for deep neural networks, especially those using convolutional layers.
Insufficient training data typically manifests in symptoms like high error rates on validation/test sets, low model accuracy, high variance, and overfitting on small training set samples. Collecting more quality training data is the solution. Data augmentation techniques can also help virtually increase the size of training data for images, audio, etc.
Carefully factoring in the model complexity and problem difficulty when allocating training samples is important to ensure sufficient data is available for the model to learn successfully. Following guidelines on minimum training set sizes for different algorithms is also recommended. More training data is needed to maintain the overall success of any machine learning application.
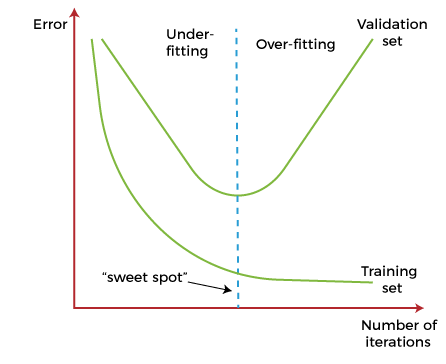
Consider Figure 7.4 where we try to classify/split datapoints into two categories (here, by color): On the left, overfitting is depicted by a model that has learned the nuances in the training data too well (either the dataset was too small or we ran the model for too long), causing it to follow the noise along with the signal, as indicated by the line’s excessive curves. The right side shows underfitting, where the model’s simplicity prevents it from capturing the dataset’s underlying structure, resulting in a line that does not fit the data well. The center graph represents an ideal fit, where the model balances well between generalization and fitting, capturing the main trend of the data without being swayed by outliers. Although the model is not a perfect fit (it misses some points), we care more about its ability to recognize general patterns rather than idiosyncratic outliers.
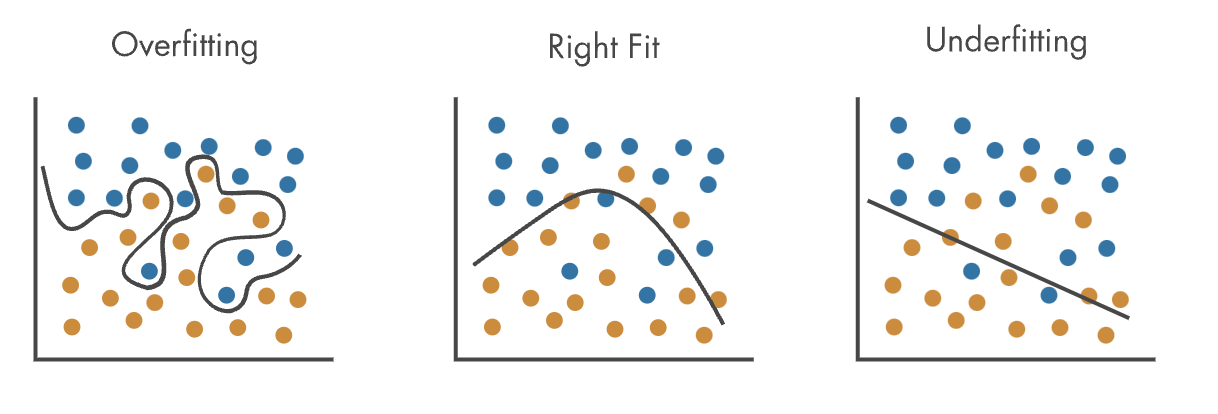
Figure 7.5 illustrates the process of fitting the data over time. When training, we search for the “sweet spot” between underfitting and overfitting. At first when the model hasn’t had enough time to learn the patterns in the data, we find ourselves in the underfitting zone, indicated by high error rates on the validation set (remember that the model is trained on the training set and we test its generalizability on the validation set, or data it hasn’t seen before). At some point, we achieve a global minimum for error rates, and ideally we want to stop the training there. If we continue training, the model will start “memorizing” or getting to know the data too well that the error rate starts going back up, since the model will fail to generalize to data it hasn’t seen before.
Video 7.2 provides an overview of bias and variance and the relationship between the two concepts and model accuracy.
Data Leakage Between Sets
Data leakage refers to the unintentional transfer of information between the training, validation, and test sets. This violates the fundamental assumption that the splits are mutually exclusive. Data leakage leads to seriously compromised evaluation results and inflated performance metrics.
A common way data leakage occurs is if some samples from the test set are inadvertently included in the training data. When evaluating the test set, the model has already seen some of the data, which gives overly optimistic scores. For example, if 2% of the test data leaks into the training set of a binary classifier, it can result in an accuracy boost of up to 20%!
If the data splits are not done carefully, more subtle forms of leakage can happen. If the splits are not properly randomized and shuffled, samples that are close to each other in the dataset may end up in the same split, leading to distribution biases. This creates information bleed through based on proximity in the dataset.
Another case is when datasets have linked, inherently connected samples, such as graphs, networks, or time series data. Naive splitting may isolate connected nodes or time steps into different sets. Models can make invalid assumptions based on partial information.
Preventing data leakage requires creating solid separation between splits—no sample should exist in more than one split. Shuffling and randomized splitting help create robust divisions. Cross-validation techniques can be used for more rigorous evaluation. Detecting leakage is difficult, but telltale signs include models doing way better on test vs. validation data.
Data leakage severely compromises the validity of the evaluation because the model has already partially seen the test data. No amount of tuning or complex architectures can substitute for clean data splits. It is better to be conservative and create complete separation between splits to avoid this fundamental mistake in machine learning pipelines.
Small or Unrepresentative Validation Set
The validation set is used to assess model performance during training and to fine-tune hyperparameters. For reliable and stable evaluations, the validation set should be sufficiently large and representative of the real data distribution. However, this can make model selection and tuning more challenging.
For example, if the validation set only contains 100 samples, the metrics calculated will have a high variance. Due to noise, the accuracy may fluctuate up to 5-10% between epochs. This makes it difficult to know if a drop in validation accuracy is due to overfitting or natural variance. With a larger validation set, say 1000 samples, the metrics will be much more stable.
Additionally, if the validation set is not representative, perhaps missing certain subclasses, the estimated skill of the model may be inflated. This could lead to poor hyperparameter choices or premature training stops. Models selected based on such biased validation sets do not generalize well to real data.
A good rule of thumb is that the validation set size should be at least several hundred samples and up to 10-20% of the training set, while still leaving sufficient samples for training. The splits should also be stratified, meaning that the class proportions in the validation set should match those in the full dataset, especially if working with imbalanced datasets. A larger validation set representing the original data characteristics is essential for proper model selection and tuning.
Reusing the Test Set Multiple Times
The test set is designed to provide an unbiased evaluation of the fully trained model only once at the end of the model development process. Reusing the test set multiple times during development for model evaluation, hyperparameter tuning, model selection, etc., can result in overfitting on the test data. Instead, reserve the test set for a final evaluation of the fully trained model, treating it as a black box to simulate its performance on real-world data. This approach provides reliable metrics to determine whether the model is ready for production deployment.
If the test set is reused as part of the validation process, the model may start to see and learn from the test samples. This, coupled with intentionally or unintentionally optimizing model performance on the test set, can artificially inflate metrics like accuracy.
For example, suppose the test set is used repeatedly for model selection out of 5 architectures. In that case, the model may achieve 99% test accuracy by memorizing the samples rather than learning generalizable patterns. However, when deployed in the real world, the accuracy of new data could drop by 60%.
The best practice is to interact with the test set only once at the end to report unbiased metrics on how the final tuned model would perform in the real world. While developing the model, the validation set should be used for all parameter tuning, model selection, early stopping, and similar tasks. It’s important to reserve a portion, such as 20-30% of the full dataset, solely for the final model evaluation. This data should not be used for validation, tuning, or model selection during development.
Failing to keep an unseen hold-out set for final validation risks optimizing results and overlooking potential failures before model release. Having some fresh data provides a final sanity check on real-world efficacy. Maintaining the complete separation of training/validation from the test set is essential to obtain accurate estimates of model performance. Even minor deviations from a single use of the test set could positively bias results and metrics, providing an overly optimistic view of real-world efficacy.
Same Data Splits Across Experiments
When comparing different machine learning models or experimenting with various architectures and hyperparameters, using the same data splits for training, validation, and testing across the different experiments can introduce bias and invalidate the comparisons.
If the same splits are reused, the evaluation results may be more balanced and accurately measure which model performs better. For example, a certain random data split may favor model A over model B irrespective of the algorithms. Reusing this split will then bias towards model A.
Instead, the data splits should be randomized or shuffled for each experimental iteration. This ensures that randomness in the sampling of the splits does not confer an unfair advantage to any model.
With different splits per experiment, the evaluation becomes more robust. Each model is tested on a wide range of test sets drawn randomly from the overall population, smoothing out variation and removing correlation between results.
Proper practice is to set a random seed before splitting the data for each experiment. Splitting should occur after shuffling/resampling as part of the experimental pipeline. Carrying out comparisons on the same splits violates the i.i.d (independent and identically distributed) assumption required for statistical validity.
Unique splits are essential for fair model comparisons. Though more compute-intensive, randomized allocation per experiment removes sampling bias and enables valid benchmarking. This highlights the true differences in model performance irrespective of a particular split’s characteristics.
Failing to Stratify Splits
When splitting data into training, validation, and test sets, failing to stratify the splits can result in an uneven representation of the target classes across the splits and introduce sampling bias. This is especially problematic for imbalanced datasets.
Stratified splitting involves sampling data points such that the proportion of output classes is approximately preserved in each split. For example, if performing a 70/30 train-test split on a dataset with 60% negative and 40% positive samples, stratification ensures ~60% negative and ~40% positive examples in both training and test sets.
Without stratification, random chance could result in the training split having 70% positive samples while the test has 30% positive samples. The model trained on this skewed training distribution will not generalize well. Class imbalance also compromises model metrics like accuracy.
Stratification works best when done using labels, though proxies like clustering can be used for unsupervised learning. It becomes essential for highly skewed datasets with rare classes that could easily be omitted from splits.
Libraries like Scikit-Learn have stratified splitting methods built into them. Failing to use them could inadvertently introduce sampling bias and hurt model performance on minority groups. After performing the splits, the overall class balance should be examined to ensure even representation across the splits.
Stratification provides a balanced dataset for both model training and evaluation. Though simple random splitting is easy, mindful of stratification needs, especially for real-world imbalanced data, results in more robust model development and evaluation.
Ignoring Time Series Dependencies
Time series data has an inherent temporal structure with observations depending on past context. Naively splitting time series data into train and test sets without accounting for this dependency leads to data leakage and lookahead bias.
For example, simply splitting a time series into the first 70% of training and the last 30% as test data will contaminate the training data with future data points. The model can use this information to “peek” ahead during training.
This results in an overly optimistic evaluation of the model’s performance. The model may appear to forecast the future accurately but has actually implicitly learned based on future data, which does not translate to real-world performance.
Proper time series cross-validation techniques, such as forward chaining, should be used to preserve order and dependency. The test set should only contain data points from a future time window that the model was not exposed to for training.
Failing to account for temporal relationships leads to invalid causality assumptions. If the training data contains future points, the model may also need to learn how to extrapolate forecasts further.
Maintaining the temporal flow of events and avoiding lookahead bias is key to properly training and testing time series models. This ensures they can truly predict future patterns and not just memorize past training data.
No Unseen Data for Final Evaluation
A common mistake when splitting data is failing to set aside some portion of the data just for the final evaluation of the completed model. All of the data is used for training, validation, and test sets during development.
This leaves no unseen data to get an unbiased estimate of how the final tuned model would perform in the real world. The metrics on the test set used during development may only partially reflect actual model skills.
For example, choices like early stopping and hyperparameter tuning are often optimized based on test set performance. This couples the model to the test data. An unseen dataset is needed to break this coupling and get true real-world metrics.
Best practice is to reserve a portion, such as 20-30% of the full dataset, solely for final model evaluation. This data should not be used for validation, tuning, or model selection during development.
Saving some unseen data allows for evaluating the completely trained model as a black box on real-world data. This provides reliable metrics to decide whether the model is ready for production deployment.
Failing to keep an unseen hold-out set for final validation risks optimizing results and overlooking potential failures before model release. Having some fresh data provides a final sanity check on real-world efficacy.
Overoptimizing on the Validation Set
The validation set is meant to guide the model training process, not serve as additional training data. Overoptimizing the validation set to maximize performance metrics treats it more like a secondary training set, leading to inflated metrics and poor generalization.
For example, techniques like extensively tuning hyperparameters or adding data augmentations targeted to boost validation accuracy can cause the model to fit too closely to the validation data. The model may achieve 99% validation accuracy but only 55% test accuracy.
Similarly, reusing the validation set for early stopping can also optimize the model specifically for that data. Stopping at the best validation performance overfits noise and fluctuations caused by the small validation size.
The validation set serves as a proxy to tune and select models. However, the goal remains maximizing real-world data performance, not the validation set. Minimizing the loss or error on validation data does not automatically translate to good generalization.
A good approach is to keep the use of the validation set minimal—hyperparameters can be tuned coarsely first on training data, for example. The validation set guides the training but should not influence or alter the model itself. It is a diagnostic, not an optimization tool.
When assessing performance on the validation set, care should be taken not to overfit. Tradeoffs are needed to build models that perform well on the overall population and are not overly tuned to the validation samples.
7.5 Optimization Algorithms
Stochastic gradient descent (SGD) is a simple yet powerful optimization algorithm for training machine learning models. It works by estimating the gradient of the loss function concerning the model parameters using a single training example and then updating the parameters in the direction that reduces the loss.
While conceptually straightforward, SGD needs a few areas for improvement. First, choosing a proper learning rate can be difficult—too small, and progress is very slow; too large, and parameters may oscillate and fail to converge. Second, SGD treats all parameters equally and independently, which may not be ideal in all cases. Finally, vanilla SGD uses only first-order gradient information, which results in slow progress on ill-conditioned problems.
7.5.1 Optimizations
Over the years, various optimizations have been proposed to accelerate and improve vanilla SGD. Ruder (2016) gives an excellent overview of the different optimizers. Briefly, several commonly used SGD optimization techniques include:
Momentum: Accumulates a velocity vector in directions of persistent gradient across iterations. This helps accelerate progress by dampening oscillations and maintains progress in consistent directions.
Nesterov Accelerated Gradient (NAG): A variant of momentum that computes gradients at the “look ahead” rather than the current parameter position. This anticipatory update prevents overshooting while the momentum maintains the accelerated progress.
Adagrad: An adaptive learning rate algorithm that maintains a per-parameter learning rate scaled down proportionate to each parameter’s historical sum of gradients. This helps eliminate the need to tune learning rates (Duchi, Hazan, and Singer 2010) manually.
Adadelta: A modification to Adagrad restricts the window of accumulated past gradients, thus reducing the aggressive decay of learning rates (Zeiler 2012).
RMSProp: Divides the learning rate by an exponentially decaying average of squared gradients. This has a similar normalizing effect as Adagrad but does not accumulate the gradients over time, avoiding a rapid decay of learning rates (Hinton 2017).
Adam: Combination of momentum and rmsprop where rmsprop modifies the learning rate based on the average of recent magnitudes of gradients. Displays very fast initial progress and automatically tunes step sizes (Kingma and Ba 2014).
AMSGrad: A variant of Adam that ensures stable convergence by maintaining the maximum of past squared gradients, preventing the learning rate from increasing during training (Reddi, Kale, and Kumar 2019).
Of these methods, Adam has widely considered the go-to optimization algorithm for many deep-learning tasks. It consistently outperforms vanilla SGD in terms of training speed and performance. Other optimizers may be better suited in some cases, particularly for simpler models.
7.5.2 Tradeoffs
Table 7.2 is a pros and cons table for some of the main optimization algorithms for neural network training:
| Algorithm | Pros | Cons |
|---|---|---|
| Momentum |
|
|
| Nesterov Accelerated Gradient (NAG) |
|
|
| Adagrad |
|
|
| Adadelta |
|
|
| RMSProp |
|
|
| Adam |
|
|
| AMSGrad |
|
|
7.5.3 Benchmarking Algorithms
No single method is best for all problem types. This means we need comprehensive benchmarking to identify the most effective optimizer for specific datasets and models. The performance of algorithms like Adam, RMSProp, and Momentum varies due to batch size, learning rate schedules, model architecture, data distribution, and regularization. These variations underline the importance of evaluating each optimizer under diverse conditions.
Take Adam, for example, who often excels in computer vision tasks, unlike RMSProp, who may show better generalization in certain natural language processing tasks. Momentum’s strength lies in its acceleration in scenarios with consistent gradient directions, whereas Adagrad’s adaptive learning rates are more suited for sparse gradient problems.
This wide array of interactions among optimizers demonstrates the challenge of declaring a single, universally superior algorithm. Each optimizer has unique strengths, making it crucial to evaluate various methods to discover their optimal application conditions empirically.
A comprehensive benchmarking approach should assess the speed of convergence and factors like generalization error, stability, hyperparameter sensitivity, and computational efficiency, among others. This entails monitoring training and validation learning curves across multiple runs and comparing optimizers on various datasets and models to understand their strengths and weaknesses.
AlgoPerf, introduced by Dürr et al. (2021), addresses the need for a robust benchmarking system. This platform evaluates optimizer performance using criteria such as training loss curves, generalization error, sensitivity to hyperparameters, and computational efficiency. AlgoPerf tests various optimization methods, including Adam, LAMB, and Adafactor, across different model types like CNNs and RNNs/LSTMs on established datasets. It utilizes containerization and automatic metric collection to minimize inconsistencies and allows for controlled experiments across thousands of configurations, providing a reliable basis for comparing optimizers.
The insights gained from AlgoPerf and similar benchmarks are invaluable for guiding optimizers’ optimal choice or tuning. By enabling reproducible evaluations, these benchmarks contribute to a deeper understanding of each optimizer’s performance, paving the way for future innovations and accelerated progress in the field.
7.6 Hyperparameter Tuning
Hyperparameters are important settings in machine learning models that greatly impact how well your models ultimately perform. Unlike other model parameters that are learned during training, hyperparameters are specified by the data scientists or machine learning engineers before training the model.
Choosing the right hyperparameter values enables your models to learn patterns from data effectively. Some examples of key hyperparameters across ML algorithms include:
- Neural networks: Learning rate, batch size, number of hidden units, activation functions
- Support vector machines: Regularization strength, kernel type and parameters
- Random forests: Number of trees, tree depth
- K-means: Number of clusters
The problem is that there are no reliable rules of thumb for choosing optimal hyperparameter configurations—you typically have to try out different values and evaluate performance. This process is called hyperparameter tuning.
In the early years of modern deep learning, researchers were still grappling with unstable and slow convergence issues. Common pain points included training losses fluctuating wildly, gradients exploding or vanishing, and extensive trial-and-error needed to train networks reliably. As a result, an early focal point was using hyperparameters to control model optimization. For instance, seminal techniques like batch normalization allowed faster model convergence by tuning aspects of internal covariate shift. Adaptive learning rate methods also mitigated the need for extensive manual schedules. These addressed optimization issues during training, such as uncontrolled gradient divergence. Carefully adapted learning rates are also the primary control factor for achieving rapid and stable convergence even today.
As computational capacity expanded exponentially in subsequent years, much larger models could be trained without falling prey to pure numerical optimization issues. The focus shifted towards generalization - though efficient convergence was a core prerequisite. State-of-the-art techniques like Transformers brought in parameters in billions. At such sizes, hyperparameters around capacity, regularization, ensembling, etc., took center stage for tuning rather than only raw convergence metrics.
The lesson is that understanding the acceleration and stability of the optimization process itself constitutes the groundwork. Initialization schemes, batch sizes, weight decays, and other training hyperparameters remain indispensable today. Mastering fast and flawless convergence allows practitioners to expand their focus on emerging needs around tuning for metrics like accuracy, robustness, and efficiency at scale.
7.6.1 Search Algorithms
When it comes to the critical process of hyperparameter tuning, there are several sophisticated algorithms that machine learning practitioners rely on to search through the vast space of possible model configurations systematically. Some of the most prominent hyperparameter search algorithms include:
Grid Search: The most basic search method, where you manually define a grid of values to check for each hyperparameter. For example, checking
learning rates = [0.01, 0.1, 1]and batchsizes = [32, 64, 128]. The key advantage is simplicity, but it can lead to an exponential explosion in search space, making it time-consuming. It’s best suited for fine-tuning a small number of parameters.Random Search: Instead of defining a grid, you randomly select values for each hyperparameter from a predefined range or set. This method is more efficient at exploring a vast hyperparameter space because it doesn’t require an exhaustive search. However, it may still miss optimal parameters since it doesn’t systematically explore all possible combinations.
Bayesian Optimization: This is an advanced probabilistic approach for adaptive exploration based on a surrogate function to model performance over iterations. It is simple and efficient—it finds highly optimized hyperparameters in fewer evaluation steps. However, it requires more investment in setup (Snoek, Larochelle, and Adams 2012).
Evolutionary Algorithms: These algorithms mimic natural selection principles. They generate populations of hyperparameter combinations and evolve them over time-based on performance. These algorithms offer robust search capabilities better suited for complex response surfaces. However, many iterations are required for reasonable convergence.
Population Based Training (PBT): A method that optimizes hyperparameters by training multiple models in parallel, allowing them to share and adapt successful configurations during training, combining elements of random search and evolutionary algorithms (Jaderberg et al. 2017).
Neural Architecture Search: An approach to designing well-performing architectures for neural networks. Traditionally, NAS approaches use some form of reinforcement learning to propose neural network architectures, which are then repeatedly evaluated (Zoph and Le 2016).
7.6.2 System Implications
Hyperparameter tuning can significantly impact time to convergence during model training, directly affecting overall runtime. The right values for key training hyperparameters are crucial for efficient model convergence. For example, the hyperparameter’s learning rate controls the step size during gradient descent optimization. Setting a properly tuned learning rate schedule ensures the optimization algorithm converges quickly towards a good minimum. Too small a learning rate leads to painfully slow convergence, while too large a value causes the losses to fluctuate wildly. Proper tuning ensures rapid movement towards optimal weights and biases.
Similarly, the batch size for stochastic gradient descent impacts convergence stability. The right batch size smooths out fluctuations in parameter updates to approach the minimum faster. More batch sizes are needed to avoid noisy convergence, while large batch sizes fail to generalize and slow down convergence due to less frequent parameter updates. Tuning hyperparameters for faster convergence and reduced training duration has direct implications on cost and resource requirements for scaling machine learning systems:
Lower computational costs: Shorter time to convergence means lower computational costs for training models. ML training often leverages large cloud computing instances like GPU and TPU clusters that incur heavy hourly charges. Minimizing training time directly reduces this resource rental cost, which tends to dominate ML budgets for organizations. Quicker iteration also lets data scientists experiment more freely within the same budget.
Reduced training time: Reduced training time unlocks opportunities to train more models using the same computational budget. Optimized hyperparameters stretch available resources further, allowing businesses to develop and experiment with more models under resource constraints to maximize performance.
Resource efficiency: Quicker training allows allocating smaller compute instances in the cloud since models require access to the resources for a shorter duration. For example, a one-hour training job allows using less powerful GPU instances compared to multi-hour training, which requires sustained compute access over longer intervals. This achieves cost savings, especially for large workloads.
There are other benefits as well. For instance, faster convergence reduces pressure on ML engineering teams regarding provisioning training resources. Simple model retraining routines can use lower-powered resources instead of requesting access to high-priority queues for constrained production-grade GPU clusters, freeing up deployment resources for other applications.
7.6.3 Auto Tuners
Given its importance, there is a wide array of commercial offerings to help with hyperparameter tuning. We will briefly touch on two examples: one focused on optimization for cloud-scale ML and the other for machine learning models targeting microcontrollers. Table 7.3 outlines the key differences:
| Platform | Target Use Case | Optimization Techniques | Benefits |
|---|---|---|---|
| Google’s Vertex AI | Cloud-scale machine learning | Bayesian optimization, Population-Based training | Hides complexity, enabling fast, deployment-ready models with state-of-the-art hyperparameter optimization |
| Edge Impulse’s EON Tuner | Microcontroller (TinyML) models | Bayesian optimization | Tailors models for resource-constrained devices, simplifies optimization for embedded deployment |
BigML
Several commercial auto-tuning platforms are available to address this problem. One solution is Google’s Vertex AI Cloud, which has extensive integrated support for state-of-the-art tuning techniques.
One of the most salient capabilities of Google’s Vertex AI-managed machine learning platform is efficient, integrated hyperparameter tuning for model development. Successfully training performant ML models requires identifying optimal configurations for a set of external hyperparameters that dictate model behavior, posing a challenging high-dimensional search problem. Vertex AI simplifies this through Automated Machine Learning (AutoML) tooling.
Specifically, data scientists can leverage Vertex AI’s hyperparameter tuning engines by providing a labeled dataset and choosing a model type such as a Neural Network or Random Forest classifier. Vertex launches a Hyperparameter Search job transparently on the backend, fully handling resource provisioning, model training, metric tracking, and result analysis automatically using advanced optimization algorithms.
Under the hood, Vertex AutoML employs various search strategies to intelligently explore the most promising hyperparameter configurations based on previous evaluation results. Among these, Bayesian Optimization is offered as it provides superior sample efficiency, requiring fewer training iterations to achieve optimized model quality compared to standard Grid Search or Random Search methods. For more complex neural architecture search spaces, Vertex AutoML utilizes Population-Based Training, which simultaneously trains multiple models and dynamically adjusts their hyperparameters by leveraging the performance of other models in the population, analogous to natural selection principles.
Vertex AI democratizes state-of-the-art hyperparameter search techniques at the cloud scale for all ML developers, abstracting away the underlying orchestration and execution complexity. Users focus solely on their dataset, model requirements, and accuracy goals, while Vertex manages the tuning cycle, resource allocation, model training, accuracy tracking, and artifact storage under the hood. The result is getting deployment-ready, optimized ML models faster for the target problem.
TinyML
Edge Impulse’s Efficient On-device Neural Network Tuner (EON Tuner) is an automated hyperparameter optimization tool designed to develop microcontroller machine learning models. It streamlines the model development process by automatically finding the best neural network configuration for efficient and accurate deployment on resource-constrained devices.
The key functionality of the EON Tuner is as follows. First, developers define the model hyperparameters, such as number of layers, nodes per layer, activation functions, and learning rate annealing schedule. These parameters constitute the search space that will be optimized. Next, the target microcontroller platform is selected, providing embedded hardware constraints. The user can also specify optimization objectives, such as minimizing memory footprint, lowering latency, reducing power consumption, or maximizing accuracy.
With the defined search space and optimization goals, the EON Tuner leverages Bayesian hyperparameter optimization to explore possible configurations intelligently. Each prospective configuration is automatically implemented as a full model specification, trained, and evaluated for quality metrics. The continual process balances exploration and exploitation to arrive at optimized settings tailored to the developer’s chosen chip architecture and performance requirements.
The EON Tuner frees machine learning engineers from the demandingly iterative process of hand-tuning models by automatically tuning models for embedded deployment. The tool integrates seamlessly into the Edge Impulse workflow, taking models from concept to efficiently optimized implementations on microcontrollers. The expertise encapsulated in EON Tuner regarding ML model optimization for microcontrollers ensures beginner and experienced developers alike can rapidly iterate to models fitting their project needs.
Get ready to unlock the secrets of hyperparameter tuning and take your PyTorch models to the next level! Hyperparameters are like the hidden dials and knobs that control your model’s learning superpowers. In this Colab notebook, you’ll team up with Ray Tune to find those perfect hyperparameter combinations. Learn how to define what values to search through, set up your training code for optimization, and let Ray Tune do the heavy lifting. By the end, you’ll be a hyperparameter tuning pro!
![]()
Video 7.3 explains the systematic organization of the hyperparameter tuning process.
7.7 Regularization
Regularization is a critical technique for improving the performance and generalizability of machine learning models in applied settings. It refers to mathematically constraining or penalizing model complexity to avoid overfitting the training data. Without regularization, complex ML models are prone to overfitting the dataset and memorizing peculiarities and noise in the training set rather than learning meaningful patterns. They may achieve high training accuracy but perform poorly when evaluating new unseen inputs.
Regularization helps address this problem by placing constraints that favor simpler, more generalizable models that don’t latch onto sampling errors. Techniques like L1/L2 regularization directly penalize large parameter values during training, forcing the model to use the smallest parameters that can adequately explain the signal. Early stopping rules halt training when validation set performance stops improving - before the model starts overfitting.
Appropriate regularization is crucial when deploying models to new user populations and environments where distribution shifts are likely. For example, an irregularized fraud detection model trained at a bank may work initially but accrue technical debt over time as new fraud patterns emerge.
Regularizing complex neural networks also offers computational advantages—smaller models require less data augmentation, compute power, and data storage. Regularization also allows for more efficient AI systems, where accuracy, robustness, and resource management are thoughtfully balanced against training set limitations.
Several powerful regularization techniques are commonly used to improve model generalization. Architecting the optimal strategy requires understanding how each method affects model learning and complexity.
7.7.1 L1 and L2
Two of the most widely used regularization forms are L1 and L2 regularization. Both penalize model complexity by adding an extra term to the cost function optimized during training. This term grows larger as model parameters increase.
L2 regularization, also known as ridge regression, adds the sum of squared magnitudes of all parameters multiplied by a coefficient α. This quadratic penalty curtails extreme parameter values more aggressively than L1 techniques. Implementation requires only changing the cost function and tuning α.
\[R_{L2}(\Theta) = \alpha \sum_{i=1}^{n}\theta_{i}^2\]
Where:
- \(R_{L2}(\Theta)\) - The L2 regularization term that is added to the cost function
- \(\alpha\) - The L2 regularization hyperparameter that controls the strength of regularization
- \(\theta_{i}\) - The ith model parameter
- \(n\) - The number of parameters in the model
- \(\theta_{i}^2\) - The square of each parameter
And the full L2 regularized cost function is:
\[J(\theta) = L(\theta) + R_{L2}(\Theta)\]
Where:
- \(L(\theta)\) - The original unregularized cost function
- \(J(\theta)\) - The new regularized cost function
Both L1 and L2 regularization penalize large weights in the neural network. However, the key difference between L1 and L2 regularization is that L2 regularization penalizes the squares of the parameters rather than the absolute values. This key difference has a considerable impact on the resulting regularized weights. L1 regularization, or lasso regression, utilizes the absolute sum of magnitudes rather than the square multiplied by α. Penalizing the absolute value of weights induces sparsity since the gradient of the errors extrapolates linearly as the weight terms tend towards zero; this is unlike penalizing the squared value of the weights, where the penalty reduces as the weights tend towards 0. By inducing sparsity in the parameter vector, L1 regularization automatically performs feature selection, setting the weights of irrelevant features to zero. Unlike L2 regularization, L1 regularization leads to sparsity as weights are set to 0; in L2 regularization, weights are set to a value very close to 0 but generally never reach exact 0. L1 regularization encourages sparsity and has been used in some works to train sparse networks that may be more hardware efficient (Hoefler et al. 2021).
\[R_{L1}(\Theta) = \alpha \sum_{i=1}^{n}||\theta_{i}||\]
Where:
- \(R_{L1}(\Theta)\) - The L1 regularization term that is added to the cost function
- \(\alpha\) - The L1 regularization hyperparameter that controls the strength of regularization
- \(\theta_{i}\) - The i-th model parameter
- \(n\) - The number of parameters in the model
- \(||\theta_{i}||\) - The L1 norm, which takes the absolute value of each parameter
And the full L1 regularized cost function is:
\[J(\theta) = L(\theta) + R_{L1}(\Theta)\]
Where:
- \(L(\theta)\) - The original unregularized cost function
- \(J(\theta)\) - The new regularized cost function
The choice between L1 and L2 depends on the expected model complexity and whether intrinsic feature selection is needed. Both require iterative tuning across a validation set to select the optimal α hyperparameter.
Video 7.4 and Video 7.5 explains how regularization works.
Video 7.5 explains how regularization can help reduce model overfitting to improve performance.
7.7.2 Dropout
Another widely adopted regularization method is dropout (Srivastava et al. 2014). During training, dropout randomly sets a fraction \(p\) of node outputs or hidden activations to zero. This encourages greater information distribution across more nodes rather than reliance on a small number of nodes. Come prediction time; the full neural network is used, with intermediate activations scaled by \(1 - p\) to maintain output magnitudes. GPU optimizations make implementing dropout efficiently straightforward via frameworks like PyTorch and TensorFlow.
Let’s be more pedantic. During training with dropout, each node’s output \(a_i\) is passed through a dropout mask \(r_i\) before being used by the next layer:
\[ ã_i = r_i \odot a_i \]
Where:
- \(a_i\) - output of node \(i\)
- \(ã_i\) - output of node \(i\) after dropout
- \(r_i\) - independent Bernoulli random variable with probability \(1 - p\) of being 1
- \(\odot\) - elementwise multiplication
To understand how dropout works, it’s important to know that the dropout mask \(r_i\) is based on Bernoulli random variables. A Bernoulli random variable takes a value of 1 with probability \(1-p\) (keeping the activation) and a value of 0 with probability \(p\) (dropping the activation). This means that each node’s activation is independently either kept or dropped during training. This dropout mask \(r_i\) randomly sets a fraction \(p\) of activations to 0 during training, forcing the network to make redundant representations.
At test time, the dropout mask is removed, and the activations are rescaled by \(1 - p\) to maintain expected output magnitudes:
\[ a_i^{test} = (1 - p) a_i\]
Where:
- \(a_i^{test}\) - node output at test time
- \(p\) - the probability of dropping a node.
The key hyperparameter is \(p\), the probability of dropping each node,, often set between 0.2 and 0.5. Larger networks tend to benefit from more dropout, while small networks risk underfitting if too many nodes are cut out. Trial and error combined with monitoring validation performance helps tune the dropout level.
Video 7.6 discusses the intuition behind the dropout regularization technique and how it works.
7.7.3 Early Stopping
The intuition behind early stopping involves tracking model performance on a held-out validation set across training epochs. At first, increases in training set fitness accompany gains in validation accuracy as the model picks up generalizable patterns. After some point, however, the model starts overfitting - latching onto peculiarities and noise in the training data that don’t apply more broadly. The validation performance peaks and then degrades if training continues. Early stopping rules halt training at this peak to prevent overfitting. This technique demonstrates how ML pipelines must monitor system feedback, not just unquestioningly maximize performance on a static training set. The system’s state evolves, and the optimal endpoints change.
Therefore, formal early stopping methods require monitoring a metric like validation accuracy or loss after each epoch. Common curves exhibit rapid initial gains that taper off, eventually plateauing and decreasing slightly as overfitting occurs. The optimal stopping point is often between 5 and 15 epochs past the peak, depending on patient thresholds. Tracking multiple metrics can improve signal since variance exists between measures.
Simple, early-stopping rules stop immediately at the first post-peak degradation. More robust methods introduce a patience parameter—the number of degrading epochs permitted before stopping. This avoids prematurely halting training due to transient fluctuations. Typical patience windows range from 50 to 200 validation batches. Wider windows incur the risk of overfitting. Formal tuning strategies can determine optimal patience.
Battling Overfitting: Unlock the Secrets of Regularization! Overfitting is like your model memorizing the answers to a practice test, then failing the real exam. Regularization techniques are the study guides that help your model generalize and ace new challenges. In this Colab notebook, you’ll learn how to tune regularization parameters for optimal results using L1 & L2 regularization, dropout, and early stopping.
![]()
Video 7.7 covers a few other regularization methods that can reduce model overfitting.
7.8 Activation Functions
Activation functions play a crucial role in neural networks. They introduce nonlinear behaviors that allow neural nets to model complex patterns. Element-wise activation functions are applied to the weighted sums coming into each neuron in the network. Without activation functions, neural nets would be reduced to linear regression models.
Ideally, activation functions possess certain desirable qualities:
- Nonlinear: They enable modeling complex relationships through nonlinear transformations of the input sum.
- Differentiable: They must have well-defined first derivatives to enable backpropagation and gradient-based optimization during training.
- Range-bounding: They constrain the output signal, preventing an explosion. For example, sigmoid squashes inputs to (0,1).
Additionally, properties like computational efficiency, monotonicity, and smoothness make some activations better suited over others based on network architecture and problem complexity.
We will briefly survey some of the most widely adopted activation functions and their strengths and limitations. We will also provide guidelines for selecting appropriate functions matched to ML system constraints and use case needs.
7.8.1 Sigmoid
The sigmoid activation applies a squashing S-shaped curve tightly binding the output between 0 and 1. It has the mathematical form:
\[ sigmoid(x) = \frac{1}{1+e^{-x}} \]
The exponentiation transform allows the function to smoothly transition from near 0 towards near 1 as the input moves from very negative to very positive. The monotonic rise covers the full (0,1) range.
The sigmoid function has several advantages. It always provides a smooth gradient for backpropagation, and its output is bounded between 0 and 1, which helps prevent “exploding” values during training. Additionally, it has a simple mathematical formula that is easy to compute.
However, the sigmoid function also has some drawbacks. It tends to saturate at extreme input values, which can cause gradients to “vanish,” slowing down or even stopping the learning process. Furthermore, the function is not zero-centered, meaning that its outputs are not symmetrically distributed around zero, which can lead to inefficient updates during training.
7.8.2 Tanh
Tanh or hyperbolic tangent also assumes an S-shape but is zero-centered, meaning the average output value is 0.
\[ tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} \]
The numerator/denominator transform shifts the range from (0,1) in Sigmoid to (-1, 1) in tanh.
Most pros/cons are shared with Sigmoid, but Tanh avoids some output saturation issues by being centered. However, it still suffers from vanishing gradients with many layers.
7.8.3 ReLU
The Rectified Linear Unit (ReLU) introduces a simple thresholding behavior with its mathematical form:
\[ ReLU(x) = max(0, x) \]
It leaves all positive inputs unchanged while clipping all negative values to 0. This sparse activation and cheap computation make ReLU widely favored over sigmoid/tanh.
Figure 7.6 demonstrates the 3 activation functions we discussed above in comparison to a linear function:
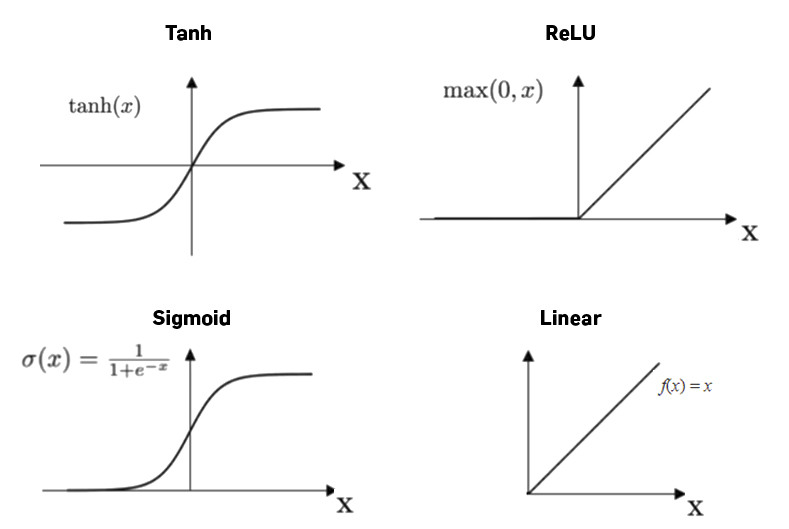
7.8.4 Softmax
The softmax activation function is generally used as the last layer for classification tasks to normalize the activation value vector so that its elements sum to 1. This is useful for classification tasks where we want to learn to predict class-specific probabilities of a particular input, in which case the cumulative probability across classes is equal to 1. The softmax activation function is defined as
\[\sigma(z_i) = \frac{e^{z_{i}}}{\sum_{j=1}^K e^{z_{j}}} \ \ \ for\ i=1,2,\dots,K\]
7.8.5 Pros and Cons
Table 7.4 are the summarizing pros and cons of these various standard activation functions:
| Activation | Pros | Cons |
|---|---|---|
| Sigmoid |
|
|
| Tanh |
|
|
| ReLU |
|
|
| Softmax |
|
Unlock the power of activation functions! These little mathematical workhorses are what make neural networks so incredibly flexible. In this Colab notebook, you’ll go hands-on with functions like the Sigmoid, tanh, and the superstar ReLU. See how they transform inputs and learn which works best in different situations. It’s the key to building neural networks that can tackle complex problems!
![]()
7.9 Weight Initialization
Proper initialization of the weights in a neural network before training is a vital step directly impacting model performance. Randomly initializing weights to very large or small values can lead to problems like vanishing/exploding gradients, slow convergence of training, or getting trapped in poor local minima. Proper weight initialization accelerates model convergence during training and carries implications for system performance at inference time in production environments. Some key aspects include:
Faster Time-to-Accuracy: Carefully tuned initialization leads to faster convergence, which results in models reaching target accuracy milestones earlier in the training cycle. For instance, Xavier initialization could reduce time-to-accuracy by 20% versus bad random initialization. As training is typically the most time- and compute-intensive phase, this directly enhances ML system velocity and productivity.
Model Iteration Cycle Efficiency: If models train faster, the overall turnaround time for experimentation, evaluation, and model design iterations decreases significantly. Systems have more flexibility to explore architectures, data pipelines, etc, within given timeframes.
Impact on Necessary Training Epochs: The training process runs for multiple epochs - with each full pass through the data being an epoch. Good Initialization can reduce the epochs required to converge the loss and accuracy curves on the training set by 10-30%. This means tangible resource and infrastructure cost savings.
Effect on Training Hyperparameters: Weight initialization parameters interact strongly with certain regularization hyperparameters that govern the training dynamics, like learning rate schedules and dropout probabilities. Finding the right combination of settings is non-trivial. Appropriate Initialization smoothens this search.
Weight initialization has cascading benefits for machine learning engineering efficiency and minimized system resource overhead. It is an easily overlooked tactic that every practitioner should master. The choice of which weight initialization technique to use depends on factors like model architecture (number of layers, connectivity pattern, etc.), activation functions, and the specific problem being solved. Over the years, researchers have developed and empirically verified different initialization strategies targeted to common neural network architectures, which we will discuss here.
7.9.1 Uniform and Normal Initialization
When randomly initializing weights, two standard probability distributions are commonly used - uniform and Gaussian (normal). The uniform distribution sets an equal probability of the initial weight parameters falling anywhere within set minimum and maximum bounds. For example, the bounds could be -1 and 1, leading to a uniform spread of weights between these limits. The Gaussian distribution, on the other hand, concentrates probability around a mean value, following the shape of a bell curve. Most weight values will cluster in the region of the specified mean, with fewer samples towards the extreme ends. The standard deviation parameter controls the spread around the mean.
The choice between uniform or normal initialization depends on the network architecture and activation functions. For shallow networks, a normal distribution with a relatively small standard deviation (e.g., 0.01) is recommended. The bell curve prevents large weight values that could trigger training instability in small networks. For deeper networks, a normal distribution with higher standard deviation (say 0.5 or above) or uniform distribution may be preferred to account for vanishing gradient issues over many layers. The larger spread drives greater differentiation between neuron behaviors. Fine-tuning the initialization distribution parameters is crucial for stable and speedy model convergence. Monitoring training loss trends can diagnose issues for tweaking the parameters iteratively.
7.9.2 Xavier Initialization
Proposed by Glorot and Bengio (2010), this initialization technique is specially designed for sigmoid and tanh activation functions. These saturated activations can cause vanishing or exploding gradients during backpropagation over many layers.
The Xavier method cleverly sets the variance of the weight distribution based on the number of inputs and outputs to each layer. The intuition is that this balances the flow of information and gradients throughout the network. For example, consider a layer with 300 input units and 100 output units. Plugging this into the formula variance = 2/(#inputs + #outputs) gives a variance of 2/(300+100) = 0.01.
Sampling the initial weights from a uniform or normal distribution centered at 0 with this variance provides much smoother training convergence for deep sigmoid/tanh networks. The gradients are well-conditioned, preventing exponential vanishing or growth.
7.9.3 He Initialization
As proposed by He et al. (2015), this initialization technique is tailored to ReLU (Rectified Linear Unit) activation functions. ReLUs introduce the dying neuron problem where units get stuck outputting all 0s if they receive strong negative inputs initially. This slows and hinders training.
He overcomes this by sampling weights from a distribution with a variance set based only on the number of inputs per layer, disregarding the outputs. This keeps the incoming signals small enough to activate the ReLUs into their linear regime from the beginning, avoiding dead units. For a layer with 1024 inputs, the formula variance = 2/1024 = 0.002 keeps most weights concentrated closely around 0.
This specialized Initialization allows ReLU networks to converge efficiently right from the start. The choice between Xavier and He must match the intended network activation function.
Get your neural network off to a strong start with weight initialization! How you set those initial weights can make or break your model’s training. Think of it like tuning the instruments in an orchestra before the concert. In this Colab notebook, you’ll learn that the right initialization strategy can save time, improve model performance, and make your deep-learning journey much smoother.
![]()
Video 7.8 emphasizes the importance of deliberately selecting initial weight values over random choices.
7.10 System Bottlenecks
As introduced earlier, neural networks comprise linear operations (matrix multiplications) interleaved with element-wise nonlinear activation functions. The most computationally expensive portion of neural networks is the linear transformations, specifically the matrix multiplications between each layer. These linear layers map the activations from the previous layer to a higher dimensional space that serves as inputs to the next layer’s activation function.
7.10.1 Runtime Complexity of Matrix Multiplication
Layer Multiplications vs. Activations
The bulk of computation in neural networks arises from the matrix multiplications between layers. Consider a neural network layer with an input dimension of \(M\) = 500 and output dimension of \(N\) = 1000; the matrix multiplication requires \(O(N \cdot M) = O(1000 \cdot 500) = 500,000\) multiply-accumulate (MAC) operations between those layers.
Contrast this with the preceding layer, which had \(M\) = 300 inputs, requiring \(O(500 \cdot 300) = 150,000\) ops. As the dimensions of the layers increase, the computational requirements scale quadratically with the size of the layer dimensions. The total computations across \(L\) layers can be expressed as \(\sum_{l=1}^{L-1} O\big(N^{(l)} \cdot M^{(l-1)}\big)\), where the computation required for each layer is dependent on the product of the input and output dimensions of the matrices being multiplied.
Now, comparing the matrix multiplication to the activation function, which requires only \(O(N) = 1000\) element-wise nonlinearities for \(N = 1000\) outputs, we can see the linear transformations dominating the activations computationally.
These large matrix multiplications impact hardware choices, inference latency, and power constraints for real-world neural network applications. For example, a typical DNN layer may require 500,000 multiply-accumulates vs. only 1000 nonlinear activations, demonstrating a 500x increase in mathematical operations.
When training neural networks, we typically use mini-batch gradient descent, operating on small batches of data simultaneously. Considering a batch size of \(B\) training examples, the input to the matrix multiplication becomes a \(M \times B\) matrix, while the output is an \(N \times B\) matrix.
Mini-batch
In training neural networks, we need to repeatedly estimate the gradient of the loss function with respect to the network parameters (i.e., weights, and biases). This gradient indicates which direction the parameters should be updated in to minimize the loss. As introduced previously, we perform updates over a batch of data points every update, also known as stochastic gradient descent or mini-batch gradient descent.
The most straightforward approach is to estimate the gradient based on a single training example, compute the parameter update, lather, rinse, and repeat for the next example. However, this involves very small and frequent parameter updates that can be computationally inefficient and may need to be more accurate in terms of convergence due to the stochasticity of using just a single data point for a model update.
Instead, mini-batch gradient descent balances convergence stability and computational efficiency. Rather than computing the gradient on single examples, we estimate the gradient based on small “mini-batches” of data—usually between 8 and 256 examples in practice.
This provides a noisy but consistent gradient estimate that leads to more stable convergence. Additionally, the parameter update must only be performed once per mini-batch rather than once per example, reducing computational overhead.
By tuning the mini-batch size, we can control the tradeoff between the smoothness of the estimate (larger batches are generally better) and the frequency of updates (smaller batches allow more frequent updates). Mini-batch sizes are usually powers of 2, so they can efficiently leverage parallelism across GPU cores.
So, the total computation performs an \(N \times M\) by \(M \times B\) matrix multiplication, yielding \(O(N \cdot M \cdot B)\) floating point operations. As a numerical example, \(N=1000\) hidden units, \(M=500\) input units, and a batch size \(B=64\) equates to 1000 x 500 x 64 = 32 million multiply-accumulates per training iteration!
In contrast, the activation functions are applied element-wise to the \(N \times B\) output matrix, requiring only \(O(N \cdot B)\) computations. For \(N=1000\) and \(B=64\), that is just 64,000 nonlinearities - 500X less work than the matrix multiplication.
As we increase the batch size to fully leverage parallel hardware like GPUs, the discrepancy between matrix multiplication and activation function cost grows even larger. This reveals how optimizing the linear algebra operations offers tremendous efficiency gains.
Therefore, matrix multiplication is central in analyzing where and how neural networks spend computation. For example, matrix multiplications often account for over 90% of inference latency and training time in common convolutional and recurrent neural networks.
Optimizing Matrix Multiplication
Several techniques improve the efficiency of general dense/sparse matrix-matrix and matrix-vector operations to improve overall efficiency. Some key methods include:
- Leveraging optimized math libraries like cuBLAS for GPU acceleration
- Enabling lower precision formats like FP16 or INT8 where accuracy permits
- Employing Tensor Processing Units with hardware matrix multiplication
- Sparsity-aware computations and data storage formats to exploit zero parameters
- Approximating matrix multiplications with algorithms like Fast Fourier Transforms
- Model architecture design to reduce layer widths and activations
- Quantization, pruning, distillation, and other compression techniques
- Parallelization of computation across available hardware
- Caching/pre-computing results where possible to reduce redundant operations
The potential optimization techniques are vast, given the outsized portion of time models spend in matrix and vector math. Even incremental improvements speed up runtimes and lower energy usage. Finding new ways to improve these linear algebra primitives remains an active area of research aligned with the future demands of machine learning. We will discuss these in detail in the Optimizations and AI Acceleration chapters.
7.10.2 Compute vs. Memory Bottleneck
At this point, matrix-matrix multiplication is the core mathematical operation underpinning neural networks. Both training and inference for neural networks heavily use these matrix multiply operations. Analysis shows that over 90% of computational requirements in state-of-the-art neural networks arise from matrix multiplications. Consequently, the performance of matrix multiplication has an enormous influence on overall model training or inference time.
Training versus Inference
While training and inference rely heavily on matrix multiplication performance, their precise computational profiles differ. Specifically, neural network inference tends to be more compute-bound than training for an equivalent batch size. The key difference lies in the backpropagation pass, which is only required during training. Backpropagation involves a sequence of matrix multiply operations to calculate gradients with respect to activations across each network layer. Critically, though, no additional memory bandwidth is needed here—the inputs, outputs, and gradients are read/written from cache or registers.
As a result, training exhibits lower arithmetic intensities, with gradient calculations bounded by memory access instead of FLOPs (Floating Point Operations Per Second), a measure of computational performance that indicates how many floating-point calculations a system can perform per second. In contrast, the forward propagation dominates neural network inference, which corresponds to a series of matrix-matrix multiplies. With no memory-intensive gradient retrospecting, larger batch sizes readily push inference into being extremely compute-bound. The high measured arithmetic intensities exhibit this. Response times may be critical for some inference applications, forcing the application provider to use a smaller batch size to meet these response-time requirements, thereby reducing hardware efficiency; hence, inferences may see lower hardware utilization.
The implications are that hardware provisioning and bandwidth vs. FLOP tradeoffs differ depending on whether a system targets training or inference. High-throughput, low-latency servers for inference should emphasize computational power instead of memory, while training clusters require a more balanced architecture.
However, matrix multiplication exhibits an interesting tension - the underlying hardware’s memory bandwidth or arithmetic throughput capabilities can bind it. The system’s ability to fetch and supply matrix data versus its ability to perform computational operations determines this direction.
This phenomenon has profound impacts; hardware must be designed judiciously, and software optimizations must be considered. Optimizing and balancing compute versus memory to alleviate this underlying matrix multiplication bottleneck is crucial for efficient model training and deployment.
Finally, batch size may impact convergence rates during neural network training, another important consideration. For example, there are generally diminishing returns in benefits to convergence with extremely large batch sizes (i.e.,> 16384). In contrast, extremely large batch sizes may be increasingly beneficial from a hardware/arithmetic intensity perspective; using such large batches may not translate to faster convergence vs wall-clock time due to their diminishing benefits to convergence. These tradeoffs are part of the design decisions core to systems for the machine-learning type of research.
Batch Size
The batch size used during neural network training and inference significantly impacts whether matrix multiplication poses more of a computational or memory bottleneck. Concretely, the batch size refers to the number of samples propagated through the network together in one forward/backward pass. Matrix multiplication equates to larger matrix sizes.
Specifically, let’s look at the arithmetic intensity of matrix multiplication during neural network training. This measures the ratio between computational operations and memory transfers. The matrix multiply of two matrices of size \(N \times M\) and \(M \times B\) requires \(N \times M \times B\) multiply-accumulate operations, but only transfers of \(N \times M + M \times B\) matrix elements.
As we increase the batch size \(B\), the number of arithmetic operations grows faster than the memory transfers. For example, with a batch size of 1, we need \(N \times M\) operations and \(N + M\) transfers, giving an arithmetic intensity ratio of around \(\frac{N \times M}{N+M}\). But with a large batch size of 128, the intensity ratio becomes \(\frac{128 \times N \times M}{N \times M + M \times 128} \approx 128\). Using a larger batch size shifts the overall computation from memory-bounded to more compute-bounded. AI training uses large batch sizes and is generally limited by peak arithmetic computational performance, i.e., Application 3 in Figure 7.7.
Therefore, batched matrix multiplication is far more computationally intensive than memory access bound. This has implications for hardware design and software optimizations, which we will cover next. The key insight is that we can significantly alter the computational profile and bottlenecks posed by neural network training and inference by tuning the batch size.
Hardware Characteristics
Modern hardware like CPUs and GPUs is highly optimized for computational throughput rather than memory bandwidth. For example, high-end H100 Tensor Core GPUs can deliver over 60 TFLOPS of double-precision performance but only provide up to 3 TB/s of memory bandwidth. This means there is almost a 20x imbalance between arithmetic units and memory access; consequently, for hardware like GPU accelerators, neural network training workloads must be made as computationally intensive as possible to use the available resources fully.
This further motivates the need for using large batch sizes during training. When using a small batch, the matrix multiplication is bounded by memory bandwidth, underutilizing the abundant compute resources. However, we can shift the bottleneck towards computation and attain much higher arithmetic intensity with sufficiently large batches. For instance, batches of 256 or 512 samples may be needed to saturate a high-end GPU. The downside is that larger batches provide less frequent parameter updates, which can impact convergence. Still, the parameter serves as an important tuning knob to balance memory vs compute limitations.
Therefore, given the imbalanced compute-memory architectures of modern hardware, employing large batch sizes is essential to alleviate bottlenecks and maximize throughput. As mentioned, the subsequent software and algorithms also need to accommodate such batch sizes since larger batch sizes may have diminishing returns toward the network’s convergence. Using very small batch sizes may lead to suboptimal hardware utilization, ultimately limiting training efficiency. Scaling up to large batch sizes is a research topic explored in various works that aim to do large-scale training (You et al. 2017).
Model Architectures
The underlying neural network architecture also affects whether matrix multiplication poses more of a computational or memory bottleneck during execution. Transformers and MLPs are much more compute-bound than CNN convolutional neural networks. This stems from the types of matrix multiplication operations involved in each model. Transformers rely on self-attention, multiplying large activation matrices by massive parameter matrices to relate elements. MLPs stack fully connected layers, also requiring large matrix multiplies.
In contrast, the convolutional layers in CNNs have a sliding window that reuses activations and parameters across the input, which means fewer unique matrix operations are needed. However, the convolutions require repeatedly accessing small input parts and moving partial sums to populate each window. Even though the arithmetic operations in convolutions are intense, this data movement and buffer manipulation impose huge memory access overheads. CNNs comprise several layered stages, so intermediate outputs must frequently materialize in memory.
As a result, CNN training tends to be more memory bandwidth bound relative to arithmetic bound compared to Transformers and MLPs. Therefore, the matrix multiplication profile, and in turn, the bottleneck posed, varies significantly based on model choice. Hardware and systems need to be designed with appropriate compute-memory bandwidth balance depending on target model deployment. Models relying more on attention and MLP layers require higher arithmetic throughput compared to CNNs, which necessitates high memory bandwidth.
7.11 Training Parallelization
Training neural networks entails intensive computational and memory demands. The backpropagation algorithm for calculating gradients and updating weights consists of repeated matrix multiplications and arithmetic operations over the entire dataset. For example, one pass of backpropagation scales in time complexity with \(O(num\_parameters \times batch\_size \times sequence\_length)\).
The computational requirements grow rapidly as model size increases in parameters and layers. Moreover, the algorithm requires storing activation outputs and model parameters for the backward pass, which grows with model size.
Larger models cannot fit and train on a single accelerator device like a GPU, and the memory footprint becomes prohibitive. Therefore, we need to parallelize model training across multiple devices to provide sufficient compute and memory to train state-of-the-art neural networks.
As shown in Figure 7.8, the two main approaches are data parallelism, which replicates the model across devices while splitting the input data batch-wise, and model parallelism, which partitions the model architecture itself across different devices. By training in parallel, we can leverage greater aggregate compute and memory resources to overcome system limitations and accelerate deep learning workloads.
7.11.1 Data Parallel
Data parallelization is a common approach to parallelize machine learning training across multiple processing units, such as GPUs or distributed computing resources. The training dataset is divided into batches in data parallelism, and a separate processing unit processes each batch. The model parameters are then updated based on the gradients computed from the processing of each batch. Here’s a step-by-step description of data parallelization for ML training:
Dividing the Dataset: The training dataset is divided into smaller batches, each containing a subset of the training examples.
Replicating the Model: The neural network model is replicated across all processing units, and each processing unit has its copy of the model.
Parallel Computation: Each processing unit takes a different batch and independently computes the forward and backward passes. During the forward pass, the model makes predictions on the input data. The loss function determines gradients for the model parameters during the backward pass.
Gradient Aggregation: After processing their respective batches, the gradients from each processing unit are aggregated. Common aggregation methods include summation or averaging of the gradients.
Parameter Update: The aggregated gradients update the model parameters. The update can be performed using optimization algorithms like SGD or variants like Adam.
Synchronization: After the update, all processing units synchronize their model parameters, ensuring that each has the latest version of the model.
The prior steps are repeated for several iterations or until convergence.
Let’s take a specific example. We have 256 batch sizes and 8 GPUs; each GPU will get a micro-batch of 32 samples. Their forward and backward passes compute losses and gradients only based on the local 32 samples. The gradients get aggregated across devices with a parameter server or collective communications library to get the effective gradient for the global batch. Weight updates happen independently on each GPU according to these gradients. After a configured number of iterations, updated weights synchronize and equalize across devices before continuing to the next iterations.
Data parallelism is effective when the model is large, and the dataset is substantial, as it allows for parallel processing of different parts of the data. It is widely used in deep learning frameworks and libraries that support distributed training, such as TensorFlow and PyTorch. However, to ensure efficient parallelization, care must be taken to handle issues like communication overhead, load balancing, and synchronization.
7.11.2 Model Parallelism
Model parallelism refers to distributing the neural network model across multiple devices rather than replicating the full model like data parallelism. This is particularly useful when a model is too large to fit into the memory of a single GPU or accelerator device. While this might not be specifically applicable for embedded or TinyML use cases as most models are relatively small(er), it is still useful to know.
In model parallel training, different parts or layers of the model are assigned to separate devices. The input activations and intermediate outputs get partitioned and passed between these devices during the forward and backward passes to coordinate gradient computations across model partitions.
The memory footprint and computational operations are distributed by splitting the model architecture across multiple devices instead of concentrating on one. This enables training very large models with billions of parameters that otherwise exceed the capacity of a single device. There are several main ways in which we can do partitioning:
Layer-wise parallelism: Consecutive layers are distributed onto different devices. For example, device 1 contains layers 1-3; device 2 contains layers 4-6. The output activations from layer 3 would be transferred to device 2 to start the next layers for the forward pass computations.
Filter-wise parallelism: In convolutional layers, output filters can be split among devices. Each device computes activation outputs for a subset of filters, which get concatenated before propagating further.
Spatial parallelism: The input images get divided spatially, so each device processes over a certain region like the top-left quarter of images. The output regions then combine to form the full output.
Additionally, hybrid combinations can split the model layer-wise and data batch-wise. The appropriate type of model parallelism depends on the specific neural architecture constraints and hardware setup. Optimizing the partitioning and communication for the model topology is key to minimizing overhead.
However, as the model parts run on physically separate devices, they must communicate and synchronize their parameters during each training step. The backward pass must ensure gradient updates propagate accurately across the model partitions. Hence, coordination and high-speed interconnecting between devices are crucial for optimizing the performance of model parallel training. Careful partitioning and communication protocols are required to minimize transfer overhead.
7.11.3 Comparison
To summarize, Table 7.5 demonstrates some of the key characteristics for comparing data parallelism and model parallelism.
| Characteristic | Data Parallelism | Model Parallelism |
|---|---|---|
| Definition | Distribute data across devices with replicas | Distribute model across devices |
| Objective | Accelerate training through compute scaling | Enable larger model training |
| Scaling Method | Scale devices/workers | Scale model size |
| Main Constraint | Model size per device | Device coordination overhead |
| Hardware Requirements | Multiple GPU/TPUs | Often specialized interconnect |
| Primary Challenge | Parameter synchronization | Complex partitioning and communication |
| Types | N/A | Layer-wise, filter-wise, spatial |
| Code Complexity | Minimal changes | More significant model surgery |
| Popular Libraries | Horovod, PyTorch Distributed | Mesh TensorFlow |
7.12 Conclusion
In this chapter, we have covered the core foundations that enable effective training of artificial intelligence models. We explored the mathematical concepts like loss functions, backpropagation, and gradient descent that make neural network optimization possible. We also discussed practical techniques around leveraging training data, regularization, hyperparameter tuning, weight initialization, and distributed parallelization strategies that improve convergence, generalization, and scalability.
These methodologies form the bedrock through which the success of deep learning has been attained over the past decade. Mastering these fundamentals equips practitioners to architect systems and refine models tailored to their problem context. However, as models and datasets grow exponentially, training systems must optimize across metrics like time, cost, and carbon footprint. Hardware scaling through warehouse scales enables massive computational throughput - but optimizations around efficiency and specialization will be key. Software techniques like compression and sparsity exploitation can increase hardware gains. We will discuss several of these in the coming chapters.
Overall, the fundamentals covered in this chapter equip practitioners to build, refine, and deploy models. However, interdisciplinary skills spanning theory, systems, and hardware will differentiate experts who can lift AI to the next level sustainably and responsibly that society requires. Understanding efficiency alongside accuracy constitutes the balanced engineering approach needed to train intelligent systems that integrate smoothly across many real-world contexts.
7.13 Resources
Here is a curated list of resources to support students and instructors in their learning and teaching journeys. We are continuously working on expanding this collection and will be adding new exercises soon.
These slides are a valuable tool for instructors to deliver lectures and for students to review the material at their own pace. We encourage students and instructors to leverage these slides to improve their understanding and facilitate effective knowledge transfer.
Continuous Training:
To reinforce the concepts covered in this chapter, we have curated a set of exercises that challenge students to apply their knowledge and deepen their understanding.
In addition to exercises, we offer a series of hands-on labs allowing students to gain practical experience with embedded AI technologies. These labs provide step-by-step guidance, enabling students to develop their skills in a structured and supportive environment. We are excited to announce that new labs will be available soon, further enriching the learning experience.
- Coming soon.